在解析html檔時,我們首先需要了解兩個概念,第一個是html標籤,這個部分也是組成網頁的最主要部分,第二個是定位html標籤的方法selector以及Xpath,這兩個工具可以幫助你在html檔中快速找到你要的網頁資訊。如果已經對撰寫html檔有所了解,請拿捏收看。
這個部分我只說幾個重要的元素,如果你是html的初學者,必須注意每一個tag的功能,在爬蟲的應用上通常會特別注意「是否為表單元素」,如果是表單元素,有價值的資訊並不像其他元素,用一組html tag包起來,而是放在tag中的value屬性。其他,比較詳細的教材,可以看W3school。
<h1>This is a heading</h1>
<h6>This is a heading</h6>
<p>This is a paragraph.</p>
<a href="http://www.w3school.com.cn">This is a link</a>
# 注意href是a元素的「屬性」,裡面的網址若沒有http開頭,一般都是使用跟你所在網頁相同的網域(domain),詳見下面的圖片解釋。
<div></div>
#這幾年比較新設計的網頁,一般都是使用這個元素做頁面分割的,雖然本身不含有重要的資訊,但是在定位元素時,會很常需要繞過div
<img style="padding-top:112px" height="92" src="/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png" width="272" alt="Google" id="hplogo" title="Google" onload="google.aft&&google.aft(this)">
# 此圖片中的img使從google首頁擷取下來的,style, height, width...都是這元素的屬性。而google的網域是https://www.google.com.tw/,因此你可以透過https://www.google.com.tw/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png,找到google標誌的圖片,

<form>
<input type="text" name="firstname">
<input type="radio" name="sex" value="male" checked>Male
<input type="submit" value="Submit">
</form>
<table>
<thead>
<tr><th></th><th></th></tr>
</thead>
<tbody>
<tr><td></td><td></td></tr>
</tbody>
</table>
上面講了主要組成網頁的基本元素,接下來要講的是,讓電腦可以找到特定元素的方法。這邊只簡單講概念,詳細部分,selector請看W3school,Xpath請看W3school。
這個部分因為實在太複雜,只說幾個重要的,我知道大家看完還是霧煞煞,別著急,下面我們會跟著python套件一起示範使用方式。
舉台北大學課程檢索頁面為例: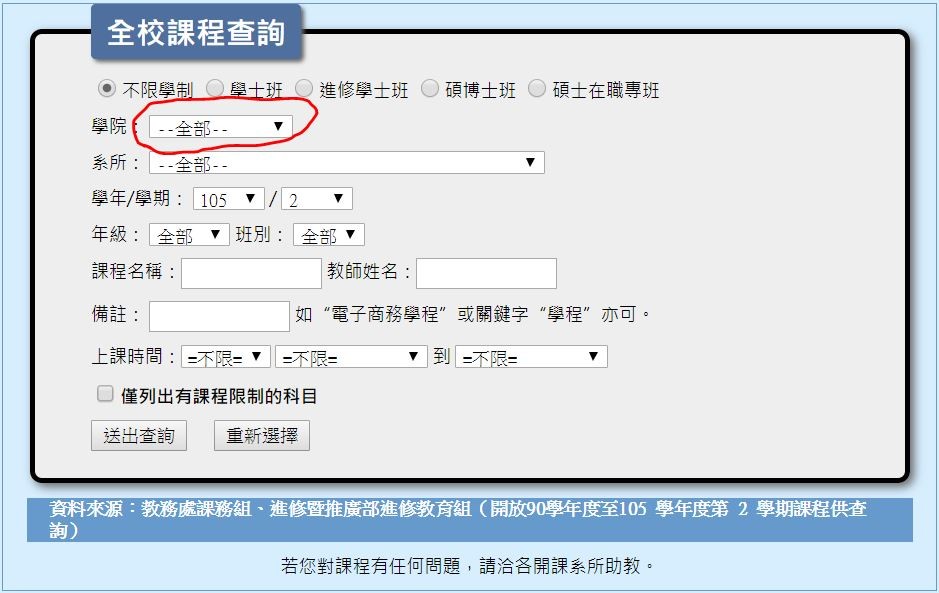
進入頁面後按下F12,如果是使用chrome,左上角會找到一個元素選擇器,透過選擇器去網頁上面點選特定的元素,瀏覽器就能自動幫你定位出他在html中的位置。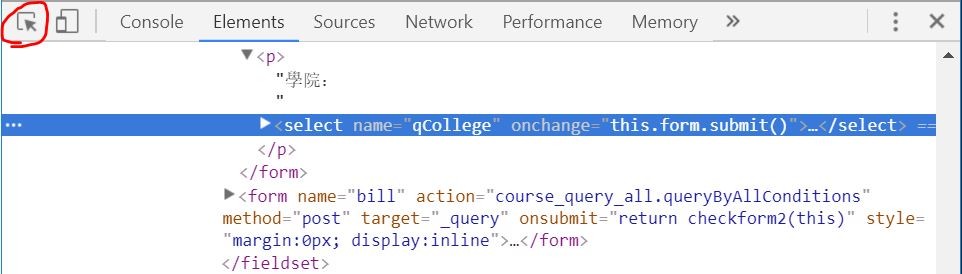
此時,在元素上面點擊右鍵>copy>copy selector,就可以取得這個元素的Selector:
body > center > table > tbody > tr > td > table > tbody > tr:nth-child(1) > td > fieldset > form:nth-child(2) > p > select
不過請注意,nth-child這個功能在下面要介紹的拆解html的python套件BeautifulSoup中並沒有被實作,也就是這個套件無法處理這樣的語法,因此必須透過其他解決方案,來處理這個元素。
這個概念就比較簡單,html檔案是巢狀結構,也就是一層包一層的結構,最上層的結構就是html,然後html裡面會包著head跟body,網頁中通常會直接被你看到的部分都包在body中。下面可能就會有很多div, h1~h6,或其他上述元素。
而所謂Xpath,就是透過,從最上層到最下層。每一層經過的tag名稱串接起來的定位器,承上例,將copy Selector改為copy Xpath即可得到:
