Day28 做完了環境評估以及串接測試後,今天我們會實際把程式部署到 AWS 上面,看看整條路徑能不能撐得住。
首先把應用程式部署到 AWS EC2,確保索引檔能從 S3 正確拉回來,程式啟動不會卡關。接著,透過 Cloudflare Worker 當作前線守門員,幫入口加上流量限制和驗證,避免任何沒必要的流量打爆後端。最後,把應用輸出的 Metrics 交給 Grafana Cloud,這樣就能隨時看到系統狀態,並裝上一個即時的儀表板。
文末,我會把實際跑一整天的 AWS 帳單以及整個鐵人賽的 OpenAI tokens 消耗整理出來,和之前的預估做對照。這樣大家不只看得到架構與程式碼,也能知道這個服務放到雲端,實際上要花多少錢。
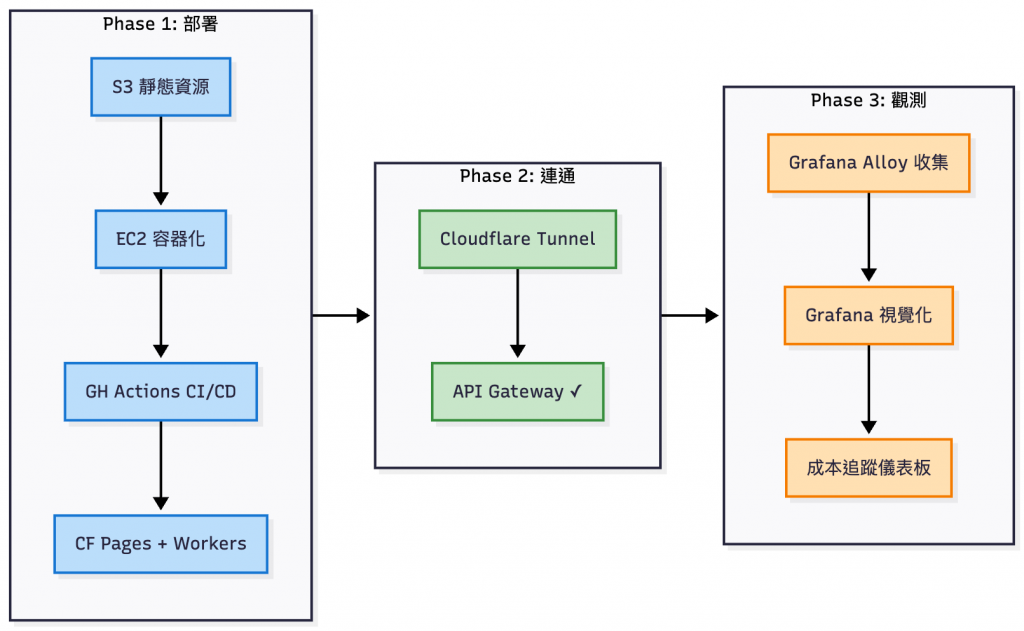
部署、打通環境、後續觀測設置步驟
建置一個專門放 index 的 s3 bucket (可以參考 Day12 知識庫管理) 並且把提前建好的索引檔案(index.faiss / docstore.jsonl)丟到 s3 上面去,然後在 EC2 裡面用 Instance Role + 啟動腳本(user-data.sh)把檔案自動拉下來,讓機器保持 stateless、 之後規模擴展也方便。
記得對應的 s3 IAM role policy 也要補上去:
# s3 Get objects policy
data "aws_iam_policy_document" "s3_get_prefix" {
# 不加沒辦法複製
statement {
sid = "ListOnlyThatPrefix"
effect = "Allow"
actions = ["s3:ListBucket"]
resources = ["arn:aws:s3:::${aws_s3_bucket.this.id}"]
condition {
test = "StringLike"
variable = "s3:prefix"
values = [
"${var.iam_s3_policy_prefix}",
"${var.iam_s3_policy_prefix}*"
]
}
}
statement {
sid = "AllowGetObjectOnlyForPrefix"
effect = "Allow"
actions = [
"s3:GetObject"
]
resources = [
"arn:aws:s3:::${aws_s3_bucket.this.id}/${var.iam_s3_policy_prefix}*"
]
}
}
這個步驟主要是為了把上一個步驟的資料庫相關檔案先拉到 EC2 上面,否則詢問 /ask API 時會吐錯誤,程式不知道要帶什麼索引去問 LLM。同時也可以先把容器的使用者和相關資料夾、套件都先裝好。
#!/bin/bash
set -euxo pipefail
exec > >(tee /var/log/user-data.log|logger -t user-data -s 2>/dev/console) 2>&1
# 更新套件索引 & 系統更新(安全性)
dnf makecache
dnf -y upgrade
# 安裝必要工具
dnf install -y git docker telnet pip
# 啟動 Docker
systemctl enable docker
systemctl start docker
# 安裝 SSM Agent(針對 ARM64 / x86_64)
ARCH=$(uname -m)
if [ "$ARCH" = "aarch64" ]; then
dnf install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_arm64/amazon-ssm-agent.rpm
else
dnf install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
fi
# 啟用並啟動 Agent
systemctl enable amazon-ssm-agent
systemctl start amazon-ssm-agent
# 等待 SSM Agent 確認啟動
for i in {1..10}; do
sleep 3
systemctl is-active amazon-ssm-agent && break
done
# 掛載用資料夾 (容器會用到)
mkdir -p /opt/rag-qa-bot/data
chown -R 10001:10001 /opt/rag-qa-bot/data
# 安裝 awscli(用 IAM Role 拉檔)
python3 -m pip install --upgrade pip
python3 -m pip install awscli
# -----------------------
# 新增:從 S3 下載檔案到 /opt/rag-qa-bot/data
# -----------------------
S3_BUCKET="rag-faq-bot-XXXXXX"
S3_PREFIX="tmp/"
echo "Downloading from s3://$S3_BUCKET/$S3_PREFIX ..."
aws s3 cp "s3://$S3_BUCKET/$S3_PREFIX" /opt/rag-qa-bot/data/ --recursive
echo "S3 download completed."
