
在先前文章中,我們探討了 LLM 可觀測性平台的重要性。然而,僅僅能夠「看見」模型的行為是不夠的;我們還需要一套系統化的方法來「衡量」其優劣,這就是 LLM 評估(LLM Evaluation)的核心價值。本文將以此為基礎,深入探討為何需要 LLM 評估、它與傳統機器學習評估的異同,並結合 Langfuse、LangSmith、Arize Phoenix 等業界領先平台的實踐,勾勒出一套從開發到部署的完整評估與優化流程。
在大型語言模型(LLM)的應用開發中,評估不僅是品質保證的環節,更是驅動產品迭代、建立使用者信任的引擎。若缺乏有效的評估,我們將難以駕馭 LLM 的非確定性,導致應用程式表現不穩、充滿風險。LLM 評估的重要性主要體現在以下幾個方面:
許多人初次接觸 LLM 評估時會感到困惑,但其核心思想早已深植於傳統機器學習(ML)領域。理解它們之間的傳承與分歧,是掌握 LLM 評估的關鍵第一步。
無論是傳統 ML 還是 LLM,評估的根本目標都是「衡量模型輸出結果與『期望的、正確的』結果之間的差距」。
在傳統 ML 中,這個過程相對直接,因為「正確答案」通常是明確且唯一的:
模型預測類別,如「這是垃圾郵件嗎?」。用癌症檢測模型舉例:
| 實際情況 | 預測「有癌症」 | 預測「無癌症」 |
|---|---|---|
| 真有癌症 | True Positive (TP): 正確診斷 | False Negative (FN): 漏診 |
| 無癌症 | False Positive (FP): 誤診 | True Negative (TN): 正確排除 |
