
昨天我們正式踏入了 NumPy 的世界,學會了高效陣列運算。
今天,我要帶大家進入另一個 Python 超級利器——Pandas,
專門用來「操作資料表」的神器!
如果你曾經用 Python 的 list 或 dictionary 來處理 Excel / CSV,
可能會有這種感覺:
「我只是想算每個學生的平均分數,結果要寫十幾行,還容易出錯…」
登愣!這就是 Pandas 出場的時刻!
Pandas 這個名字可不是因為作者喜歡熊貓,
而是來自 “Panel Data”(多維資料)與
“Python Data Analysis” 的縮寫。
它由 Wes McKinney 在 2008 年於美國 AQR Capital(量化投資公司)開發。
當時他發現,用 NumPy 處理金融時間序列資料實在太不方便了——
缺乏欄位名稱、索引、日期對齊等功能。於是他乾脆自己打造了一個新工具,
目標是:
讓 Python 可以像 Excel 一樣好用,但又能像 NumPy 一樣高速運算。
結果呢?Pandas 成功了。
如今它已是 Python 資料分析的標準配備,
無論是學術研究、企業報表、AI 專案、或 Kaggle 競賽,
幾乎所有人都離不開 Pandas!!

一句話總結:處理「表格型資料」的萬能工具。
你可以想像成「Python 版 Excel」,但更聰明、更靈活、更快。
它能幫你做的事情包括:
Pandas 的核心世界中,有兩個關鍵角色:
接下來我們就一步步認識它們吧!
幾乎所有人都這樣寫(取pandas別名為pd):
import pandas as pd
想像一下,你有一排資料,但這排資料「有標籤」。
這就是 Series。
換句話說:
Series = 一個「有名字的」一維陣列。
就像是你買了一排飲料,每瓶都有標籤(index),
你就能用標籤來找飲料,而不是數第幾瓶。
import pandas as pd
s = pd.Series([100, 200, 300, 400])
print(s)
輸出: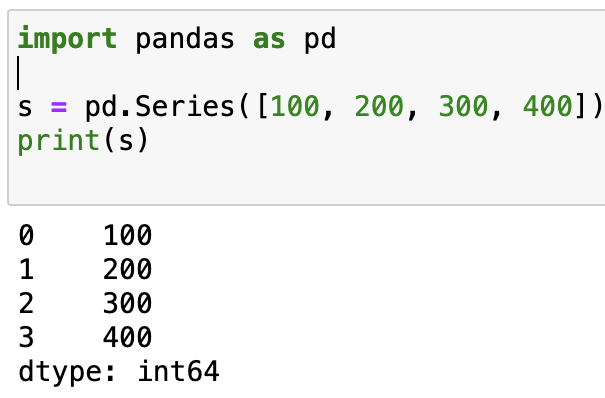
說明:
s = pd.Series([100, 200, 300, 400], index=['a','b','c','d'])
print(s)
print("索引b的值",s['b']) # 200
輸出: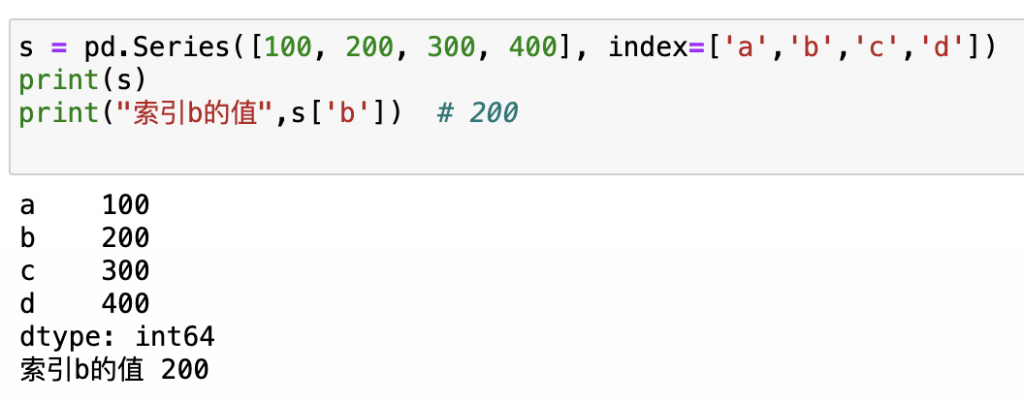
或用水果價格當例子::
import pandas as pd
price = pd.Series([100, 200, 300], index=["apple", "banana", "cherry"])
print(price)
輸出: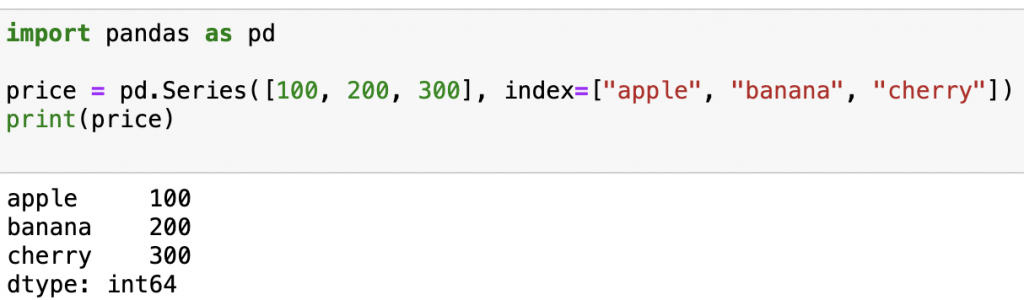
有沒有覺得這樣更像字典(dict)?