# -----------------------
## 下載 conda
# 下載 Miniforge3 最新版本(ARM64)
curl -fsSL https://github.com/conda-forge/miniforge/releases/download/25.3.1-0/Miniforge3-25.3.1-0-Linux-aarch64.sh -o /tmp/miniforge3.sh
# 讓安裝檔可執行
chmod +x /tmp/miniforge3.sh
# 靜默安裝到指定目錄
/tmp/miniforge3.sh -b -p ${CONDA_DIR}
# 設 PATH
echo "export PATH=${CONDA_DIR}/bin:\$PATH" > /etc/profile.d/conda.sh
chmod +x /etc/profile.d/conda.sh
source /etc/profile.d/conda.sh
# 驗證
${CONDA_DIR}/bin/conda --version
# 安裝 cloudflared for tunnel
curl -LO https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-aarch64.rpm
sudo yum install -y ./cloudflared-linux-aarch64.rpm
之後 EC2 建好時這些套件都會自動被裝在作業系統裡了。
前面的步驟是把重要的 Infra 相關資源都打通,接下來我們要正式地把 Day27 寫好的專案推上去 AWS 的環境。
首先需要把下面這堆 API key 和環境變數設定寫進去 AWS 的 Secret Manager,所以我們需要用前面提到的 Terraform 再創一個給 App 用的 Secret。
{
"OPENAI_API_KEY": "sk-xxxx", // 記得改成自己的 OpenAI API key
"EMBED_MODEL": "text-embedding-3-small",
"CHAT_MODEL": "gpt-4o-mini",
"RERANK_PROVIDER": "local",
"RERANK_MODEL": "BAAI/bge-reranker-v2-m3",
"RERANK_TOP_K": "3",
"TOP_K": "3",
"MAX_CONTEXT_CHARS": "1800",
"ANSWER_MAX_TOKENS": "400",
"CACHE_BACKEND": "redis",
"REDIS_URL": "redis://XXXX-ro.XXXXX.ng.0001.apne1.cache.amazonaws.com:6379/0", // 記得改成 Redis Cluster 的 Endpoint
"CACHE_TTL_SECONDS": "3600",
"APP_ENV": "production",
"INDEX_PATH": "/data/index.faiss",
"DOCSTORE_PATH": "/data/docstore.jsonl"
}
記得 EC2 的 Instance Role IAM policy 也要加上對應的權限:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadAppSecret",
"Effect": "Allow",
"Action": ["secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret"],
"Resource": "arn:aws:secretsmanager:ap-northeast-1:<ACCOUNT_ID>:secret:ragqa/prod/app-*"
}
]
}
下一步準備 Dockerfile 以及 GitHub Workflow (詳見 GitHub Repo):
# syntax=docker/dockerfile:1.7
# ── Base ──────────────────────────────────────────────────────────────────────
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1 \
PIP_NO_CACHE_DIR=1
# 科學運算常見依賴(FAISS/NumPy)
RUN apt-get update && apt-get install -y --no-install-recommends \
libgomp1 curl \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
# ── 固定 UID/GID,避免主機掛載目錄的權限問題 ────────────────────────────────
ARG APP_UID=10001
ARG APP_GID=10001
RUN groupadd -g $APP_GID appuser && useradd -m -u $APP_UID -g $APP_GID appuser
# 先安裝依賴(仍以 root 進行)
COPY requirements.txt .
# 使用 BuildKit 的快取掛載,跨 workflow 也能命中;並偏好 wheels
RUN --mount=type=cache,target=/root/.cache/pip \
python -m pip install -U pip setuptools wheel && \
pip install --prefer-binary -r requirements.txt
# 複製程式;可直接用 --chown 減少後續 chown 成本(需要較新 Docker 版本)
COPY --chown=appuser:appuser app ./app
# 建立資料目錄並調整權限(同時把 /app 也交給非 root)
RUN mkdir -p /data && chown -R appuser:appuser /data /app
# 切換為非 root
USER appuser
# ── 預設環境參數 ────────────────────────────────────────────────────────────
ENV APP_ENV=dev \
PORT=8080 \
HEALTH_PATH=/healthz \
LOG_LEVEL=info \
WORKERS=2
EXPOSE 8080
# ── 健康檢查 ─────────────────────────────────────────────────────────────────
HEALTHCHECK --interval=30s --timeout=3s --retries=3 \
CMD sh -c 'curl -fsS "http://127.0.0.1:${PORT:-8080}${HEALTH_PATH:-/healthz}" || exit 1'
# ── Gunicorn + UvicornWorker 啟動 ────────────────────────────────────────────
CMD ["bash","-lc","exec gunicorn -k uvicorn.workers.UvicornWorker -w ${WORKERS:-2} -b 0.0.0.0:${PORT:-8080} app.main:app --log-level ${LOG_LEVEL:-info}"]
在 workflow.yaml 可以透過快取的方式加快打包的時間,還有節省網路流量;使用 GitHub Private Repo 有關的話會需要注意這些。