(TP + TN) / 總樣本。整體答對率。但在不均衡資料(如癌症僅 1%)下易誤導——一個總預測「無病」的模型可達 99% 準確率,卻漏掉所有病人。 2025 年研究強調,這在 LLM 偏見檢測中常見。TP / (TP + FP)。預測陽性中,真陽性比例。強調「不誤傷」,適合減少假警報,如 LLM 毒性篩選。TP / (TP + FN)。真陽性中,被找出的比例。強調「不漏網」,癌症檢測優先此指標;在 LLM 中,用於捕捉所有幻覺案例。2 × (Precision × Recall) / (Precision + Recall)。平衡兩者,避免極端。 權衡:高召回可能犧牲精確,反之亦然——這是 ML 的經典 trade-off,在 LLM 相關性評估中同樣適用。模型預測連續值,如房價。假設預測 $500 萬,實際 $520 萬。
平均 |預測 - 實際|。平均偏差多少?直觀,如平均差 $15 萬。適合 LLM 連貫性評分。平均 (預測 - 實際)²。懲罰大誤差更嚴厲,適合避免離譜預測,如 LLM 長文生成中的嚴重偏差。| 問題類型 | 指標 | 核心問題 | 範例 |
|---|---|---|---|
| 分類 | Accuracy | 整體答對率? | 毒性分類的整體準確,但小心偏見不均衡 |
| 分類 | Precision | 預測陽性中,真陽性多少? | 幻覺標記的「不誤傷」 |
| 分類 | Recall | 真陽性中,找回多少? | 捕捉所有安全違規 |
| 分類 | F1-Score | 如何平衡精準與召回? | RAG 相關性綜合分 |
| 迴歸 | MAE | 平均差多少? | 評分模型的平均品質偏差 |
| 迴歸 | MSE | 誤差有多離譜? | 懲罰嚴重幻覺的生成 |