沒錯,Series 其實就像「加強版字典」,
既有順序、又有向量運算的能力!!
Series 支援像 Numpy 一樣的數學運算:(延續上面)
print(price * 2)
print(price + 50)
輸出: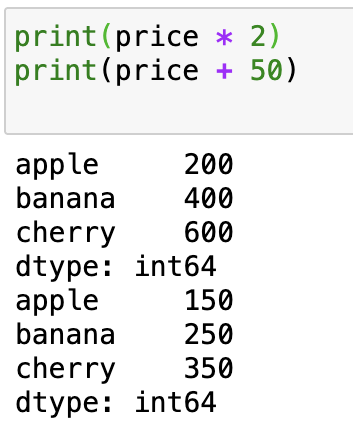
你不需要寫迴圈、也不用自己跑 for,
Pandas 幫你一次搞定!是不是很方便?
print("香蕉的價格:",price["banana"])
print("蘋果與櫻桃的價格:")
print(price[["apple", "cherry"]])
輸出: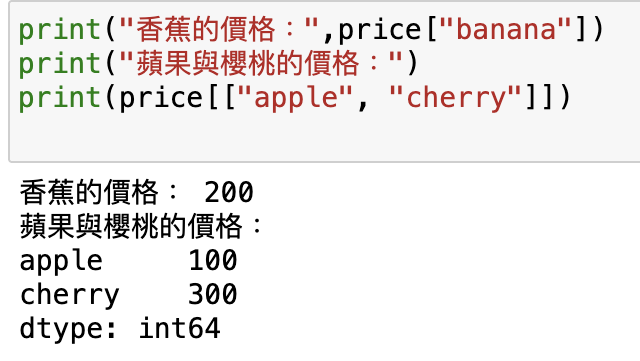
是不是有點像 Excel 裡用欄位名稱找資料?
這就是 Pandas 的方便之處。
print("價格超過150元:")
print()
print(price[price > 150])
輸出: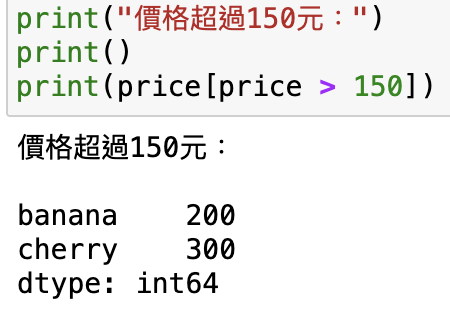
這就是「布林索引(boolean indexing)」的概念。
它是 Pandas 最強大的篩選手段之一!