# 建置 Docker image 並推送到 GHCR
- name: Build & Push (arm64) with cache
uses: docker/build-push-action@v6
with:
context: ./backend
file: ./backend/Dockerfile
platforms: linux/arm64/v8 # 因為 EC2 是 ARM 架構
push: true
tags: |
${{ steps.vars.outputs.TAG_LATEST }}
cache-from: |
type=registry,ref=${{ steps.vars.outputs.TAG_LATEST }}-buildcache
type=gha
cache-to: |
type=registry,ref=${{ steps.vars.outputs.TAG_LATEST }}-buildcache,mode=max
type=gha,mode=max
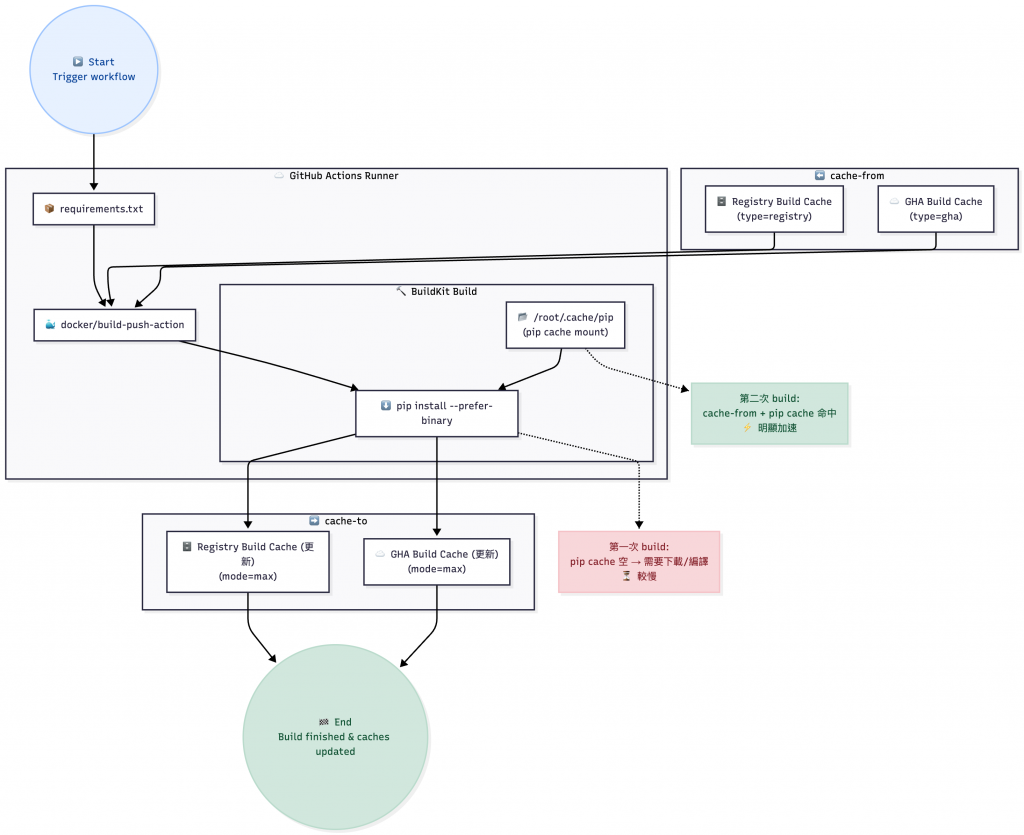
GitHub Workflow Build Cache Flow
第一次打包,花費十一分鐘:
第二次打包,七秒 結束:
在 GitHub Actions 分頁確認部署結果: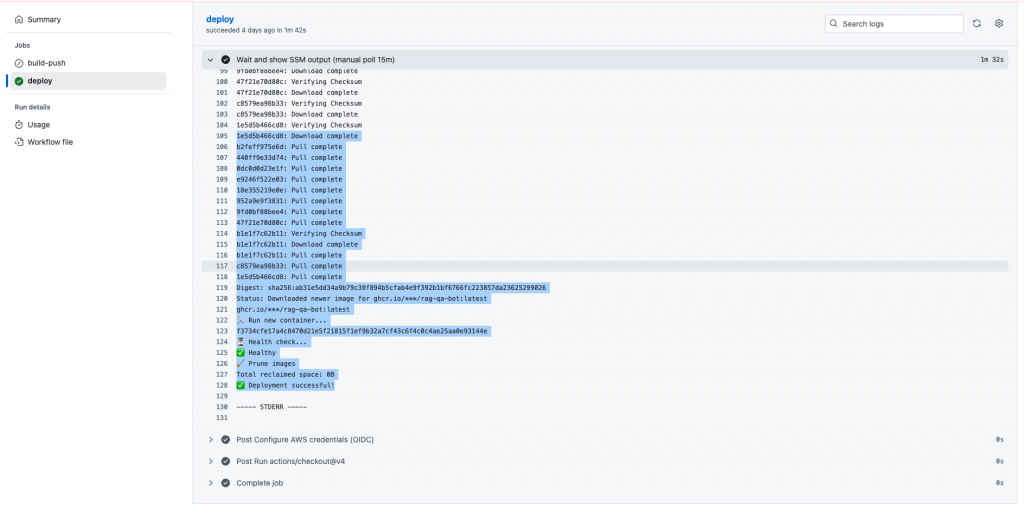
最後在 EC2 上面確認成功部署並且啟動,或是可以在 workflow.yaml 回傳執行結果:
[root@ip-172-31-100-152 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f4a907a42371 ghcr.io/hazel-shen/rag-qa-bot:latest "bash -lc 'exec guni…" 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp rag-qa-bot
[root@ip-172-31-100-152 ~]# docker logs f4a
[2025-09-27 06:56:46 +0000] [1] [INFO] Starting gunicorn 23.0.0
[2025-09-27 06:56:46 +0000] [1] [INFO] Listening at: http://0.0.0.0:8080 (1)
[2025-09-27 06:56:46 +0000] [1] [INFO] Using worker: uvicorn.workers.UvicornWorker
[2025-09-27 06:56:46 +0000] [9] [INFO] Booting worker with pid: 9
[2025-09-27 06:56:46 +0000] [10] [INFO] Booting worker with pid: 10
[cache] Using Redis backend @ redis://XXXXX-ro.XXXXX.ng.0001.apne1.cache.amazonaws.com:6379/0[cache] Using Redis backend @ redis://demo-redis-ro.XXXXX.ng.0001.apne1.cache.amazonaws.com:6379/0
[2025-09-27 06:57:33 +0000] [9] [INFO] Started server process [9]
[2025-09-27 06:57:33 +0000] [10] [INFO] Started server process [10]
[2025-09-27 06:57:33 +0000] [9] [INFO] Waiting for application startup.
[2025-09-27 06:57:33 +0000] [10] [INFO] Waiting for application startup.
[2025-09-27 06:57:33 +0000] [10] [INFO] Application startup complete.
[2025-09-27 06:57:33 +0000] [9] [INFO] Application startup complete.
最後確認在 EC2 上面可以呼叫 API:
[root@ip-172-31-100-152 ~]# curl -s -X POST http://127.0.0.1:8080/ask \
-H "Content-Type: application/json" \
-d '{"query": "LLM 相關指標包 含哪些?"}' | jq .
{
"answer": "LLM 相關指標包含:llm_requests_total、llm_request_latency_seconds、llm_tokens_total、llm_cost_total_usd。",
"meta": {
"cached": true,
"context_preview": "[architecture.md] # FAQ Bot 系統架構設計 ## 整體流程 1. 使用者透過前端輸入問題 2. 問題經過向量化(Embedding) 3. 系統到向量資料庫檢索相似片段 4. 檢索到的內容會被拼接進 Prompt 5. 大語言模型 (LLM) 生成回答 6. 回答回傳給使用者 ## 元件細節 ### 前端 (Frontend) - 提供使用者輸入框與回覆區域 - 可內嵌在內部 Portal - 與 Backend API 溝通 ### 後端 (Bac",
"sources": [
{
"id": "/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md::chunk-0",
"title": "architecture.md",
我想特別提一下因為把機器壓到較為便宜規格 (2vCPU / 4 GB memory) 的關係,為了穩定運行必須要加入很多參數犧牲吞吐量來降低記憶體的使用量,不然會發現部署上去連 ssm-agent 都連不進去,直接 OOM(Out-Of-Memory)。
然而實際上會需要依照真實環境規格(Which is 錢包深度)來調整這些變數。
# ops/deploy_container.sh
...
...
if ! docker run -d --name "$CONTAINER_NAME" \
--restart always \
-p "${PORT}:${PORT}" \
-v "${DATA_DIR_HOST}:/data" \
-e "PORT=${PORT}" \
-e "APP_ENV=${APP_ENV}" \
$( [ -n "$AWS_SECRETS_ID" ] && echo -e "-e AWS_SECRETS_ID=${AWS_SECRETS_ID}" ) \
-e "WEB_CONCURRENCY=1" \
-e "GUNICORN_CMD_ARGS=--workers 1 --threads 1 --timeout 180 --graceful-timeout 30 --keep-alive 30" \
-e "OMP_NUM_THREADS=1" -e "OPENBLAS_NUM_THREADS=1" -e "MKL_NUM_THREADS=1" -e "NUMEXPR_NUM_THREADS=1" \
-e "TOKENIZERS_PARALLELISM=false" -e "TORCH_NUM_THREADS=1" \
--log-driver json-file \
--log-opt max-size=10m \
--log-opt max-file=3 \
"$IMAGE"
...
