
前面我們花了許多篇幅介紹 Observability 2.0 的理念,以及如何透過 Data Lakehouse(Parquet + Iceberg)建立 Single Source of Truth。我們也深入探討了 ClickHouse Exporter 如何將 OTLP 資料轉換成扁平的 table schema。
筆者自己在研究架構時,除了參考目前現有的 exporter 處理資料的做法,同時也會好奇,那麼其他企業是怎麼設計可觀測性系統的?我們目前的設計和其他人的做法有何不同?
今天,讓我們來看一下 AWS 針對企業認證推出的 Claude Code + AWS Bedrock 解決方案,雖然這個 repo 和可觀測性沒有直接的關係,不過它在文件中也有詳細說明要如何架設觀測此系統的可觀測性架構。
如前面所說,這個解決方案的目的是幫助組織在使用 Claude Code + Amazon Bedrock 的情境下,整合企業現有的身份驗證機制(OIDC/SSO 等)。它會在後端建立必要的 AWS 資源(例如 OIDC provider、Cognito 或 IAM 信任關係、角色與政策、觀察用的 CloudWatch 或監控資源等)來支援身份交換與權限控制。然後對使用者端提供一個可以在本地跑的認證流程(credential process),讓用户在呼叫 Claude / Bedrock 時,不需要擁有或管理 API 金鑰。
它背後所架設的可觀測性系統架構圖如下: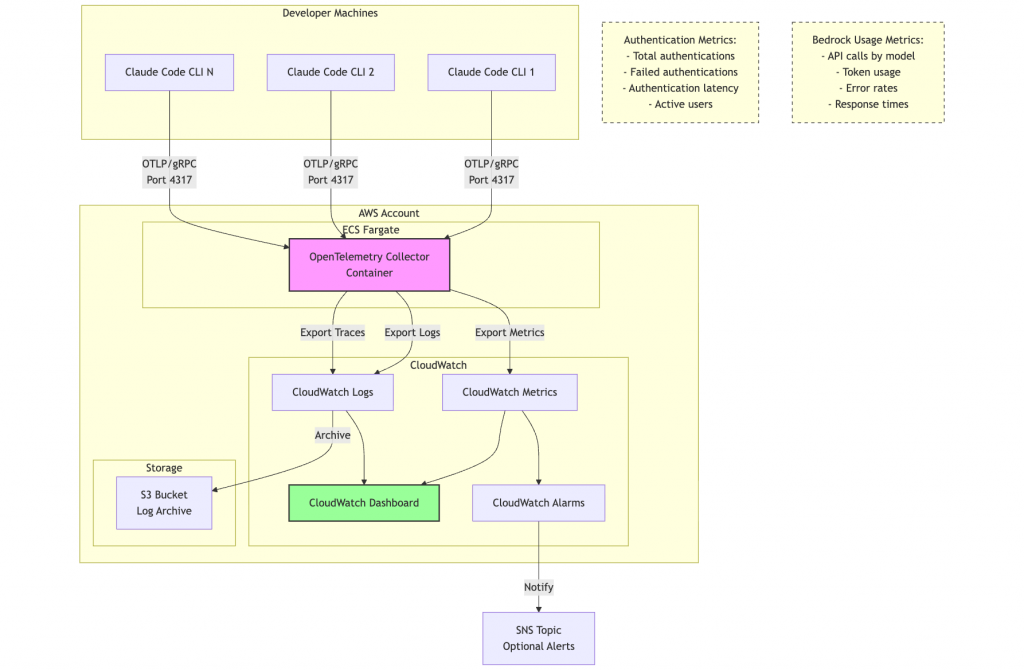
圖片出處:https://github.com/aws-solutions-library-samples/guidance-for-claude-code-with-amazon-bedrock/blob/main/assets/images/architecture-diagram.md
可以從這個架構圖看到幾個重點:
可以看到整體的架構分為兩部分,一部分是可以開箱即用的 CloudWatch,一部分是可以長期放置資料的 S3。在 Firehose 到 S3 的這部分設計比較符合我們之前所說的 observability 2.0 架構,可以統一從一個地方來做可觀測性資料的查詢。但是為什麼前面要再放一層 CloudWatch?
CloudWatch 所提供的服務大家應該都不陌生,它一直都扮演即時監控與事件告警的角色。儘管它不是一個開放的 data lakehouse 或其他分析平台,但若你的服務都是架設在 AWS 上,它與 AWS 生態的緊密連結可能會是一個可考慮的方案。
CloudWatch 主要負責三大類訊號:Metrics、Logs、Traces。其實也是我們所熟悉的三大支柱。
這三者組合起來,讓 CloudWatch 成為一個 高即時性、以營運為中心的可觀測性解決方案。
不過,我們可能不只收集來自 AWS 服務的 signals,例如我們現在看的這個解決方案,就需要收集從 claude code 所暴露出來的 signals,而 claude code 原生就支援 OTLP 格式的觀測資料。
因為 CloudWatch 的 Metrics 並不是原生支援 OTLP(OpenTelemetry Protocol)的格式。所以並沒有辦法直接將 claude code 的 signals 打進 CloudWatch。
而 EMF 是 AWS 設計的一種「橋樑格式」,可以讓應用程式或代理程式直接在 log 中嵌入結構化的 metric 資料,然後由 CloudWatch 自動解析、轉換成 Metrics。
簡單來說,EMF 的目的就是讓 log 與 metrics 可以共生(logs as metrics)。
如此一來,我們既可以使用標準的 OTLP 格式來處理可觀測性資料,又能夠使用開箱即用的 CloudWatch 即時監控工具,不需要等待資料進入到 data lakehouse 才能進行分析。
同時,對於異常的系統指標也有內建的告警系統可以快速觸發警報。
從這個案例可以看到,AWS 的設計並非要完全取代 Observability 2.0 的資料湖架構,而是讓 CloudWatch 承擔「即時監控」與「事件響應」的角色。
透過 EMF 這層轉換機制,系統能在第一時間將 OTLP 資料送進 CloudWatch,達到快速可視化與告警;
同時又能透過 Firehose 將相同資料長期儲存在 S3,保留資料湖分析的彈性與延展性。
這樣的雙層架構代表著,不同的架構選擇其實還是取決於團隊所面臨的問題。
回到我們從 Day 18開始討論的 Firehose + S3 Table 的 data lakehouse 架構,兩者所在意的問題就不盡相同:
當然,今天的文章採取的是混合方案,既保留了即時監控與告警,也做到了長期分析以及解決高基數資料所帶來的挑戰,不過,在這種架構下,兩邊都要儲存資料所帶來的成本就變成了另一項挑戰。
Amazon CloudWatch Documentation
AWS Documenation - Specification: Embedded metric format
guidance-for-claude-code-with-amazon-bedrock

 iThome鐵人賽
iThome鐵人賽