當我們試圖將傳統的評估框架套用在 LLM 上時,會發現格格不入。這是因為 LLM 的核心特性為**生成(Generative)與輸出的非結構化。**徹底顛覆了過去非黑即白的評估標準。這種轉變帶來了幾個深刻且複雜的全新挑戰,迫使我們必須用新的視角來思考「好」與「壞」。
我們首先面臨的衝擊是,傳統評估中最重要的基石,唯一的「標準答案」(Ground Truth)在此刻已然瓦解。對於生成式任務而言,好的答案往往是一個範圍,而非一個定點。例如,請 AI 客服 Agent 安撫一位不滿的顧客,什麼是「最好」的回應?是簡潔、有同理心,還是提供具體的補償方案?十位客服專家可能會給出十個措辭不同但同樣優秀的答案。因此,我們無法再用簡單的字串比對來判斷優劣。
更棘手的是,LLM 不僅僅會「答錯」,它們還會以一些傳統模型從未有過的方式「犯錯」。這些全新的失敗模式,催生了我們必須關注的全新評估維度:
最後,LLM 的表現並非恆定,而是與其接收到的「輸入」,也就是 Prompt 和對話歷史 (Context) 緊密相連。同一個模型,一個精心設計的 Prompt 能引導出精準的回答,而一個模糊的 Prompt 則可能導致混亂的輸出。因此,我們的評估不僅僅是在衡量模型本身的能力,更是在評估整個互動系統設計的有效性。
為了應對上述的獨特挑戰,我們不能再依賴傳統的準確率或 F1-Score。整個社群發展出了一套更側重於語意品質、安全性和可靠性的評估詞彙。這些維度共同構成了一把衡量 LLM 應用品質的標尺,幫助我們定義何謂一次「成功」的 AI 互動。
以下是針對我們的 AI 客服 Agent 這類應用,最關鍵的幾個核心評估維度:
忠實度/可信度 (Faithfulness / Groundedness)