data = {"milk": 100, "cola": 200, "juice": 300}
s = pd.Series(data)
print(s)
輸出: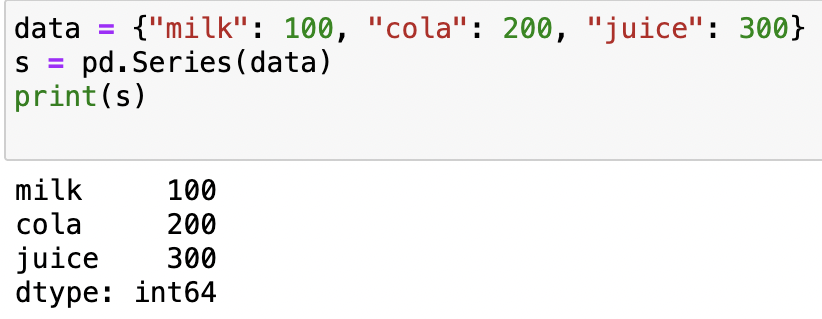
info = pd.Series(["2025-10-12", 3.14, True, "Hello"])
print(info)
輸出: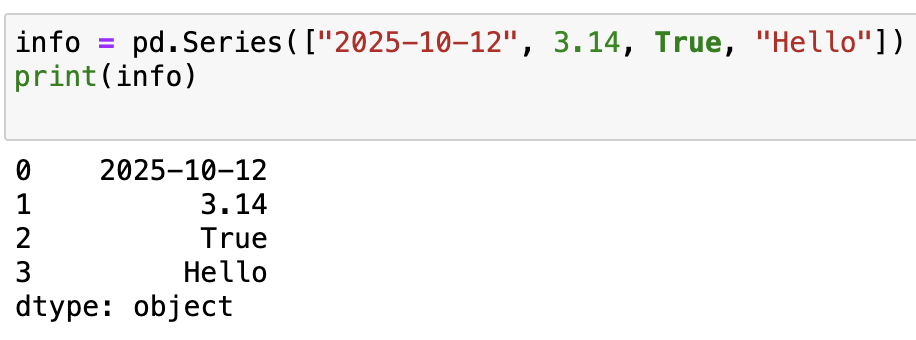
Series 不只限於數字,它可以是文字、布林值、日期、甚至混合型資料。
前面我們說過,Series 就像是一條有標籤的資料。
那如果我們把很多條 Series 並排放在一起,會變成什麼?
沒錯!DataFrame = 一張完整的表格。
想像一下 Excel:
一張表格有「欄名」和「列索引」,每一格都有資料。
DataFrame 就是這樣的存在。它可以儲存整張表格的資料,讓你:
簡單說,DataFrame 是 Pandas 的靈魂。
最常見的建立方式是「用字典(dict)」:
import pandas as pd
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Taipei", "Taichung", "Kaohsiung"]
}
df = pd.DataFrame(data)
print(df)
輸出: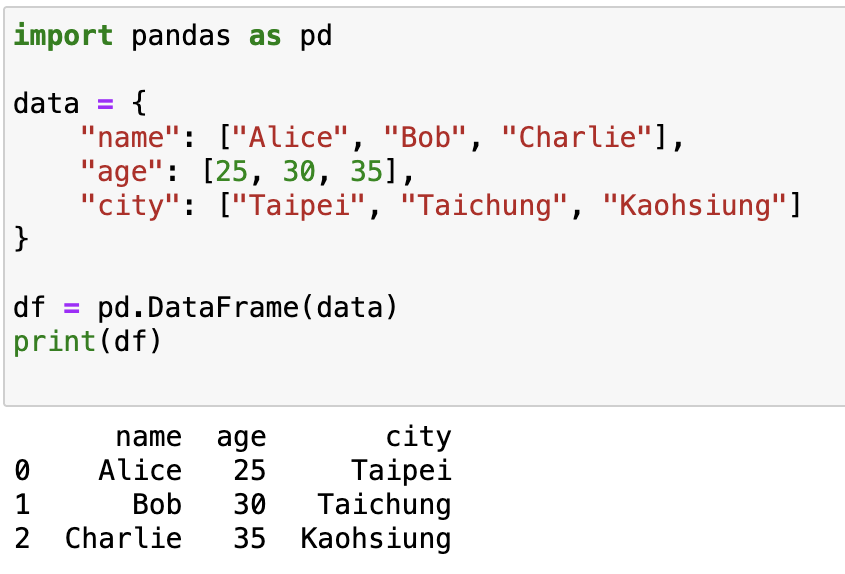
如果你想用字元當作索引,而不是預設的 0, 1, 2:
df = pd.DataFrame(data, index=["A", "B", "C"])
print(df)
輸出:
索引可以幫助我們更直覺地查資料。
例如:
print(df.loc["B"])
輸出:
就像 Excel,一次取一欄或一列都可以。
# 取出欄
print(df["age"]) # 結果是一個 Series
# 取出多欄
print(df[["name", "city"]])
輸出:
df["salary"] = [50000, 60000, 70000] # 新增欄
print(df)
df = df.drop(columns=["city"]) # 刪除欄
print(df)
輸出: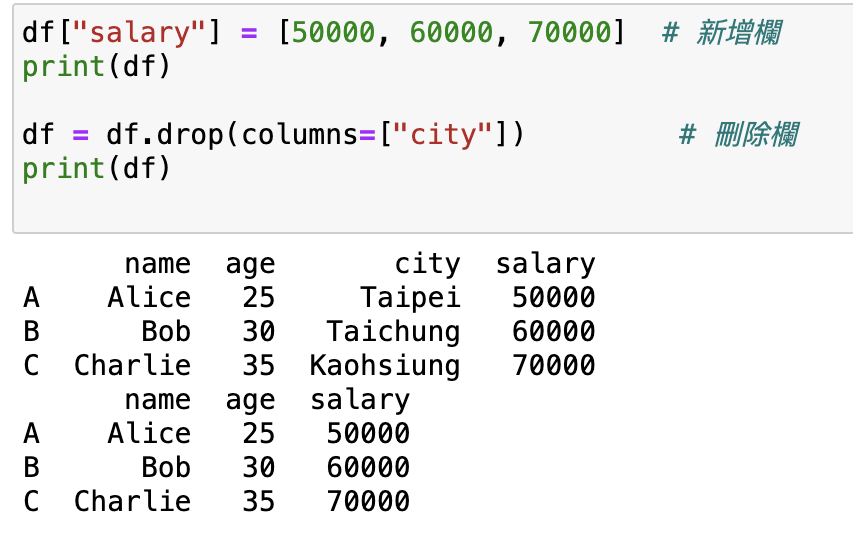
print("年齡")
print()
print(df[df["age"] > 28])
輸出: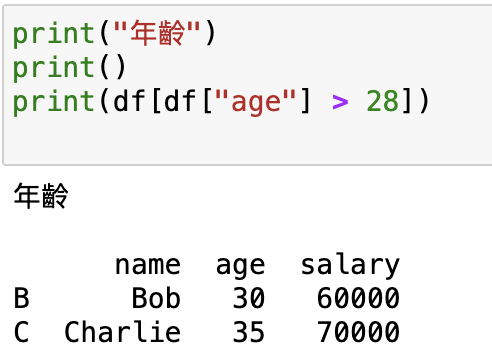
也可以疊加條件:
df[(df["age"] > 28) & (df["salary"] > 60000)]
輸出:(如果直接df不加上print的話就會顯示表格的樣子)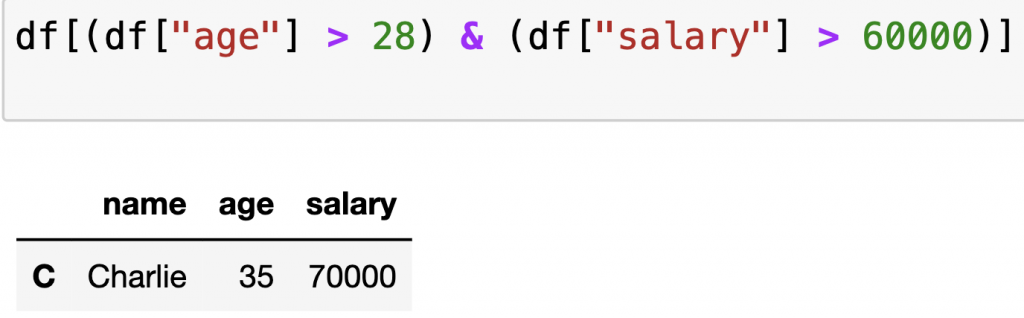
Pandas 內建了超多方便的統計方法: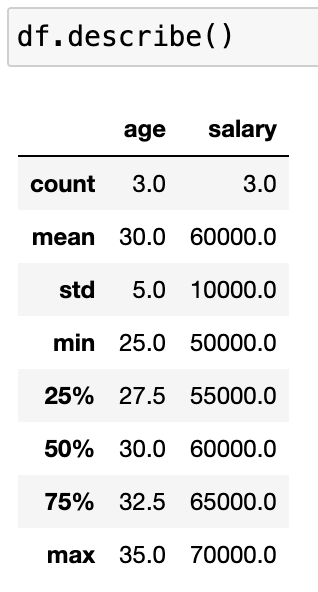
只要一行,瞬間幫你算出平均值、標準差、分位數…
非常適合初步探索資料(EDA)!
