昨天,我們成功將 OTLP 資料轉換成 Parquet 格式。今天,讓我們接續昨天的實驗,來拆解 Parquet 內部的結構吧。
由於 Parquet 是二進制格式,不像 CSV、JSON 那樣是純文字格式,無法直接用文字編輯器或 cat、less 等指令來查看內容。因此需要專門的工具來做查看,查見的工具包含 各種語言開發的CLI、pandas、Spark 等工具。
這次我們使用 MacOS 上的套件parquet-cli 來觀察 Parquet 的內部架構。可以使用 Homebrew 進行本地安裝:
$ brew install parquet-cli
如果是使用非 MacOS環境,則可以參考以下 Repo 進行安裝:parquet-cli
安裝完畢後可以簡單查看如何使用並測試:
$ parquet --help
查看本地的 Parquet file 結構
$ parquet head -n 10 metrics.parquet
編按:由於本次實驗的主要目的為觀察 Parquet 檔案架構,因此在 OTLP 資料上,有些欄位並沒有被轉換進 Parquet 檔案中,避免版面過於冗長。不過,這也代表當我們要把 OTLP 格式的資料轉為 Parquet 時,是可以自行決定哪些有價值的資料要進行轉換的
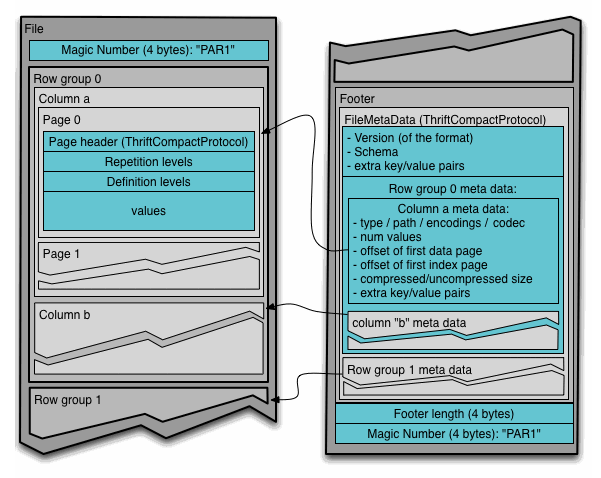
安裝完工具之後,就可以開始正文了。可以看到上方圖片就是整個 Parquet file 的架構。可以看到大致上的分層架構可以收斂成:
Magic Number "PAR1" (4 bytes)
├── Row Group 0
│ ├── Column a chunk 0
│ │ ├── Page 0 (with header)
│ │ └── Page 1
│ └── Column b chunk 0
├── Row Group 1
│ ├── Column a chunk 1
│ │ ├── ...
│ │ └── ...
│ └── Column b chunk 1
└── Footer (Metadata)
└── Magic Number "PAR1" (4 bytes)
在這邊,我們的觀察可以分成幾個部分,分別是 Row Groups、Column Chunks、Pages,最後則是 metadata 與 schema。
Row Group 是 Parquet 檔案中資料組織的基本單位,採用「水平分割」的概念將資料分組。每個 Row Group 包含一定數量的資料列,並按欄位重新組織儲存。
這種設計的好處讓我們能以 Row Group 為單位進行平行運算,這是因為每個 Row Group 都有所有欄位的一部分,使得可以分別進行運算後,再將各個 Row Group 算好的結果合併即可。
透過 parquet 可以查看 Row Group 的詳細資訊:
$ parquet meta metrics.parquet
File path: metrics.parquet
Created by: parquet-cpp-arrow version 17.0.0
Schema:
message schema {
optional int64 timestamp (TIMESTAMP(NANOS,false));
optional binary metric_name (STRING);
optional double value;
optional binary service_name (STRING);
optional binary cpu (STRING);
optional binary device (STRING);
optional binary fstype (STRING);
optional binary mountpoint (STRING);
optional binary mode (STRING);
}
Row group 0: count: 500 12.04 B records start: 4 total(compressed): 5.881 kB total(uncompressed):9.451 kB
Row group 1: count: 500 9.89 B records start: 6789 total(compressed): 4.830 kB total(uncompressed):8.037 kB
Row group 2: count: 322 10.93 B records start: 12567 total(compressed): 3.436 kB total(uncompressed):4.910 kB
(下略)
可以看到 metrics.parquet 檔案中共有三個 Row Groups。每個 Row Group 數量共 500 筆。這個數量是怎麼決定的呢?還記得在上一篇的 HTTP Server 中,有一段邏輯是將 JSON 轉換成 Parquet 格式:
df.to_parquet(filename, compression='snappy', index=False)
我們可以在這個函式添加參數,指定一個 Row Group 要有幾筆資料:
df.to_parquet(filename, compression='snappy', index=False, row_group_size=500) # 一個 row group 有 500 筆資料
若不特別設定,pandas 的預設值是 1,000,000 筆。由於我們的資料只有 1322 筆,如果不設定 row_group_size,所有資料都會放在同一個 Row Group 中。透過設定 row_group_size=500,我們可以看到資料被分割成 3 個 Row Group。