...
| 類別 | 參數 | 作用 | 何時使用 | 對資源 / 穩定性影響 | 建議值 / 備註 |
|---|---|---|---|---|---|
| 應用層(Gunicorn/Uvicorn) | WEB_CONCURRENCY=1 |
多數樣板用來決定 Gunicorn workers 數 |
小機型、模型常駐、記憶體吃緊 | RAM ↓ 大幅下降(只載一份模型),吞吐量下降 | 1 |
| 應用層(Gunicorn/Uvicorn) | GUNICORN_CMD_ARGS="--workers 1 --threads 1 --timeout 180 --graceful-timeout 30 --keep-alive 30" |
強制單工與超時/連線行為 | 冷啟/載模較久、避免超時誤殺 | RAM ↓、延遲更穩;吞吐量較低 | workers=1, threads=1; timeout 可 90–180 視情況 |
| 數值/ML 底層 | TORCH_NUM_THREADS=1 |
限制 PyTorch CPU 執行緒 | 有 PyTorch/CrossEncoder 推理時 | CPU 抖動↓、RAM 波動↓ | 1(多數 API 夠用) |
| 數值/ML 底層 | TOKENIZERS_PARALLELISM=false |
關閉 HF tokenizers 多工 | 用 transformers/sentence-transformers |
日誌更乾淨、資源爭用↓ | false |
| 數值/ML 底層 | OMP_NUM_THREADS=1 |
限制 OpenMP 執行緒 | ARM/Graviton、FAISS、ONNX、NumPy | CPU/RAM 峰值↓、更穩定 | 1 |
| 數值/ML 底層 | OPENBLAS_NUM_THREADS=1 |
限制 OpenBLAS 執行緒 | ARM/Graviton、NumPy/Scipy | CPU/RAM 峰值↓ | 1 |
| 數值/ML 底層 | MKL_NUM_THREADS=1 |
限制 MKL 執行緒 | x86 + MKL 場景 | CPU/RAM 峰值↓ | 1(用到 MKL 再加) |
| 數值/ML 底層 | NUMEXPR_NUM_THREADS=1 |
限制 numexpr 執行緒 | 只有用到 numexpr 才需要 |
CPU/RAM 峰值↓ | 1(用到再加) |
| Docker 日誌 | --log-driver json-file |
改用 json 檔記錄 stdout/stderr(不走 journald) | journald 造成 RAM 壓力或想要本機 docker logs |
RAM 壓力↓、路徑可控 | 建議明確指定 |
| Docker 日誌 | --log-opt max-size=10m |
單檔最大 10MB | 高 log 量 | 磁碟占用受控、避免 I/O 背壓 | 依需調整(如 10m) |
| Docker 日誌 | --log-opt max-file=3 |
保留 3 份輪轉檔 | 高 log 量 | 磁碟占用受控 | 依需調整(如 3) |
觀察 docker 的 CPU / Memory 使用量:
[root@ip-172-31-100-152 ~]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5ec8074ac149 rag-qa-bot 0.89% 1.428GiB / 3.746GiB 38.12% 1.55GB / 12.7MB 843MB / 4.59GB 14
觀察作業系統的 CPU / Memory 使用量:
[root@ip-172-31-100-152 ~]# top
top - 08:22:50 up 2:00, 1 user, load average: 0.00, 0.19, 0.59
Tasks: 143 total, 1 running, 142 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.2 si, 0.2 st
MiB Mem : 3835.7 total, 113.1 free, 1598.2 used, 2124.4 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2063.4 avail Mem
重點解讀如下:
Gunicorn 常駐記憶體:RES 715,440 KB ≈ 0.7 GB(PID 38539,使用者 10001)
→ 這大致就是你模型+程式的實際常駐用量。
容器 / 系統總記憶體:
Mem: total 3.7 GB, used 1.6 GB, buff/cache 2.1 GB, free 113 MB, avail 2.0 GB
free 很小不代表快沒記憶體,看 available(2.0 GB)才準。CPU 很閒:%CPU us 0.3 / load average 0.00–0.60,單工設定下很合理。
沒開 swap:Swap: 0.0 total
→ 沒有備援空間時,若瞬間尖峰超過 3.7 GB,OOM Killer 仍可能出手。
🤔 為什麼看到「docker stats ≈ 1.4 GB」但 top 只有 0.7 GB?