這是 Pandas 最經典的功能之一!
sales = pd.DataFrame({
"store": ["ABC-Mart", "SSS-Mall", "ABC-Mart", "SSS-Mall", "ABC-Mart"],
"revenue": [100, 150, 80, 120, 200]
})
print(sales.groupby("store").mean())
輸出:
學會這個技巧就可以輕鬆計算每家店的平均銷售額!
這個功能常被用來做報表、自動統計分析!
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, None, 35]
}
df = pd.DataFrame(data)
print("缺值情況")
print(df.isnull()) # 哪些是缺值
print("刪除缺值")
print(df.dropna()) # 刪除缺值
print("填補缺值")
print(df.fillna(0)) # 填補缺值
輸出: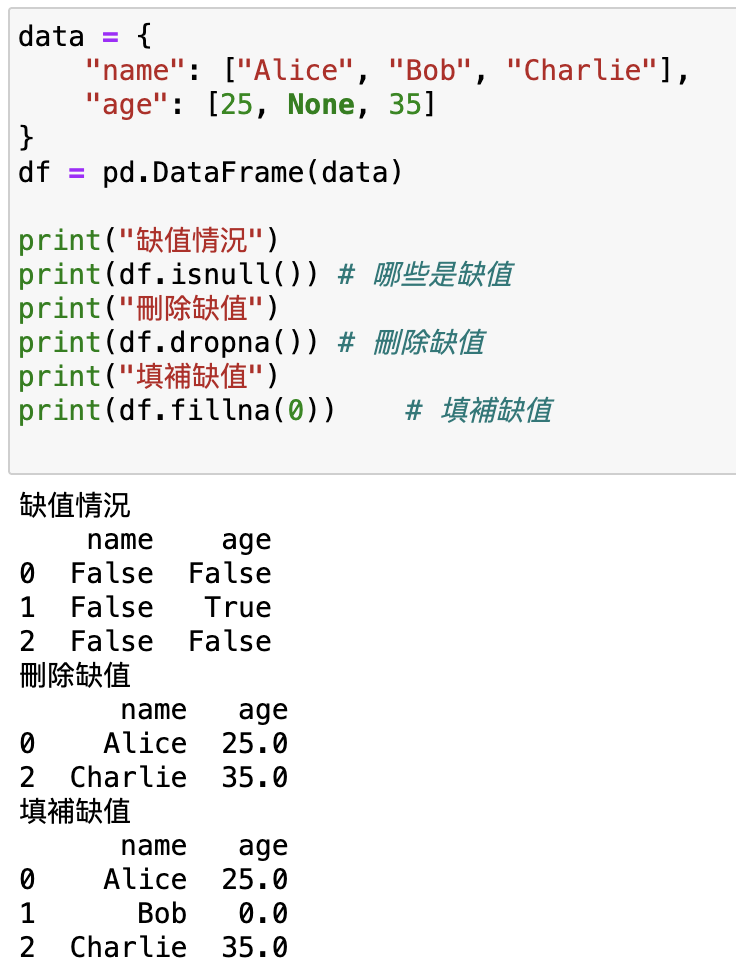
在現實資料裡,「缺值」是常態,
所以 Pandas 也幫你設計好超直覺的修復方法。
今天我們完成了 資料分析入門的第一步 —— 認識 Pandas!
Pandas 幫我們把資料整理、計算、篩選、清理缺值都變得超簡單,
不用再寫冗長迴圈或擔心出錯。
對資料分析的新手來說,
這就是 打開資料分析世界的鑰匙!
明天我們要更進一步,把 Pandas 用到實戰裡:
匯入 CSV 檔案做實際的資料分析應用、
學更多進階 Pandas 語法、
讓你 DataFrame 用得更得心應手!
準備好跟我一起把資料分析的入門能力往前推一大步吧!!
那麼我們就明天見囉!!