這個維度是建立用戶信任的基石,也是我們對抗「幻覺」的主要武器。它衡量的是,當 Agent 依據內部知識庫或文件來回答時,其生成的內容是否完全忠於原始資料,沒有添加、扭曲或捏造任何資訊。
答案相關性 (Answer Relevance)
一個真實但無用的答案對用戶來說毫無價值。這個維度評估的是,Agent 的回答是否直接、精準地命中了用戶提問的核心,有效地解決了他們當前的困惑或問題,而不是答非所問。
上下文相關性 (Context Relevance)
在更複雜的系統(例如 RAG)中,這個維度扮演著偵探的角色。它評估的是系統在生成答案之前,從大量資料中檢索到的背景資訊片段,是否與用戶的問題高度相關。如果檢索到的上下文從一開始就錯了,那麼後續的生成結果也很難正確。
無害性 (Harmlessness / Toxicity)
這是一條不可逾越的紅線。此維度旨在確保 Agent 的輸出不包含任何有害、冒犯、歧視性或不適當的內容。它是保護品牌聲譽和用戶體驗的關鍵安全網。
確立了我們需要衡量的維度後,下一個關鍵問題便是「如何」進行測量?我們如何為「同理心」或「忠實度」這樣抽象的概念賦予一個具體的分數?在實踐中,開發者們探索出了三條主要路徑。這三種方法並非相互排斥,而更像是一個光譜,代表了在評估品質、成本、速度和規模化能力之間的種種權衡。
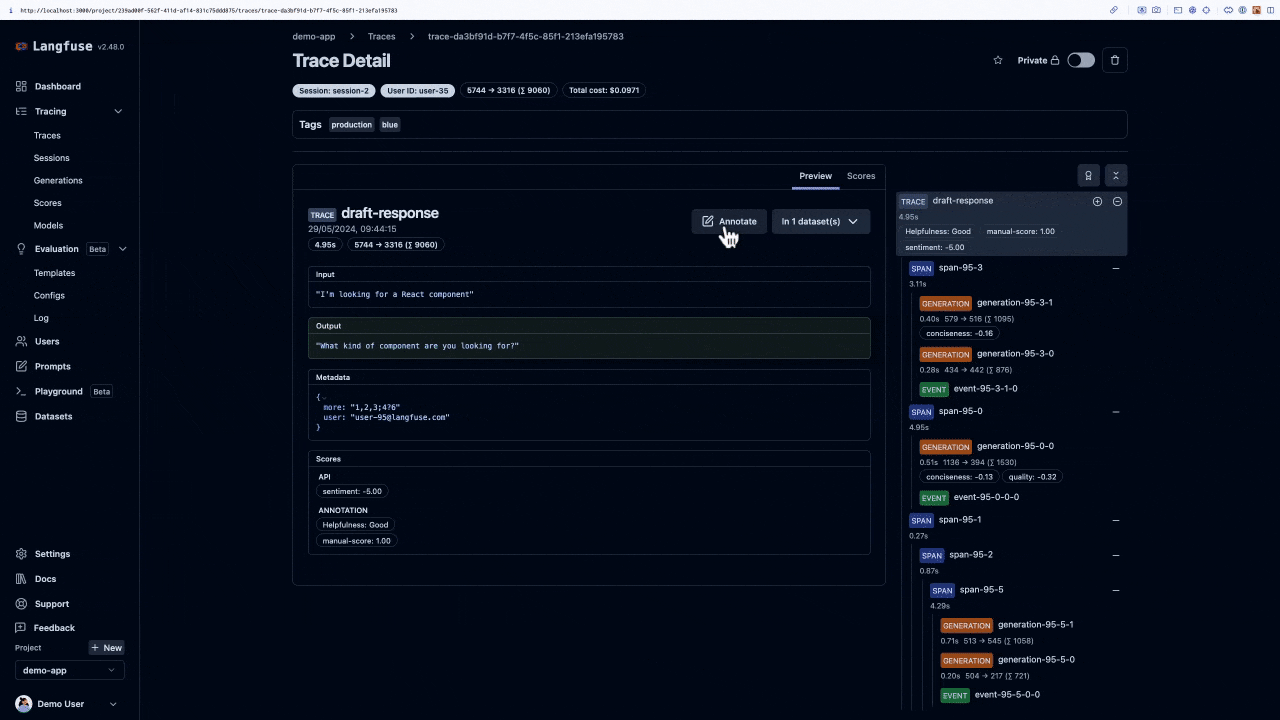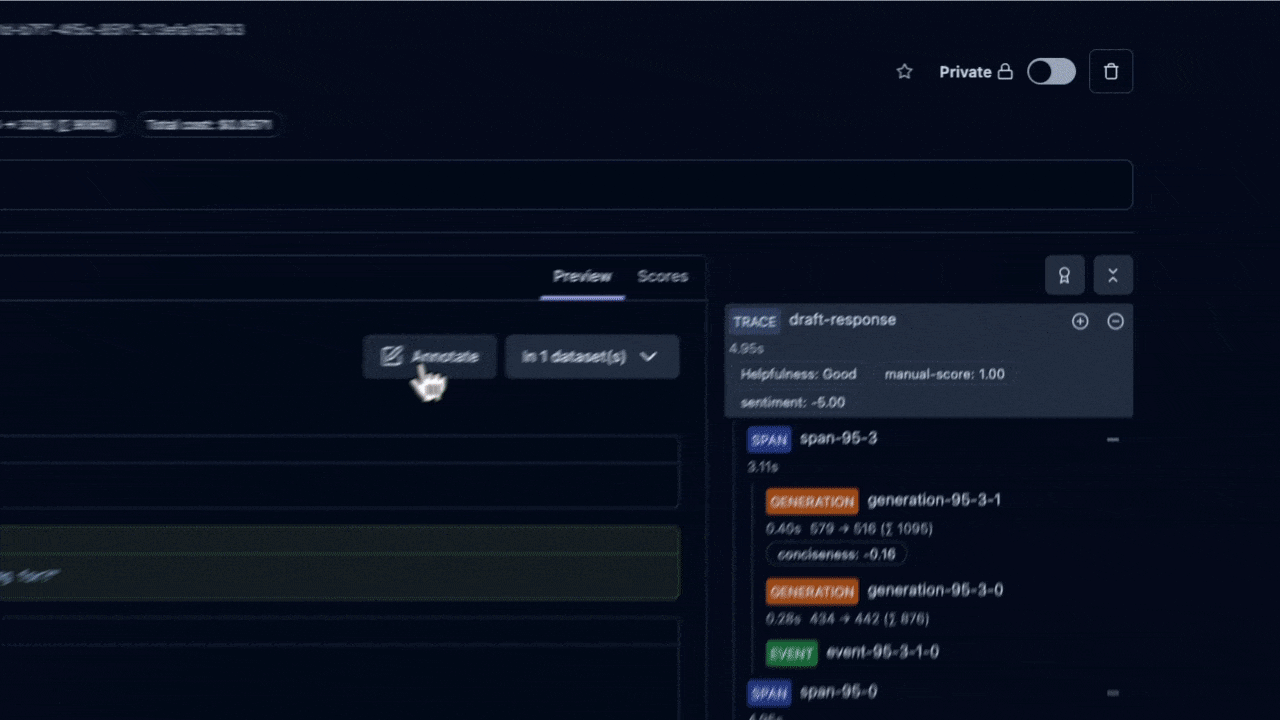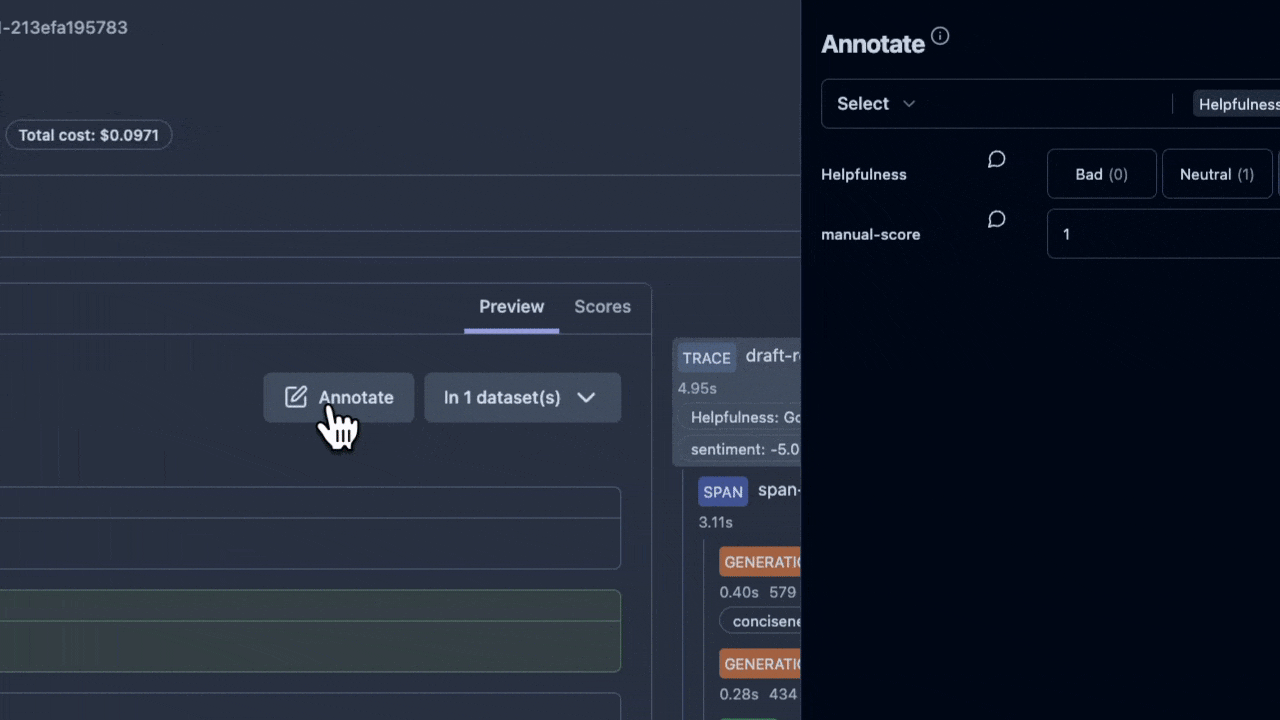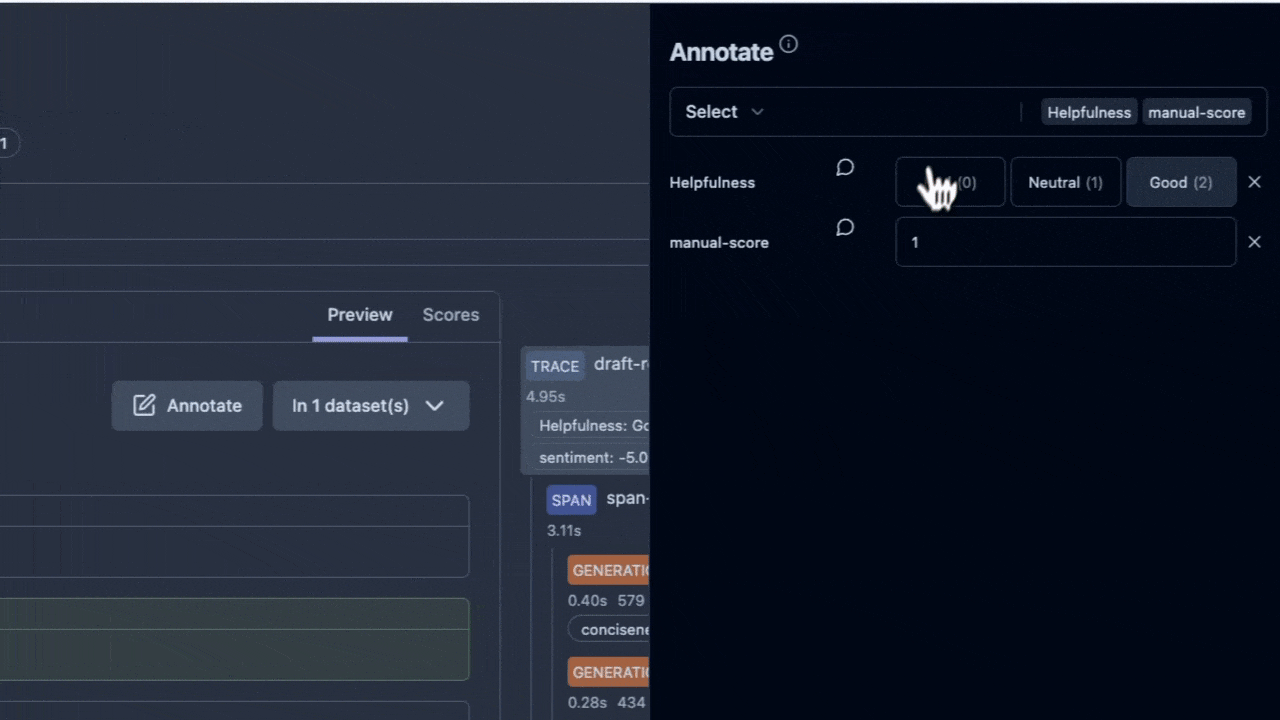