Docker 看到的是容器的總記憶體消耗(含 page cache、allocator overhead 等),而top的那個 GunicornRES只算「該進程的常駐頁」。兩者差了 ~0.7 GB,**多半是檔案快取(讀模型檔、依賴、log)**與一些共享/對齊開銷,正常且可回收。
swapfile(①–④),設定開機自動啟用(⑤),把 swappiness 調低(⑥)讓系統只在必要時才用 swap,最後檢查生效(⑦)。步驟如下:
# ① 嘗試用 fallocate 建 2GB 的 /swapfile;若系統/檔案系統不支援就退回用 dd 逐區塊寫入
sudo fallocate -l 2G /swapfile || sudo dd if=/dev/zero of=/swapfile bs=1M count=2048 status=progress
# ② 安全性:swapfile 權限必須是 600(只有 root 可讀寫),否則 swapon 會拒絕
sudo chmod 600 /swapfile
# ③ 把這個檔案格式化成 swap 區
sudo mkswap /swapfile
# ④ 立刻啟用 swap(不用重開機)
sudo swapon /swapfile
# ⑤ 寫進 fstab,讓開機自動掛載 swapfile
echo '/swapfile swap swap defaults 0 0' | sudo tee -a /etc/fstab
# ⑥ 把 swappiness 調低到 10:盡量先用 RAM,必要時才把不常用頁面換到 swap
echo 'vm.swappiness=10' | sudo tee /etc/sysctl.d/99-swappiness.conf
sudo sysctl --system # 立即套用 sysctl 設定
# ⑦ 驗證目前 RAM/Swap 狀態
free -h
swapon --show
# 重開機自動掛載
grep -n '/swapfile' /etc/fstab
# 關閉 swap 並且從開機自動啟動檔案移除
sudo swapoff /swapfile
sudo sed -i '\|/swapfile swap swap|d' /etc/fstab
sudo rm -f /swapfile
以下是 Cloudflare Pages 要設定的變數,這些變數都會透過 Cloudflare Functions 帶到後端:
| 變數名稱 | 說明 | 範例值 | 建議類型 |
|---|---|---|---|
| PAGES_SECRET | Pages → Worker 的身份驗證密鑰。Worker 會檢查 x-from-pages header 是否等於這個值。 |
openssl rand -hex 32 產生的隨機字串 |
Secret |
| CF_ACCESS_CLIENT_ID | Cloudflare Access Service Token 的 Client ID,用來讓 Pages 代表使用者存取 Worker。 | 由 Access 產生的值 | Secret |
| CF_ACCESS_CLIENT_SECRET | Cloudflare Access Service Token 的 Client Secret。 | 由 Access 產生的值 | Secret |
| RL_LIMIT | 每個使用者在一個視窗內允許的最大請求數。 | 100 |
普通環境變數 |
| RL_WINDOW | 視窗大小(秒),例如 3600 = 1 小時。 |
3600 |
普通環境變數 |
| RL_HEALTHZ | 是否對 /api/healthz 也做限流。false = 不限流(預設),true = 限流。 |
false |
普通環境變數 |
PAGES_SECRET、CF_ACCESS_CLIENT_SECRET 這些值存在 環境變數/綁定,不會被打包進前端 JS,也不會自動出現在回應。只有在 Functions 端你主動讀取並使用。_proxy.js 把 x-from-pages、Access Token 等 在 Edge 端加入到「往 Worker 的請求」,瀏覽器開開 F12 只會看到它自己發出的請求標頭,看不到這些伺服端追加的內部標頭。console.log、回應 body、或 Access-Control-Expose-Headers。x-from-pages),就算外部有人能打到 Worker 也會被擋在外面。在 Cloudflare Function 中,我會利用下方的函式實作 Rate Limit,Rate Limit 是利用 Cloudflare Workers KV 以「使用者識別鍵(例如 email/ID/IP)」當作 key,記錄一個小型計數 Object { n, reset }:
n(目前「固定視窗」中的累計次數)加 1;超過上限即回 429 Too Many Requests,並附上 Retry-After 與 X-RateLimit-* 標頭,通過時也會回傳剩餘額度。RL_LIMIT(預設 100)、RL_WINDOW(秒,預設 3600)、RL_HEALTHZ(是否對 /api/healthz 限流)。⚠️ KV 屬於「最終一致性」,意味著在極端併發下可能出現短暫的計數誤差,但對於每用戶、每分鐘等粗粒度限流相當實用。若要強一致/高併發的精準配額,建議改用 Durable Objects 當計數中樞。
// frontend/functions/_middleware.js
// Rate Limit
async function applyRateLimit(env, key) {
const limit = parseInt(env.RL_LIMIT || "100", 10);
const windowSec = parseInt(env.RL_WINDOW || "3600", 10);
const now = Date.now();
let rec;
const raw = await env.RATELIMIT_KV.get(key);
if (raw) { try { rec = JSON.parse(raw); } catch { rec = null; } }
if (!rec || typeof rec.reset !== "number" || now >= rec.reset) {
const reset = now + windowSec * 1000;
rec = { n: 1, reset };
await env.RATELIMIT_KV.put(key, JSON.stringify(rec), { expirationTtl: windowSec + 5 });
return { allowed: true, retryAfterSec: 0, limit, remaining: limit - 1, resetAt: Math.ceil(reset / 1000) };
}
if (rec.n >= limit) {
const retryAfterSec = Math.max(1, Math.ceil((rec.reset - now) / 1000));
return { allowed: false, retryAfterSec, limit, remaining: 0, resetAt: Math.ceil(rec.reset / 1000) };
}
rec.n += 1;
const remainSec = Math.max(1, Math.ceil((rec.reset - now) / 1000));
await env.RATELIMIT_KV.put(key, JSON.stringify(rec), { expirationTtl: remainSec + 5 });
return { allowed: true, retryAfterSec: 0, limit, remaining: limit - rec.n, resetAt: Math.ceil(rec.reset / 1000) };
}
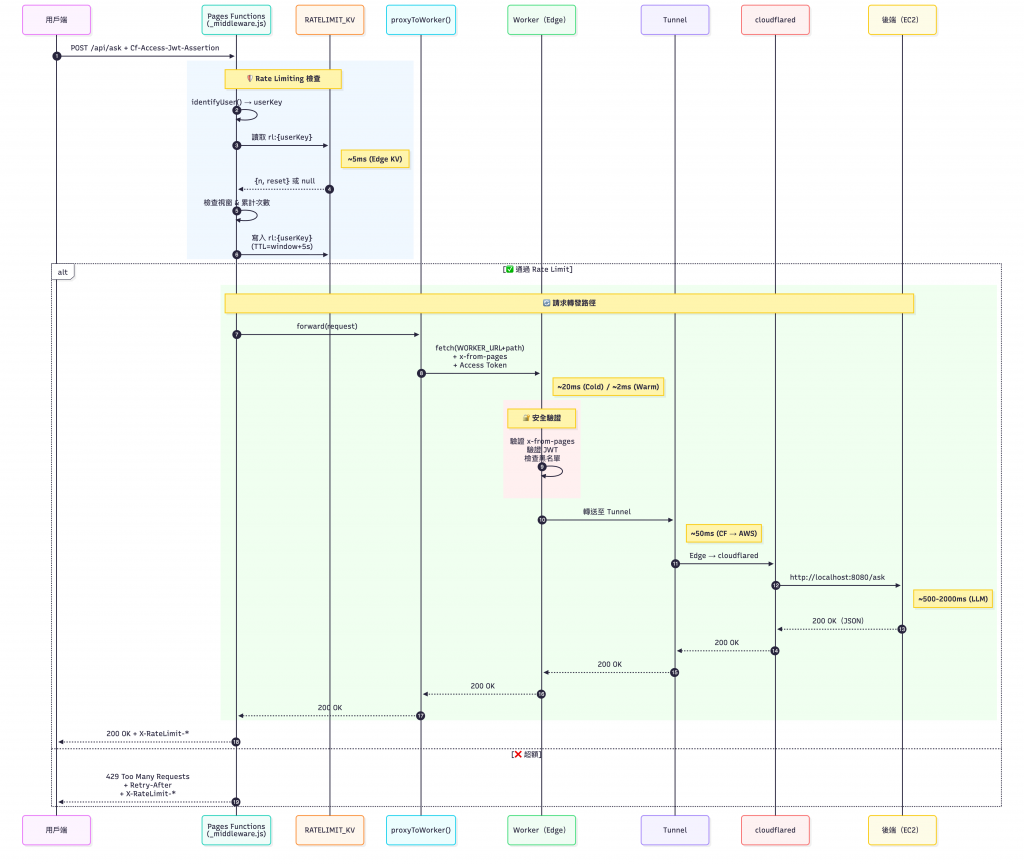
從前端頁面經由 /ask 到後端 EC2 的完整時序圖(Sequential Diagram)如下:
如果有讀者部署 Functions 時跟我一樣遇到了錯誤:
|22:56:42.416|Validating asset output directory|
|22:56:45.212|Deploying your site to Cloudflare's global network...|
|22:56:47.042|Failed: an internal error occurred. If this continues, contact support: https://cfl.re/3WgEyrH|
|22:56:47.040|Error: Failed to publish assets. For support, join our Discord (https://discord.gg/cloudflaredev) or create a ticket and reference the deployment ID: c5c59fcb-19c0-47c5-a064-37c3b1b874d6|
我當時是在 Cloudflare 的官方論壇 看到有人和我遇到一樣的問題,一樣需要仔細的看 Cloudflare 的官方文件。需要檢查一下 _routes.json 的格式是否符合官方標準:
{
