
大型語言模型(LLM)的浪潮正以前所未有的速度席捲各行各業。從 OpenAI 的 GPT 系列、Anthropic 的 Claude,到 Google 的 Gemini,企業正積極將這些強大的 AI 能力整合至現有工作流程中。然而,當我們從單純的技術嚐鮮,邁向真正可規模化、穩定可靠的生產環境時,一個嚴峻的現實浮出水面:直接串接各家 LLM 的 API 是一場充滿挑戰的硬仗。
API 格式的破碎化、服務的不穩定、成本的失控、以及安全治理的缺失,都成為了阻礙 AI 應用從「實驗品」走向「產品級」的巨大瓶頸。為了解決這些問題,一個新的架構層 **AI Gateway(或稱 AI Gateway)**應運而生。它不僅是個實用的工具,更是生產級別 AI 應用的基石。
早期只接一個模型,看起來很單純。但一旦為了成本最佳化或功能互補而導入多個模型,工程複雜度、治理成本與風險會一口氣放大。以下是直接整合各家 LLM API 常見的四大挑戰與其影響重點。
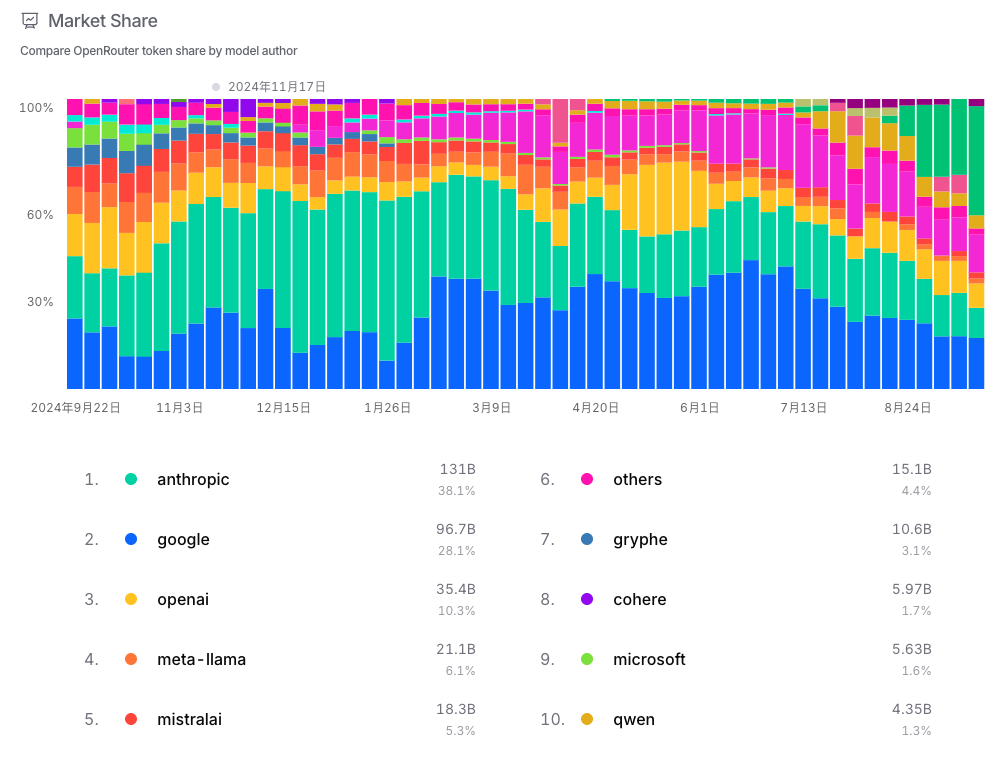
每個 LLM 供應商都有自己獨特的 API 介面。參數名稱、配置範圍和支援的功能各不相同。例如,同樣是設定回覆長度,OpenAI 使用 max_tokens,Gemini 可能是 maxOutputTokens,而 Claude 則是 max_tokens_to_sample。[1] 這意味著工程團隊必須為每個模型編寫和維護特定的處理邏輯,不僅重複勞動,更限制了模型之間切換的靈活性。
痛點:
儘管有服務等級協定(SLA),但 LLM 服務仍會因基礎設施限制、高需求或上游依賴問題而出現性能下降甚至停機。應用程式若直接綁定單一供應商,一旦該服務出問題,便會面臨系統性故障的風險。此外,模型的推論延遲並非固定不變,它會因地理區域、模型版本和請求量而波動,這對於需要即時反應的應用是一大致命傷。