在所有評估方法中,人類的判斷力始終是最終的仲裁者,也是我們最信賴的黃金標準。當我們想知道 AI 客服 Agent 的回應是否真正有同理心,或是在一個複雜的場景下是否給出了最得體的建議時,只有領域專家(例如資深的客服主管)才能做出最精準的判斷。
面對人工評估在規模上的瓶頸,開發者們自然地轉向了自動化,試圖用程式化的方法來取代人力。最早期的嘗試,是借鑒自機器翻譯和文章摘要領域的傳統 NLP 指標,例如 ROUGE 和 BLEU。

https://www.evidentlyai.com/blog/llm-evaluation-framework#llm-evaluation-methods
既然傳統的自動化指標無法理解語意,而人類評估又難以規模化,一個革命性的想法應運而生:我們能否用一個更強大的 AI,來評估另一個 AI? 這就是「LLM 即評審」(LLM-as-a-Judge)的核心思想,也是當前最熱門且最實用的趨勢。
https://langfuse.com/docs/evaluation/overview
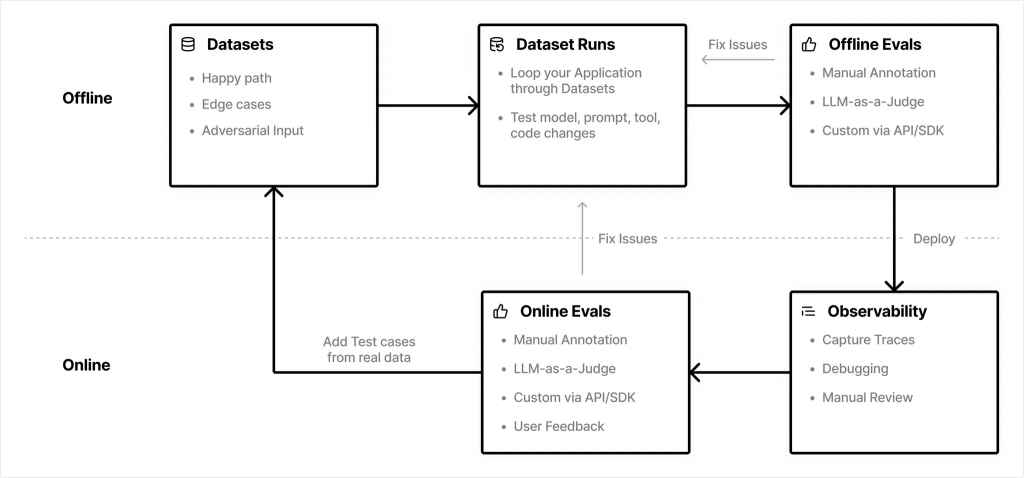
一個成功的 LLM 應用,其評估流程是貫穿開發、部署到維運的完整閉環,通常結合了線下與線上兩種模式。
線下評估在開發階段扮演關鍵角色,它在一個受控的環境中進行,通常作為 CI/CD 流程的一部分,用於衡量版本迭代的改進或回歸。
核心要素:建立黃金測試集 (Golden Set)
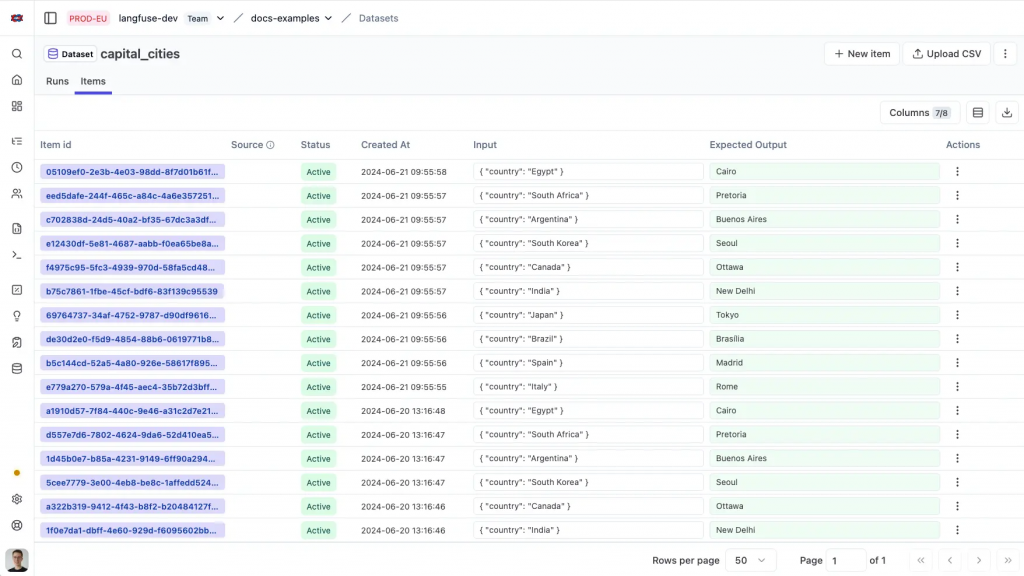