/html/body/center/table/tbody/tr/td/table/tbody/tr[1]/td/fieldset/form[1]/p/select
首先必須說明的是,這個套件的底層是用正規表示式所寫成,早期一點的爬蟲玩家,大都必須比較辛苦的手刻正規表示式,現在大家就比較方便拉,詳情大家可以看他們的官網,以下我僅針對比較常用的幾個元素做簡單示範。
# 安裝
$ pip install bs4
# 一、把取得的html純文字送給BeautifulSoup,產生BeautifulSoup類別
from bs4 import BeautifulSoup
import requests
re = requests.get("https://www.crummy.com/software/BeautifulSoup/bs4/doc/")
soup = BeautifulSoup(re.text)
# 二、找到element
## 透過tag名稱尋找元素(第一個,回傳一個元素類別)
elem = soup.find('a')
print(elem)
print("----------------------------------")
## 透過tag名稱尋找元素(全部,回傳一個元素類別「陣列」)
elems = soup.find_all('a')
for elem in elems:
print(elem)
print("----------------------------------")
## 透過selector尋找元素(回傳一個元素類別「陣列」)
selector = "#quick-start > h1"
elem = soup.select(selector)
print(elem)
print("----------------------------------")
# 三、取出element中的重要資訊
## 取出element特定attribute的值
elem = soup.find('a')
print(elem)
print(elem['href']) ##方法一
print(elem.get('href')) ##方法二
print("----------------------------------")
## 取出一對tag間的文字
selector = "#quick-start > h1"
elem = soup.select(selector)
print(elem[0])
print(elem[0].text)
print("----------------------------------")
## 取得整個網頁的所有文字)
print(soup.get_text())
print("----------------------------------")
如果對於數據處理有興趣,非常推薦認真學一下pandas,這東西就是python中的excel,功能非常強大,解析html tag只是其中的一個小功能,後面會有一天的時間,完整的介紹pandas的表格操作功能。
另外,需特別提醒的是,pandas對於html中表格元素的容錯能力其實沒有大家想像的完美,所以如果遇到無法解決的狀況,還是建議大家先用BeautifulSoup處理好完整的table元素,再丟給pandas。
# 安裝
$ pip install pandas
import pandas as pd
url = "http://mops.twse.com.tw/server-java/t164sb01?step=1&CO_ID=1216&SYEAR=2017&SSEASON=1&REPORT_ID=C" ## 公開資訊觀測站的財報
dfs = pd.read_html(url) ## 回傳DataFrame類別的陣列
df = dfs[1]
print(df)
# 簡單的操作pandas教學
## 只查看前面五行
print(df.head(5))
## 查看所有的columns
columns = df.columns
print(columns)
## 僅查看取特定column
showColumns = [columns[0], columns[1]]
print(df[showColumns].head())
## 僅查看特定的row
print(df.xs(5)) ##不可指派內容
print(df.loc[5]) ##可指派內容
## 存檔
df.to_csv("{檔名}", index=False)
df.to_json("{檔名}")



 iThome鐵人賽
iThome鐵人賽