目前為止,我們已經深入了解 Parquet 的欄式儲存設計,看到它如何透過分層架構和壓縮技術來高效儲存資料。但是,資料儲存只是第一步,真正的價值在於如何快速查詢和分析這些資料。今天,我們要來探討 OLAP 查詢引擎的核心概念,以及為什麼它特別適合處理 columnar data。
OLAP 是一種可以從多個角度分析業務資料的技術。我們可以從它的名字來分析它能做到哪些事:
OLAP 時常被拿來與 OLTP 來進行比較與選型。為了能更了解 OLAP 的優勢,以下讓我們直接來比較兩者有哪些技術上的差異。
所有資料庫管理系統都可以分為兩大類:OLAP(Online Analytical Processing)和 OLTP(Online Transactional Processing)。前者專注於建立報表,每次基於大量歷史資料進行分析,但執行頻率較低;後者通常處理持續的交易流,不斷修改資料的當前狀態。
簡單來說,OLAP 通常用於製作歷史資料的分析與報告,因為如此,它不太需要去處理、保持資料的一致性,它關注的是如何能透過 query 去快速地得到資料聚合後的結果並統合成資料洞察。
不過,在實務上,OLAP 和 OLTP 並非二元對立的分類,而更像是一個光譜。大多數真實系統通常會專注於其中一種,但也會提供一些解決方案或變通方法來處理另一種工作負載。這種情況常常迫使企業需要運行多個整合的儲存系統,增加了維護成本。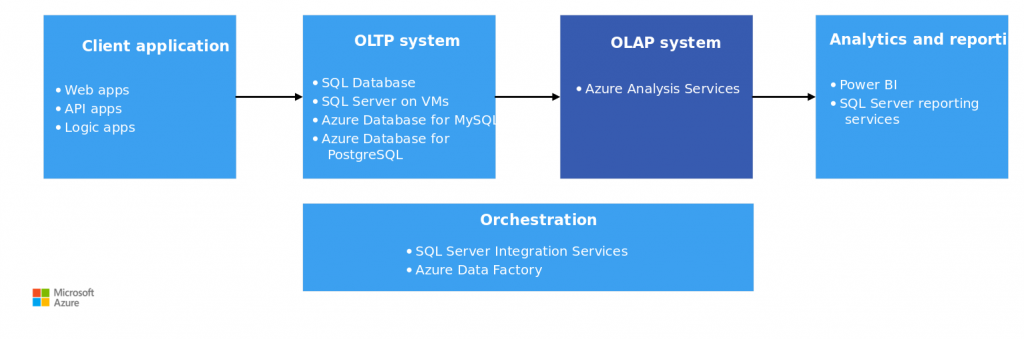
圖中架構結合了 OLAP 與 OLTP 兩種資料庫。OLTP負責儲存商務交易和紀錄,而 OLAP 資料庫則保存所有歷史紀錄,以利進行後續的時間序列分析
因此,近年來的趨勢是朝向 HTAP(Hybrid Transactional/Analytical Processing)發展,讓單一資料庫管理系統能同時處理這兩種工作負載。即使是最初設計為純 OLAP 或純 OLTP 的系統,也逐漸加入對另一種工作負載的支援以保持競爭力。
然而,OLAP 和 OLTP 系統之間仍存在一個根本的取捨:
這就是為什麼 Parquet 這類欄式儲存格式特別適合 OLAP 場景。當我們儲存了夠寬的結構化資料,它讓我們能夠只讀取需要的欄位,在高基數、高維度的資料中,也能大幅提升資料的查詢效率。
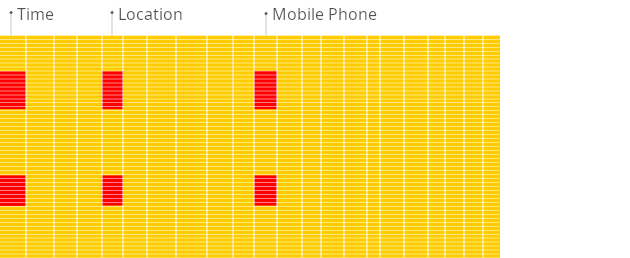
我們在前面的文章中已經深入探討過 Parquet 的欄式儲存設計。OLAP 引擎利用欄式儲存的優勢:
分區是將大型資料集按照某個維度進行物理分割的技術。在可觀測性場景中,最常見的分區維度是時間,因為大多數查詢都會指定時間範圍。
以時間分區為例,資料會被組織成這樣的目錄結構:
data/
├── date=2025-09-01/
│ └── metrics.parquet
├── date=2025-09-02/
│ └── metrics.parquet
└── date=2025-09-03/
└── metrics.parquet
這樣分區的設計有幾項優勢:
分區修剪 (Partition Pruning)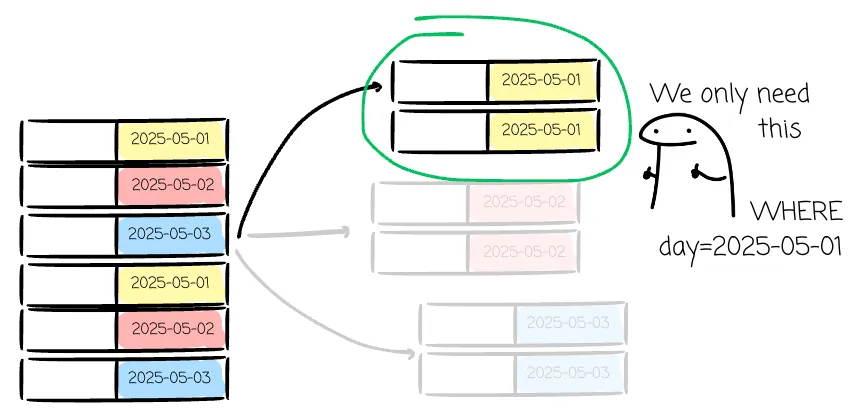
date=2025-05-01/ 這個分區平行處理
資料管理
現代 OLAP 資料庫(如 ClickHouse、Druid、DuckDB)使用多種索引技術來加速查詢:
WHERE timestamp > '2025-09-02' 時,可以跳過所有最大值小於該時間的資料塊與傳統 OLAP Cube 預先計算所有維度組合不同,現代 OLAP 資料庫不需要預先建立聚合表,而是透過這些索引技術在查詢時快速過濾和定位資料,提供更高的靈活性。
今天我們深入探討了 OLAP 查詢引擎的核心技術,從技術角度理解了為什麼 OLAP 特別適合處理可觀測性資料。
回顧這幾天的內容,從 Apache Iceberg 的 table format、Parquet 的欄式儲存設計,到今天的 OLAP 查詢引擎,我們逐步建構了對 Data Lakehouse 架構的理解——從資料的組織、儲存到查詢,這些技術環環相扣,共同支撐起海量可觀測性資料的高效分析。
Hubert Dulay - What is Hybrid Transactional & Analytical Processing (HTAP)
Vu Trinh - Partitioning and Clustering


 iThome鐵人賽
iThome鐵人賽