黃金集是一個高品質、由專家手動標註的數據集,作為評估的「地面真相」。它通常不大(約 100-500 個範例),但覆蓋了應用的核心場景、邊緣案例和曾出現過的錯誤。這也是 Langfuse 等平台中 Dataset 功能的核心理念。
一個典型的黃金集結構(如 JSON 格式)包含:
[
{
"id": 1,
"prompt": "用戶詢問:如何重置密碼?",
"golden_response": "請點擊登入頁面的 '忘記密碼' 連結,輸入您的電子郵件,我們將發送重置指示至您的信箱。",
"task_type": "問答",
"category": "帳戶管理"
},
{
"id": 2,
"prompt": "用戶抱怨:產品有瑕疵(附件圖片顯示刮痕)。",
"golden_response": "抱歉造成不便,請提供訂單號,我們將發起退換貨流程,並在 48 小時內處理。",
"task_type": "生成回應",
"category": "售後服務"
}
]`
在 LLM 可觀測性平台中,你可以透過 UI 或 SDK,輕鬆地將生產環境中捕獲的真實追蹤(Traces)標註並儲存為黃金集,實現數據的持續積累。
如果說線下評估是在可控的實驗室中奠定基礎,那麼線上評估就是將我們的 AI 客服 Agent 真正推向充滿未知與混亂的真實世界,並從每一次互動中學習和進化的過程。在這個階段,我們的目標是衡量 Agent 在真實用戶流量下的表現,並捕捉那些在測試集中永遠無法預料到的問題。
https://arize.com/blog/llm-tracing-and-observability-with-arize-phoenix/
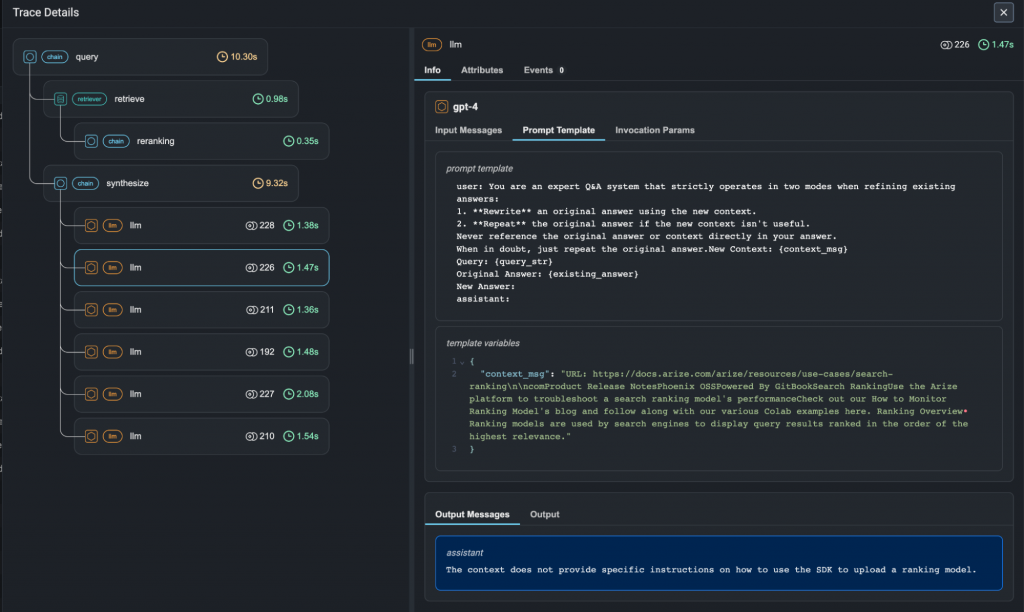