| 提供者 | SLA 保證 (Uptime) | 細節與條件 |
|---|---|---|
| OpenAI | 99.9% (企業) | 僅適用於企業客戶的 Scale Tier 方案,提供優先計算資源。標準 API 無公開 SLA,需談判。 |
| Azure OpenAI | 99.9% | 適用於所有資源,保證每月至少 99.9% 可用。若低於此水平,提供服務信用。 |
| Amazon Bedrock | 99.9% | 每個 AWS 區域每月至少 99.9%。若低於 99.9% 但 >=99.0%,信用 10%;更低則更高信用。不適用於客戶因素或模型崩潰等排除情況。 |
| Google Vertex AI | >=99.9% (大多數服務) | 訓練、部署、批次預測等 >=99.9%;自訂模型線上預測 (2+ 節點) >=99.5%。 |
| Anthropic | 99.5% (Priority Tier) | 優先方案目標 99.5%。標準方案無公開 SLA,可談判至 99.9% 或更高。 |
| Cohere | 未公開 | 無明確公開 SLA 資訊,通常需企業談判類似 99.9% 水平。 |
常見的保證水平取決於提供者和方案類型,大部分通常的保證是三個九( 99.9%),這意味著每月允許約 43 分鐘的 downtime,其實在雲端基礎設施中並不算是非常可靠。
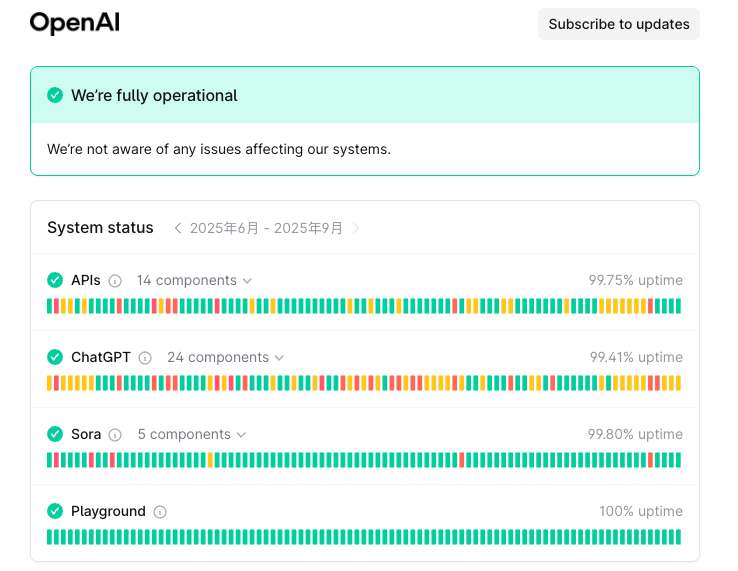
從圖中可以看出,即便是最成熟、最先進的 LLM 供應商 OpenAI,也無法始終維持高水準的 SLA。這意味著凡是依賴單一供應商的產品,其 SLA 都會被嚴重牽動,且缺乏容錯與備援空間。
痛點:
LLM 的使用成本是個複雜的議題,計費方式通常涉及輸入與輸出的 Token 數量、模型類型等。當企業內多個團隊、多個應用程式都在使用 LLM 時,分散在各個平台(如 Azure Monitor, AWS CloudWatch, OpenAI Dashboards)的帳單數據,使得跨團隊、跨模型的成本歸因和預算管理變得極其困難。缺乏統一的成本監控,將導致預算超支、資源浪費,難以進行有效的財務規劃。
痛點:
在沒有統一閘道的情況下,API 金鑰管理容易變得混亂,增加了金鑰洩漏的風險。更重要的是,安全策略(如個人可識別資訊 PII 的過濾、品牌聲譽保護、防止提示注入攻擊等)往往在各個應用中被不一致地實施。這種缺乏集中式語義驗證與稽核的做法,使企業面臨:
因此,缺乏集中式的 AI Gateway,不只是工程效率問題,更是企業級安全與合規上的重大隱患。
痛點:
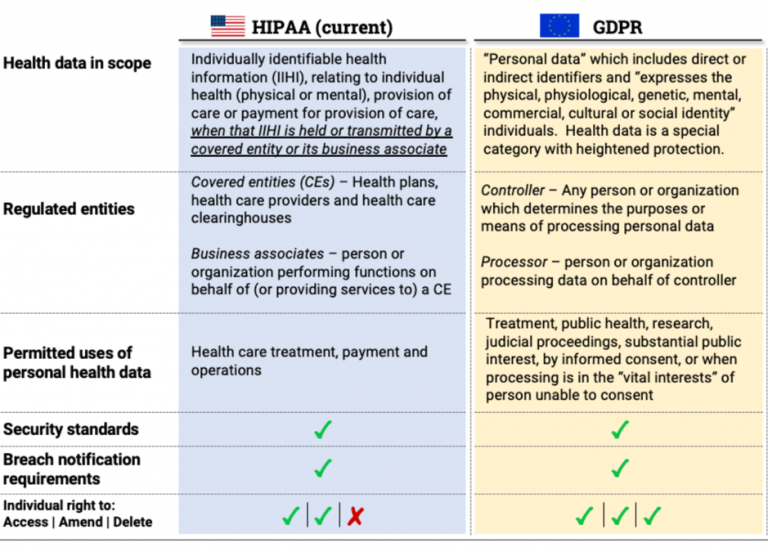
https://itirra.com/blog/the-main-differences-between-gdpr-and-hipaa/
為了解決上述挑戰,AI Gateway 作為一個智慧中介層,被置於 AI 應用和眾多 LLM 服務之間。但它絕不僅僅是一個簡單的請求轉發工具。我們可以將它理解為整個企業 AI 應用的「智慧交通總管」或「中央控制平面」。
想像一下,您正在管理一個大型客服部門,並希望導入三種不同的 LLM(模型A、B、C)來分別處理:常見問題回答、複雜情感分析、以及產品建議。
https://neuraltrust.ai/blog/ai-gateways-vs-api-gateways-differences