在 Row Group 內部,每個欄位的資料會被組織成 Column Chunk。Column Chunk 是某個特定欄位在該 Row Group 中的所有資料,這些資料在檔案中是連續儲存的。
根據 Apache Parquet 官方文件,Column Chunk 是由多個 Pages 依序組成的:
Column Chunk (timestamp)
├── Dictionary Page (可選,如果有的話必須是第一個)
├── Data Page 0
├── Data Page 1
└── Data Page N
我們來實際觀察剛才 parquet meta 輸出中的 Column Chunk 資訊:
Row group 0: count: 500 12.04 B records start: 4 total(compressed): 5.881 kB total(uncompressed):9.451 kB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
metric_name BINARY S _ R 500 4.30 B 0 "go_goroutines" / "up"
這表示 Row Group 0 中的 metric_name Column Chunk:
BINARY 型別儲存字串資料S _ R (SNAPPY 壓縮 + RLE 編碼)Column Chunk 的設計讓 Parquet 能夠針對每個欄位的特性進行最佳化,這就是欄式儲存的核心優勢。
前面說到 Parquet 可以做到良好的資料壓縮,而不管是資料壓縮或者編碼,都是以 Pages 作為單位來進行。也就是說,不同的 Pages 可以擁有自己的壓縮與編碼方法。
Parquet 總共支援以下的壓縮方法:
我們也可以透過 CLI 來獲取 pages 的資訊:
$ parquet pages metrics.parquet
這個指令會顯示每個 Column Chunk 內的 Pages 詳細資訊,包括每個 Page 的壓縮效果、編碼方式和資料分布。
我們先來看其中一個 timestamp 欄位:
Column: timestamp
--------------------------------------------------------------------------------
page type enc count avg size size rows nulls min / max
0-D dict S _ 1 8.00 B 8 B
0-1 data S R 500 0.02 B 11 B 0 "2025-09-30T23:02:55.12800..." / "2025-09-30T23:02:55.12800..."
1-D dict S _ 1 8.00 B 8 B
1-1 data S R 500 0.02 B 11 B 0 "2025-09-30T23:02:55.12800..." / "2025-09-30T23:02:55.12800..."
2-D dict S _ 1 8.00 B 8 B
2-1 data S R 322 0.03 B 11 B 0 "2025-09-30T23:02:55.12800..." / "2025-09-30T23:02:55.12800..."
從輸出可以觀察到幾個重點:
0-D, 1-D, 2-D:Dictionary Pages(字典頁)0-1, 1-1, 2-1:Data Pages(資料頁)S _:SNAPPY 壓縮,無額外編碼S R:SNAPPY 壓縮 + RLE (Run-Length Encoding) 編碼以 Row Group 0 的 timestamp 為例:
這顯示出字典編碼配合壓縮的強大效果,將原本需要數千 bytes 的時間戳記資料壓縮到只需 11 bytes。
我們再來看另一個欄位 metric_name 的 Pages 結構:
Column: metric_name
--------------------------------------------------------------------------------
page type enc count avg size size rows nulls min / max
0-D dict S _ 7 17.71 B 124 B
0-1 data S R 500 0.66 B 330 B 0 "go_goroutines" / "up"
1-D dict S _ 7 17.71 B 124 B
1-1 data S R 500 0.66 B 330 B 0 "go_goroutines" / "up"
2-D dict S _ 7 17.71 B 124 B
2-1 data S R 322 1.02 B 330 B 0 "go_goroutines" / "up"
可以看到:
這就是為什麼 Parquet 特別適合儲存具有重複值的欄位,透過字典編碼可以大幅減少儲存空間。
今天透過 parquet-cli 工具,讓我們可以實際觀察 Parquet file 裡面的架構,更了解內部是如何實現資料的高效儲存。透過實際的 OTLP 資料轉換範例,我們看到了 Parquet 如何運用 Row Groups、Column Chunks、Pages 的分層設計,結合字典編碼和壓縮演算法,將資料壓縮到極小的空間。
從實驗結果可以看到,500 筆時間戳記資料只需要 11 bytes,這種壓縮效果在處理大量可觀測性資料時特別有價值。明天,我們將繼續探討如何在 Data Lakehouse 架構中查詢和分析這些高效儲存的資料。
Amo Chen - Apache Parquet 深度介紹與說明
Apache Parquet - Column Chunks
posulliv.github.io - Using the Parquet CLI