要實現這一點,我們首先需要一個強大的基礎設施:可觀測性。系統必須能將每一次用戶與 Agent 的完整互動,從頭到尾記錄下來,形成一個我們稱之為 Trace(追蹤) 的數據單元。一個 Trace 不僅僅是最終的問答,它更像是一個詳細的「案件檔案」,包含了:
https://docs.langchain.com/langsmith/evaluation-concepts
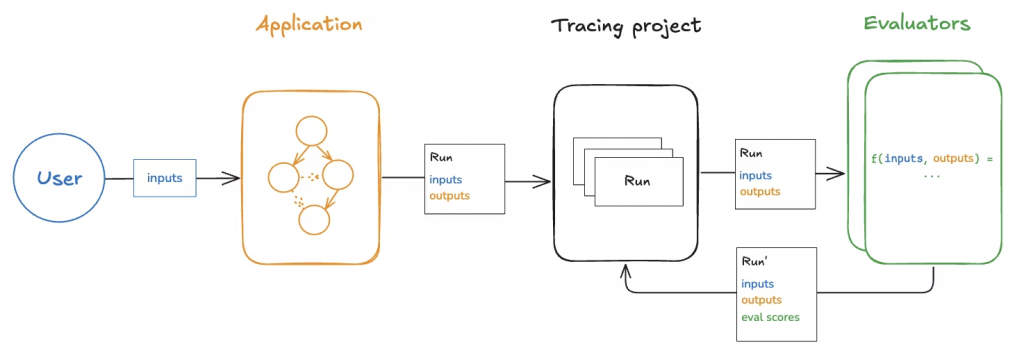
正是這些豐富的 Traces,構成了我們線上評估的基礎。它們是我們洞察真實世界表現的「原始素材」,我們可以透過以下幾種關鍵方法來分析和利用它們:
收集使用者回饋:最直接的真相來源
沒有什麼比用戶的親身感受更真實了。因此,最直接有效的線上評估方法,就是給予用戶一個「發聲」的管道。這通常是在對話結束時提供一個明確的「👍 / 👎」按鈕或評分機制。這個看似簡單的訊號極其強大,因為它會被直接附加到該次對話的 Trace 上。當我們事後複盤一個「👎」的 Trace 時,我們能完整地看到當時的所有上下文和 Agent 的內部運作,從而精準地理解問題的根源。
模型輔助評估:規模化的品質監控
用戶回饋是寶貴的,但並非所有用戶都會提供。為了獲得更廣泛、更持續的品質監控,我們可以將線下使用的 LLM-as-a-Judge 方法應用於線上流量。系統可以從生產環境中捕獲的 Traces 中進行抽樣(或全部捕獲),然後非同步地將它們發送給一個強大的「評審模型」進行評估。正如 Langfuse 等平台所支援的,這種方法讓我們能夠大規模地、自動化地為每一次互動打上「忠實度」、「相關性」等品質分數,從而即時洞察系統整體的健康狀況。
A/B 測試:數據驅動的決策科學