"version": 1, // version 不加上去的話會部署失敗。
"include": ["/*"],
"exclude": []
}
⚠️ 此處使用
cloudflared tunnel --url是 臨時方案,僅用於快速驗證連通性,正式環境還是需要綁定正式域名。
在 EC2 上啟動臨時 Tunnel:
cloudflared tunnel --url http://127.0.0.1:8080
在 Console 可以看到一組 Cloudflare 給你的臨時網域,把這個網域更新到 Worker 端的環境變數,就可以讓 Cloudflare Worker 連接到 EC2。
確認 worker 可以透過暫時打的 Cloudflare Tunnel 連到 EC2:
❯ curl -X POST https://XXX.XXX.workers.dev/ask \ -H "CF-Access-Client-Id: $CF_ACCESS_CLIENT_ID" \
-H "CF-Access-Client-Secret: $CF_ACCESS_CLIENT_SECRET" \
-H "x-from-pages: $WORKER_SHARED_SECRET" \
-H "Content-Type: application/json" \
-d '{"query": "請問專案在做什麼?"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1853 100 1815 100 38 49 1 0:00:38 0:00:36 0:00:02 499
curl: (3) URL rejected: Malformed input to a URL function
{
"answer": "專案的主要目的是協助企業將知識數位化,並透過 AI 技術提升內部資訊檢索的效率。",
修改一下 _routes.json 檔案,格式絕對要參考官方文件,不然連部署都會失敗😭😭😭😭😭
{
"version": 1,
"include": ["/api/*"],
"exclude": []
}
終於呼叫成功了 ✨
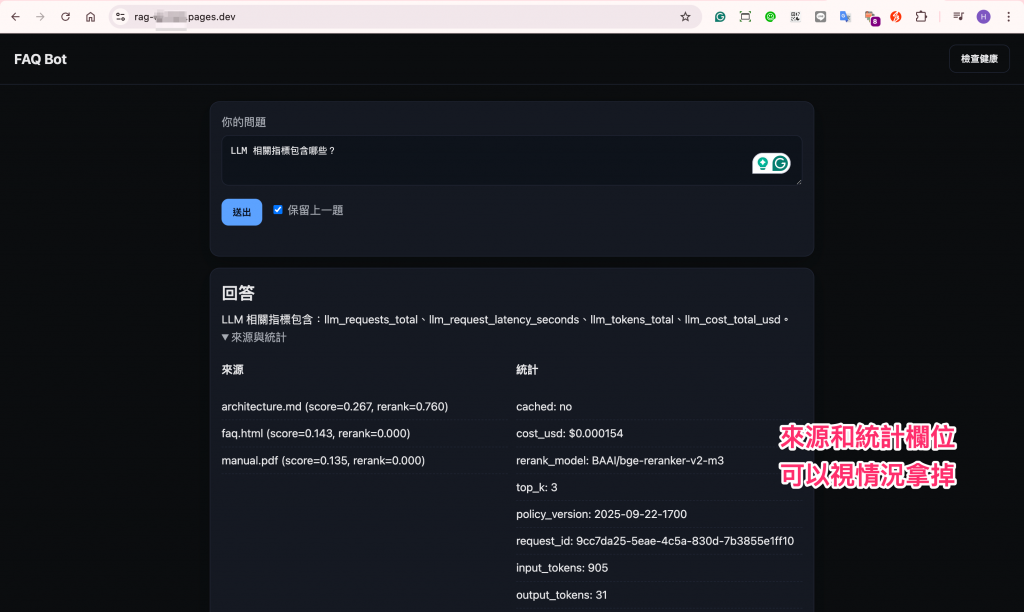
最後要來處理監控的部分了,今天我們要把 Grafana Alloy 安裝到 EC2,並且讓它能夠常駐運行、把 metrics 送到昨天已經申請和測試好了的 Grafana Cloud 帳號。
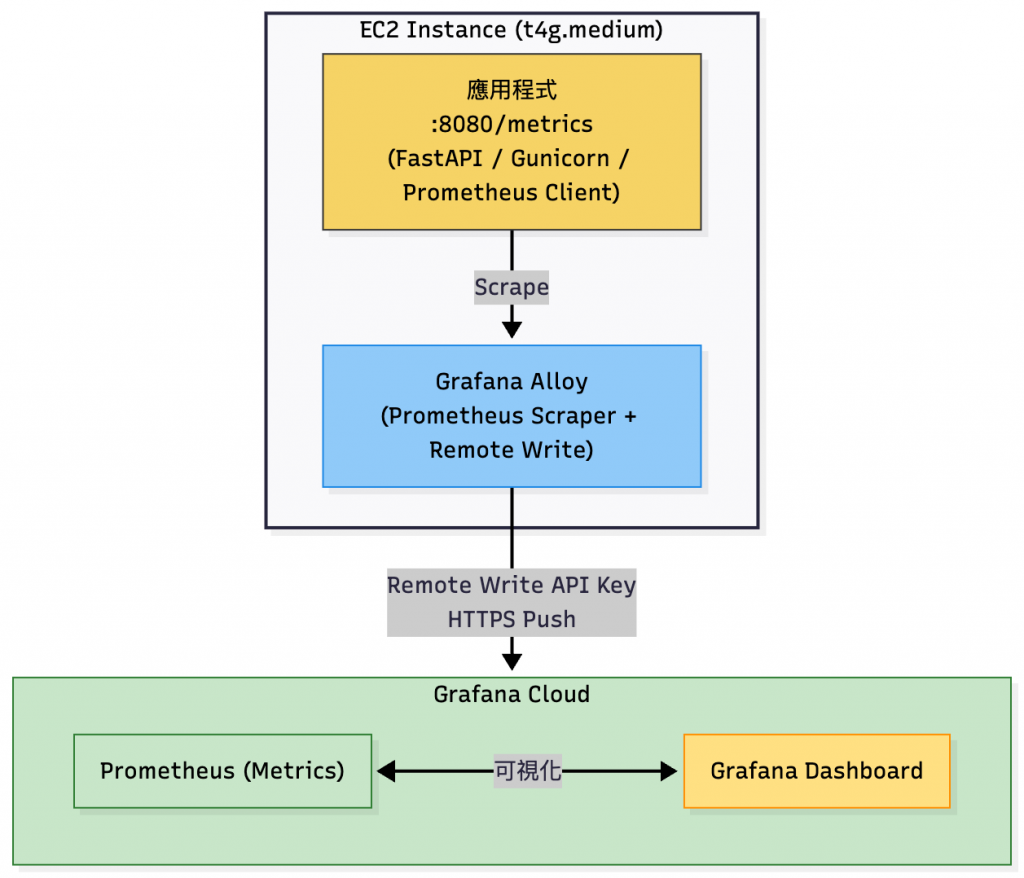
Metrics 傳送到 Grafana Cloud 流程架構
先到官方頁面下載 Alloy 並安裝(這個指令會在 https://${你的帳號}.grafana.net/a/grafana-collector-app/alloy/installation 產生),我會建議你在這個頁面產生新的 API_TOKEN,這樣出來的 API Scoped 就會是正確的:
GCLOUD_HOSTED_METRICS_ID="${你的-stack-id}" GCLOUD_HOSTED_METRICS_URL="https://prometheus-prod-49-prod-ap-northeast-0.grafana.net/api/prom/push" GCLOUD_HOSTED_LOGS_ID="${Logs Instance ID (會自動生成)}" GCLOUD_HOSTED_LOGS_URL="https://logs-prod-030.grafana.net/loki/api/v1/push" GCLOUD_FM_URL="https://fleet-management-prod-019.grafana.net" GCLOUD_FM_POLL_FREQUENCY="60s" GCLOUD_FM_HOSTED_ID="${FM Instance ID}" ARCH="amd64" GCLOUD_RW_API_KEY="${剛剛產生的 API Token (會自動生成)}" /bin/sh -c "$(curl -fsSL https://storage.googleapis.com/cloud-onboarding/alloy/scripts/install-linux.sh)"
裝完之後可以確認版本:
alloy --version
在 /etc/alloy/config.alloy 新增設定檔:
# /etc/alloy/config.alloy
prometheus.remote_write "to_grafana" {
endpoint {
url = "https://prometheus-prod-49-prod-ap-northeast-0.grafana.net/api/prom/push"