這個「智慧總管」的核心價值在於:它接收來自應用程式的請求,理解其「意圖」,經過一系列的處理、優化和安全檢查,然後將其智慧地轉發給最合適的 LLM,最後將結果安全、一致地返回給應用程式。
使用 AI Gateway 來統一各種 LLM Provider 端口是最基礎也最重要的功能。目前不同 LLM 供應商的 API 在請求結構、參數命名上依然還有很大的差異。
# OpenAI
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello!"}],
max_tokens=100
)
# Anthropic
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=100,
messages=[{"role": "user", "content": "Hello!"}]
)
即使是簡單的請求,其程式碼結構和參數也略有不同。這種差異迫使開發者為每個模型編寫特定的適配器(Adapter),增加了維護成本。
# 透過 Gateway 呼叫不同模型
# 呼叫 GPT-4o
response = gateway_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello!"}]
)
# 只需改變 model 參數,即可無縫切換到 Claude
response = gateway_client.chat.completions.create(
model="claude-3-opus",
messages=[{"role": "user", "content": "Hello!"}]
)
AI Gateway 提供一個單一的、標準化的 API 端點,通常完全相容業界主流的 OpenAI API 格式。開發者只需編寫一次程式碼,就可以透過 Gateway 呼叫後端數十種模型。這種方式徹底解除了 Vendor Lock-in 的枷鎖,賦予了企業在不同模型間自由切換、擇優使用的能力。
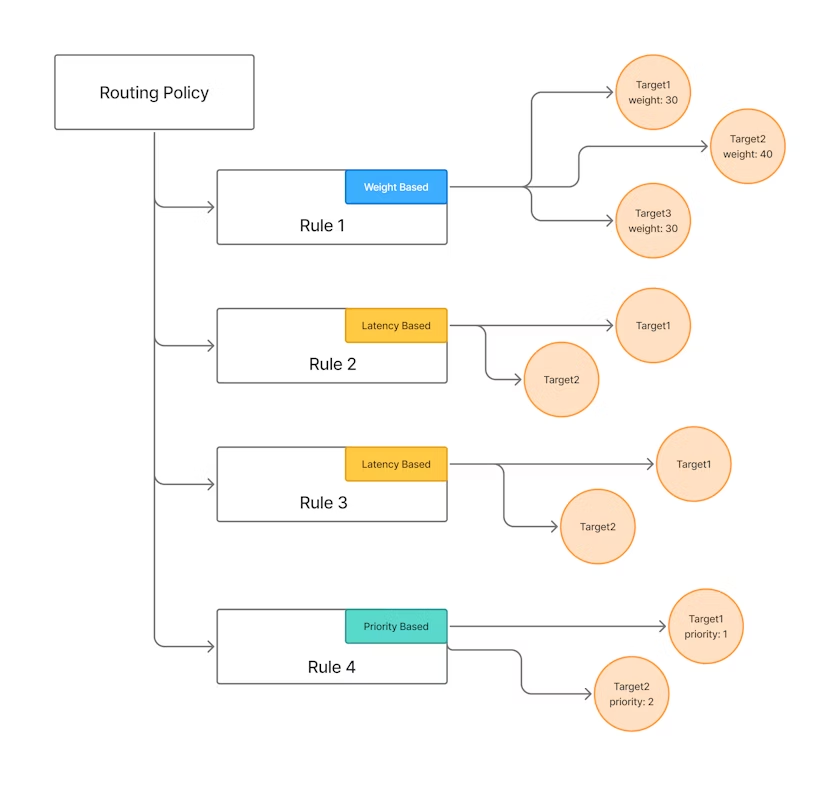
當企業內數十個團隊都在使用 LLM 時,如果缺乏集中治理,很快就會陷入混亂。
當企業內數十個團隊都在使用 LLM 時,如果缺乏集中治理,很快就會陷入混亂。
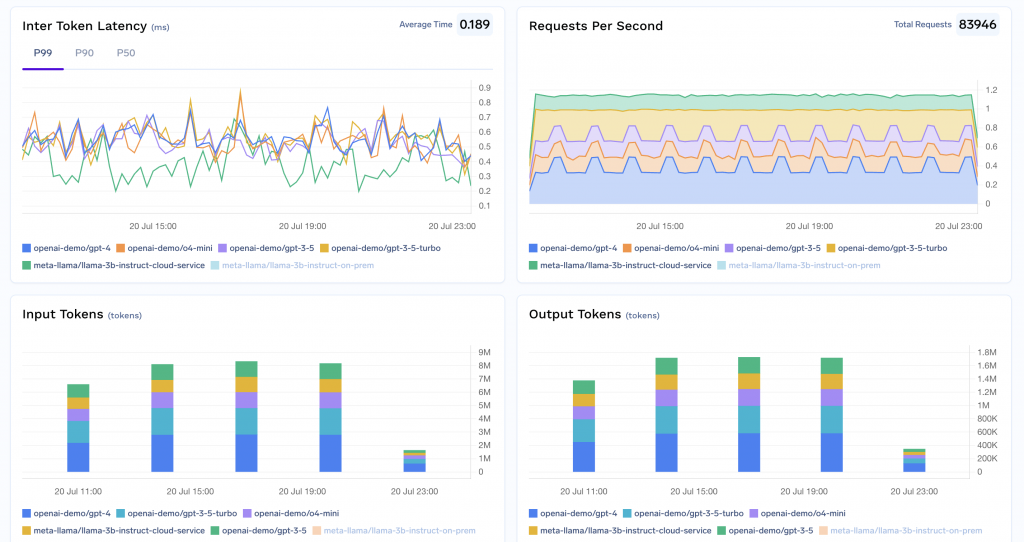
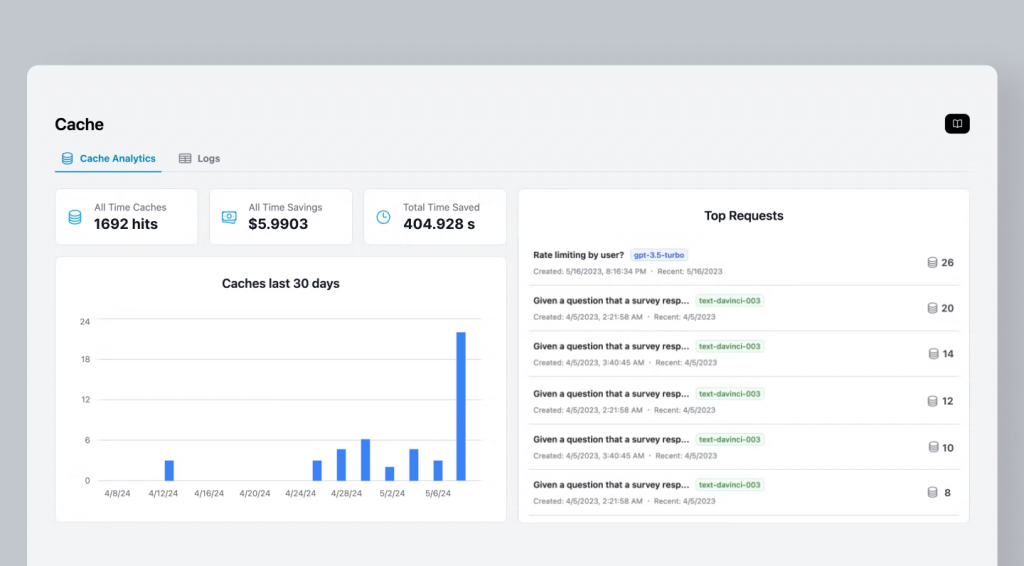
AI Gateway 可以透過多層次的快取機制大幅降低延遲與成本。傳統快取通常只針對完全相同的請求字串,而 AI Gateway 可以結合不同層次的快取策略,提供更聰明的優化。
常見快取方式:
效益:
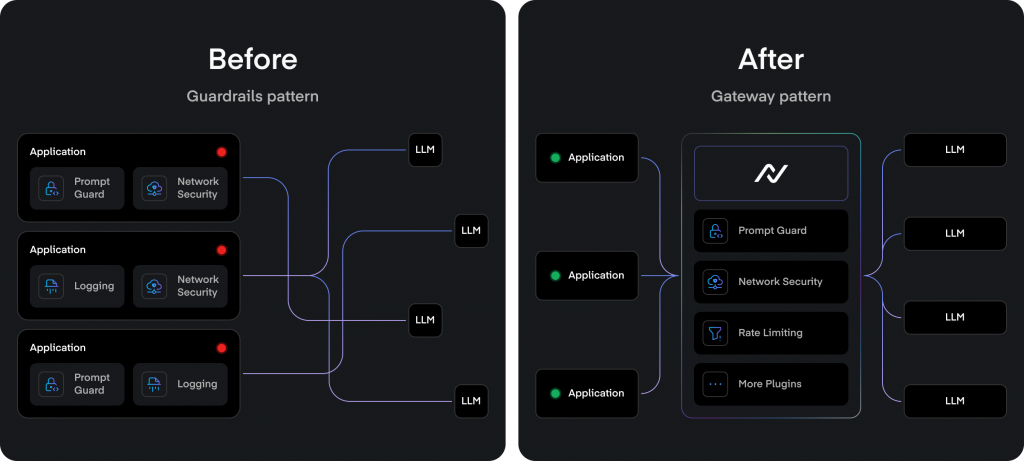
AI Gateway 是實施安全策略的最佳檢查點,它就像一個「語義防火牆」,在數據流入和流出時進行深度內容檢查。
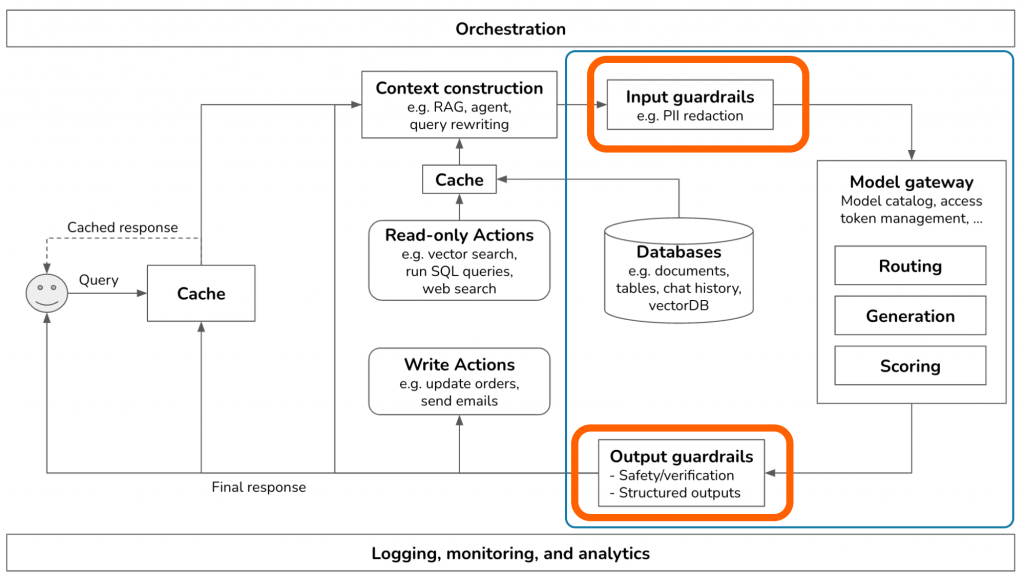
https://portkey.ai/blog/bringing-guardrails-on-the-gateway/
隨著企業對 LLM 的依賴日益加深,一個強大、可靠的基礎設施變得不可或缺。AI Gateway 不再是一個「可有可無」的選項,而是支撐起整個 AI 應用體系的「營運層」和「治理層」。它系統性地解決了多模型管理帶來的混亂、成本和安全挑戰,讓開發團隊能重新專注於創造真正有價值的 AI 功能與體驗。
References:


 iThome鐵人賽
iThome鐵人賽