當我們基於觀察提出了一個改進假設(例如,「一個更簡潔的 Prompt 可能會提高用戶滿意度」)時,如何科學地驗證它?A/B 測試是這種場景下的黃金標準。我們可以將一小部分用戶流量(例如 10%)引導至使用新 Prompt 的 Agent 版本 B,而其餘用戶則繼續使用版本 A。在運行一段時間後,我們比較兩個版本 Traces 的各項評估指標——包括用戶回饋率、LLM-as-a-Judge 的評分、問題解決率等——從而用客觀數據來決定是否將新版本全面推送。
線上評估的最終目的,是建立一個從洞察到行動的快速閉環。當上述評估方法監測到服務品質出現下降時(例如,「👎」的比例突然上升,或「幻覺」評分超過了警戒線),系統可以觸發一系列自動化流程,將被動的監控轉化為主動的防禦:
LLM 評估本身並不能直接解決問題,它的真正價值在於驅動一個持續優化的迭代循環。
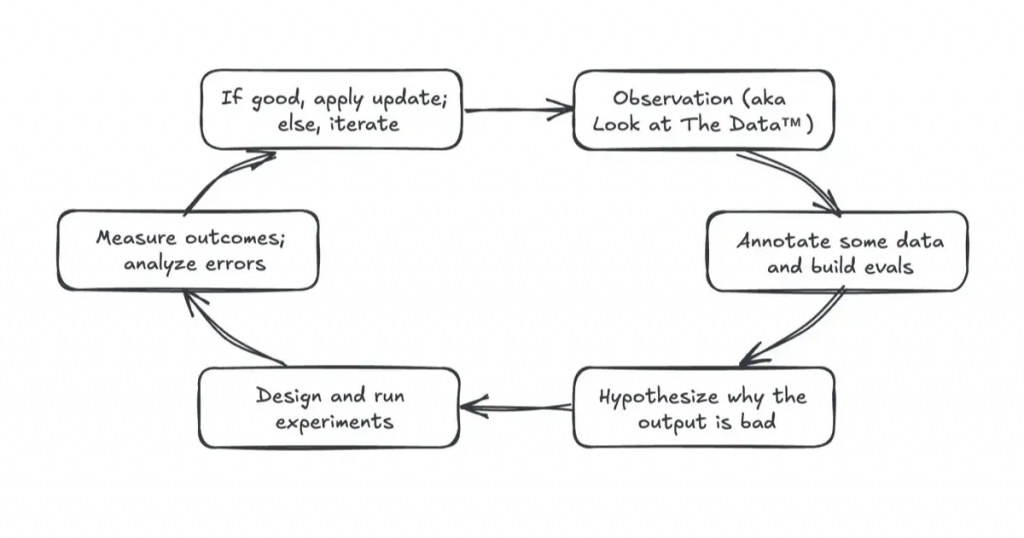
這個循環的步驟如下:
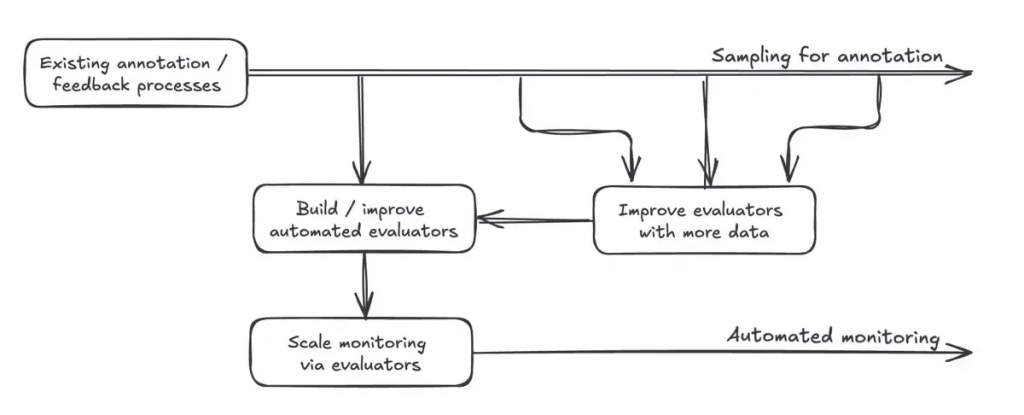
最終,透過不斷收集高品質的人工標註來校準和改進 LLM-as-a-Judge 等自動評估器,我們可以逐步建立起一個值得信賴的自動化監控系統,從而實現規模化的品質管理和持續優化。
總結而言,LLM 評估是從可觀測性邁向可靠性的必經之路。它繼承了機器學習的核心思想,並針對大型語言模型的獨特挑戰進行了演進。透過結合線下黃金集測試與線上真實流量監控,並在 Langfuse、LangSmith、Arize Phoenix 等現代化平台的輔助下,開發團隊才能建立起一個數據驅動、持續迭代的優化閉環,最終打造出真正穩健、可信的 AI 應用。
References:


