
前面幾天,我們深入探討了 Data Lakehouse 的核心技術:從 Apache Iceberg 的 table format、Parquet 的欄式儲存設計,到 OLAP 查詢引擎如何高效處理分析查詢。這些技術解決了「如何儲存」和「如何查詢」的問題,但還缺少一個關鍵環節:如何將可觀測性資料持續地送進 Data Lakehouse?
在傳統的監控架構中,我們通常會將 metrics、logs、traces 直接送到專門的儲存系統(如 Prometheus、Loki、Tempo)。不過在 Data Lakehouse 架構中,我們需要一個可靠的 data pipeline,可以接收大量的資料、批次處理、確保資料不遺失,更重要的,是他要怎麼把 OTLP 格式的資料轉換成 Open Table Format 所支援的資料格式(如 Parquet)。
今天,我們要介紹 AWS Kinesis Data Firehose,一個完全託管的串流 ETL 服務。在介紹 Firehose 之前,我們先來看看在設計可觀測性資料管道時會面臨到哪些挑戰,以及為什麼選擇 Firehose 作為解決方案。
在設計可觀測性資料的 ETL 管道時,我們面臨幾個核心挑戰:
目前 OpenTelemetry Collector 的 exporter 生態系統中,並沒有直接支援寫入 Iceberg 格式或 S3 Table 的 exporter。這意味著我們要不是需要自己客製化一個 exporter,不然就是需要在 Collector 和儲存層之間建立一個轉換層。
OTLP(OpenTelemetry Protocol)匯出的資料是結構化的 JSON 或 Protobuf 格式,包含巢狀的資料結構。我們不僅需要將 OTLP 格式 mapping 到 table schema、處理巢狀的 attributes 和 resource 欄位,也需要將資料轉換為 Parquet 格式以獲得更好的壓縮率和查詢效能。
OTel Collector 採用批次匯出模式,一次可能包含數百筆遙測資料。但在寫入 S3 Table 時:
我們有兩種選擇:
即時轉換雖然增加前端處理成本,但能減少資料延遲,且不需要儲存兩份資料(raw + structured)。
AWS Kinesis Data Firehose 是一個完全託管的服務,它可以用最簡單的方法,將串流資料可靠地載入到資料湖、資料倉儲和分析服務。
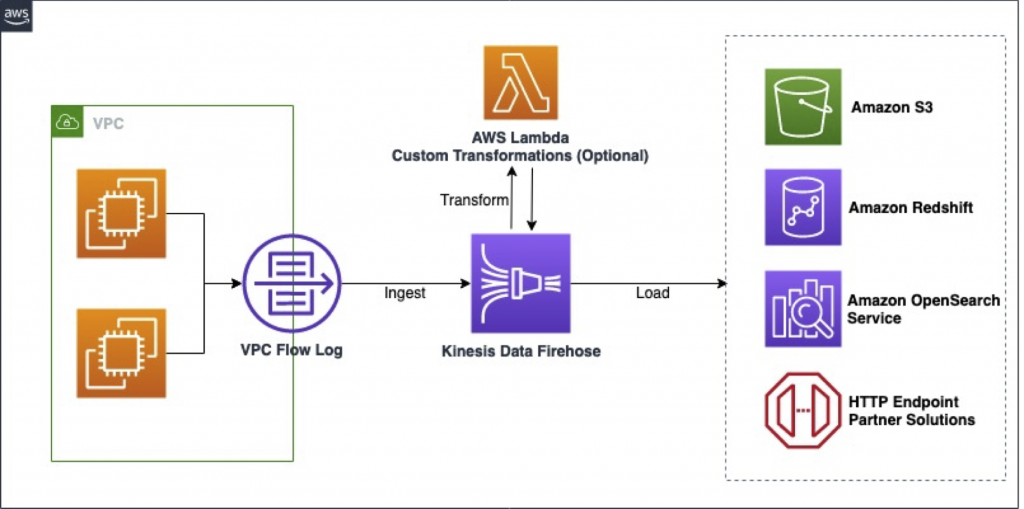
如上圖所示(以 AWS VPC Flow Logs 為例),Firehose 的資料流程包含以下幾個關鍵環節:
這個架構模式與我們的可觀測性資料管道非常相似,核心優勢在於:
基於上述挑戰,我們評估了幾種可能的架構方案:
OTel Collector → Raw OTLP in S3 → AWS Glue (Scheduled) → Structured S3 Table
這個方案直接透過 Collector 現有的 Exporter,將 原始的 OTLP JSON 檔存入 S3 General Bucket,再透過 Glue 去定期的將資料轉換成 S3Table(S3Table 我們會在後面的章節進行介紹)
優點:
缺點:
OTel Collector → API Gateway → Lambda (Transform) → Firehose → Structured S3 Table
由於沒有現成的 Exporter 可以直接將資料打進 S3Table,所以先由 API Gateway 接收,再透過 Firehose 進行資料轉換,包含將 OTLP 格式轉換成欄式資料格式、以及將 JSON 檔轉為 Parquet。
讀者可能會有疑問,Firehose 本身有內建資料轉換的 Lambda,為什麼還要自架一個 Lambda 在 Firehose 前面?這邊的設計考量將會留到明天的章節進行介紹。
優點:
缺點:
基於上述比較,我們選擇方案二:即時串流轉換,理由如下:
在可觀測性場景中,資料的即時性非常重要。如果採用批次 ETL,可能需要等待數分鐘到數小時才能查詢到新資料,這對於故障排查和即時監控是不可接受的。
透過 Lambda + Firehose 的即時轉換,資料從產生到可查詢的延遲可以控制在數秒內。
如果先存 raw OTLP data,再用 Glue 轉換成結構化格式,我們需要同時保留兩份資料:
即時轉換只需要儲存一份結構化資料,根據我們的估算,可以節省約 40-50% 的儲存成本。
Firehose 的核心優勢在於:
在設計資料接收端點時,我們也考慮過使用 Kinesis Data Streams 取代 API Gateway:
API Gateway:
Kinesis Data Streams:
由於 OTel Collector 本身已經具備 buffer 和批次匯出功能,我們認為不需要 Kinesis Data Streams 的額外 buffering。選擇 API Gateway 可以簡化架構並降低成本。
今天我們探討了建立可觀測性資料管道的挑戰,以及如何選擇合適的架構方案。透過比較三種不同的方案,我們看到了在即時性、成本和維運複雜度之間的權衡。
核心決策要點:
明天,我們將深入探討 Firehose 的實際配置細節,包括 Buffer 設定、Lambda 轉換邏輯、資料路由策略等,並透過實際的 AWS Console 截圖來展示如何設定這些功能。
AWS - Introducing Amazon VPC Flow Logs to Kinesis Data Firehose
AWS Kinesis Data Firehose - Developer Guide
AWS Firehose - Data Transformation

 iThome鐵人賽
iThome鐵人賽