basic_auth {
username = "${你的-stack-id}"
password = "${剛剛產生的 API Token}"
}
}
}
prometheus.scrape "app" {
targets = [
{ __address__ = "127.0.0.1:8080" },
]
scrape_interval = "30s"
scrape_timeout = "10s"
forward_to = [prometheus.remote_write.to_grafana.receiver]
}
⚠️ 注意:
url 請用你 Grafana Cloud 提供的 Remote Write endpoint。username = Instance ID(數字)password = API Key(建議產生一個 Scoped API Key)。Alloy 預設會裝好 systemd service:/usr/lib/systemd/system/alloy.service。
但是它預設會以 alloy 使用者啟動,導致 /var/lib/alloy 權限問題,需要手動調整。
新增 override 設定:
sudo systemctl edit alloy.service
寫入:
[Service] User=alloy Group=alloy
這會建立 /etc/systemd/system/alloy.service.d/override.conf。
sudo chown -R alloy:alloy /var/lib/alloy
sudo systemctl daemon-reload
sudo systemctl restart alloy.service
sudo systemctl enable alloy.service
查看日誌:
journalctl -u alloy.service -f
如果看到類似這樣代表推送成功:
level=info msg="Done replaying WAL" component_id=prometheus.remote_write.to_grafana
如果錯誤訊息是 401 Unauthorized,檢查 API Key 是否正確。
如果錯誤是 permission denied,檢查 /var/lib/alloy 的擁有者是否正確。
可以到 Grafana Console Dashboard 在 Explorer 分頁查看送過去的 Metrics:
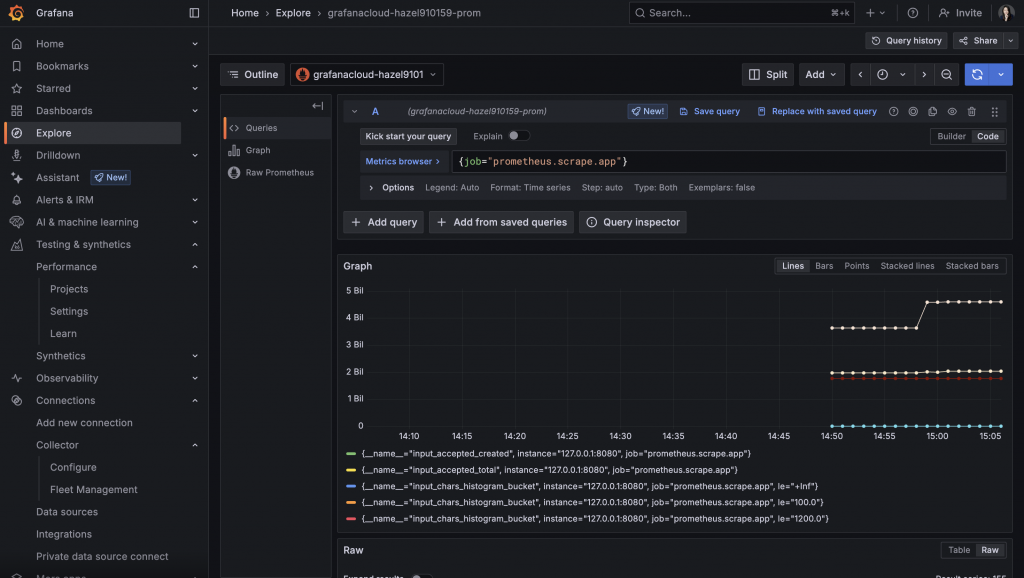
最後 Import Dashboard JSON 檔案後,確認 Grafana Dashboard 可以看到圖表:
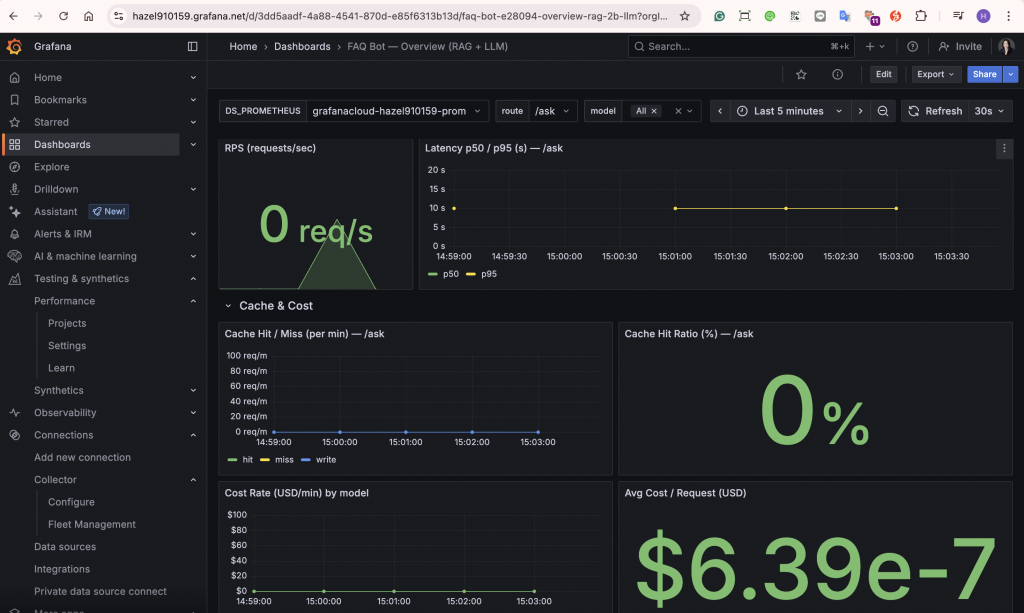
以 東京區(ap-northeast-1) 的配置完整跑 24 小時,AWS 花費 ≈ USD $1.86/天。
換算月額(以 30 天估):$1.86 × 30 ≈ $55.8/月,與 Day28「極輕量 Demo」預估的 $55.7~$63 區間一致(此處 不含出網流量;有 egress 時依實際用量另計)。
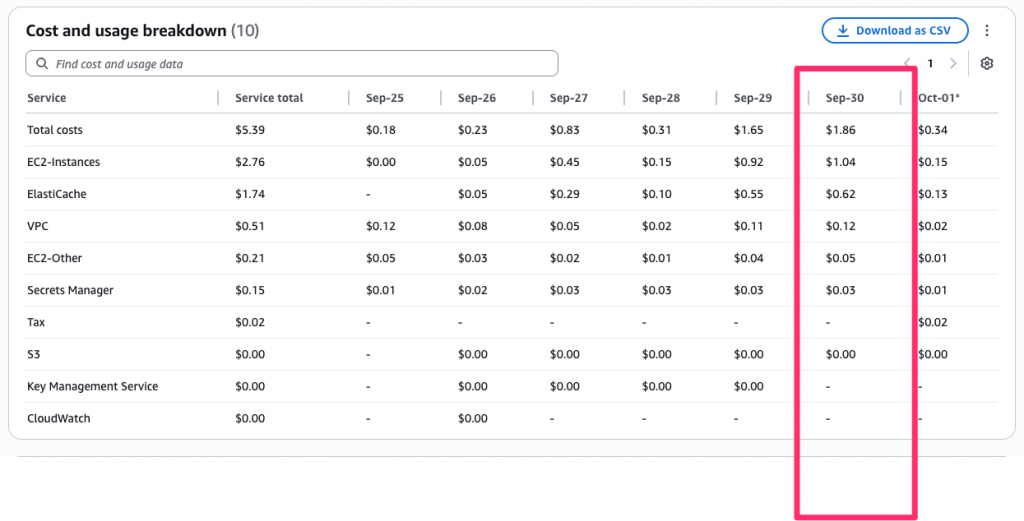
💡 若要把費用再往下壓:
・移除公網 IPv4 (流量大適用)
・換較便宜區域(us-east-1),我會選擇東京是因為這個專案是直接面向使用者的查詢 API
・RI / Savings Plans
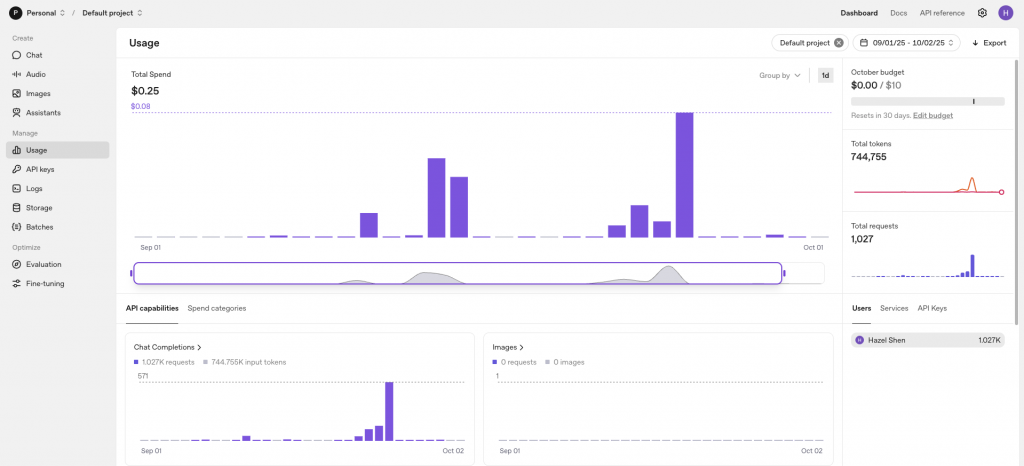
以下是 OpenAI 的後台帳單明細,可以看到在我的本系列的鐵人賽展示情況下使用的 tokens 並不是到太高,加上有快取的幫忙,所以可以節省大量的 tokens 費用。
Day29 的重點在於 把理論轉換成實際部署。從前幾天的理論介紹、環境評估、架構設計,到今天實際將程式放到 AWS,等於完成了「從白板圖到可運行服務」的最後一步。**過程中,我們也透過實際跑一天的 AWS 帳單($1.86/天 ≈ $55.8/月)驗證了 Day28 的成本預估、也證明了支出合理性。
然而,目前的設計仍有一些限制,例如僅依賴單一 EC2、使用臨時 Cloudflare Tunnel、IAM 與 Secrets 管理尚未完善,以及監控層缺乏警報與集中式日誌。這些問題在流量極小的現階段是可接受的,若要真正走向生產環境,則需要更高的可靠性(HA)與治理能力。
Day30,也是本系列的最後一天:我會從架構、安全與監控三個面向,討論如何把專案從小規模演進到 高可用、安全強化與成本改善 的 Production-Ready 設計藍圖,作為本系列鐵人賽的收尾及總結。
json-file 日誌驅動:max-size / max-file 參數說明

