提醒: 本篇文章的code在這裡: Titanic
pandas好用的原因其中之一就是其索引的功能非常強大,相比於sql語法要敲一長串select <columns> from <table> where <column> == <value>,pandas的語法會比較像是df.loc[df['<column>']==<value>, <columns_list>],而且甚至索引出來就可以直接更改值,以下詳細示範。
# 根據row index進行索引
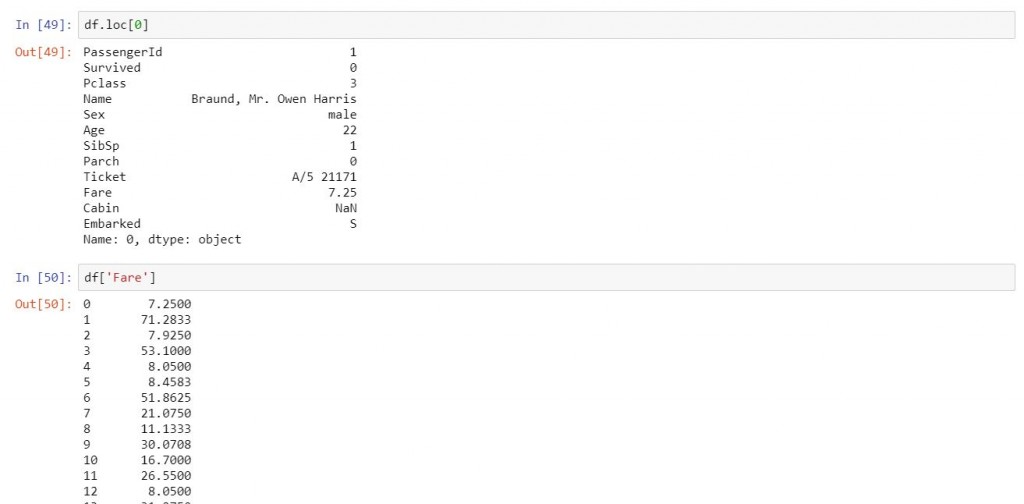
df.loc[0]
# 根據column index進行索引
df['Fare']
# 根據row index進行索引
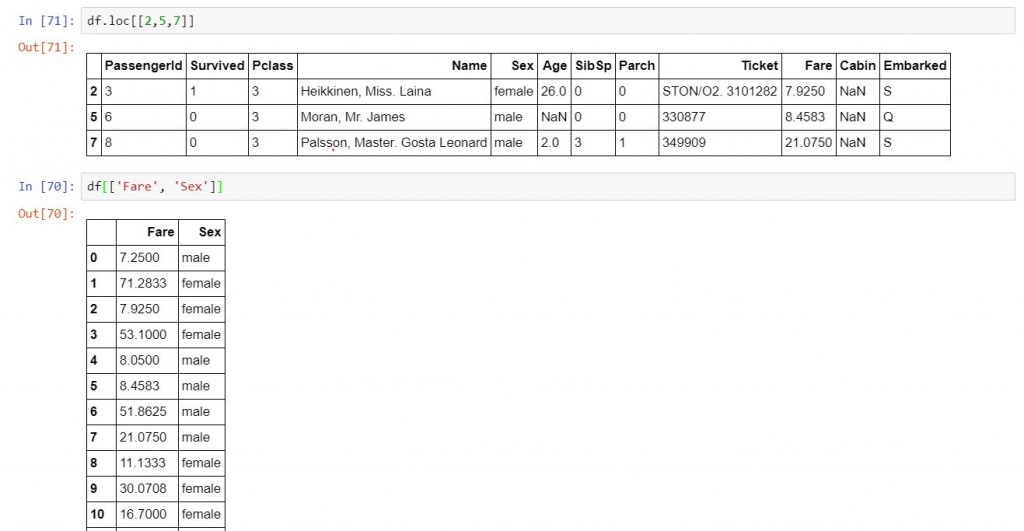
df.loc[[2,5,7]]
# 根據column index進行索引
df[['Fare', 'Sex']]
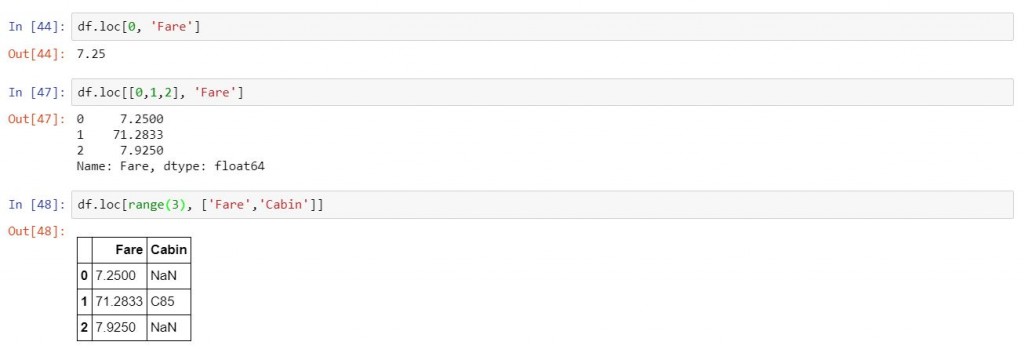
df.loc[<indices_list>, <columns_list>]中的運作邏輯,以下詳細示範。df.loc[0, 'Fare']
df.loc[[0,1,2], 'Fare']
df.loc[range(3), ['Fare','Cabin']]
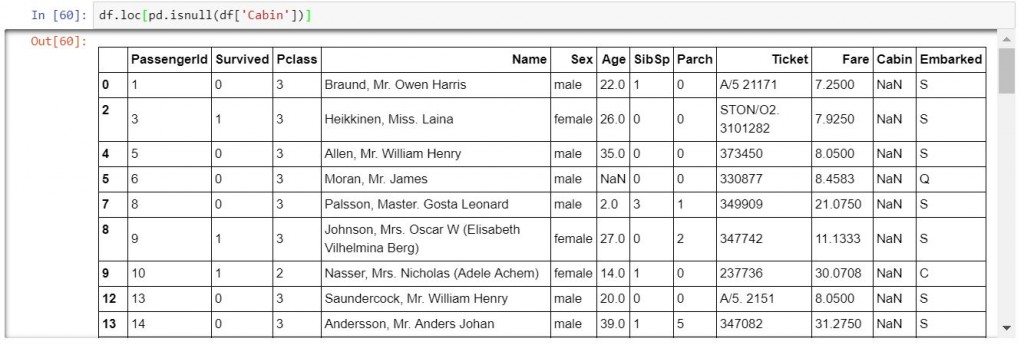
# show出Cabin是null值的
df.loc[pd.isnull(df['Cabin'])]
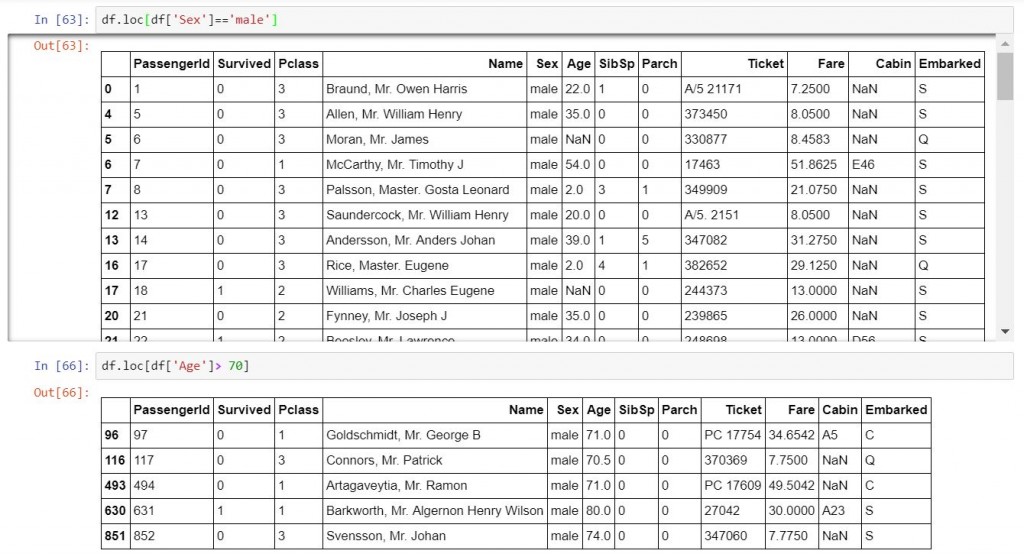
# show出Sex是male的
df.loc[df['Sex']=='male']
# show出Age大於70的
df.loc[df['Age']> 70]
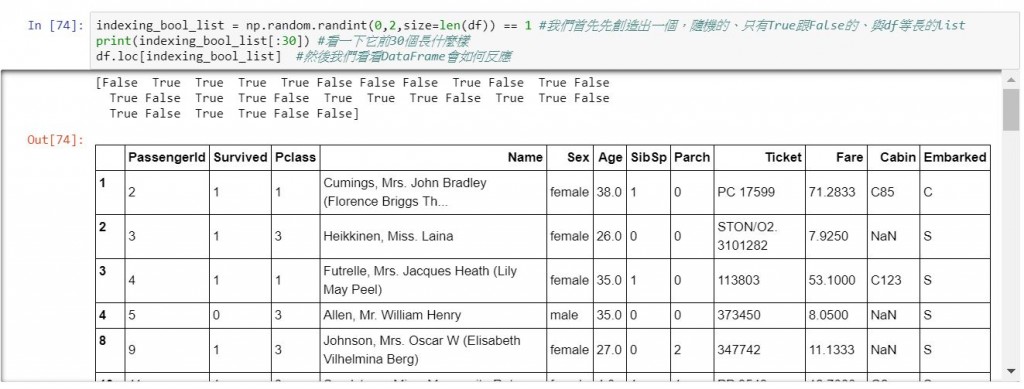
探究其內部運作邏輯,上面所送入的indices_list可以是一個與df等長的、只含有True與False的list,它只會把True的欄位show出來,以下詳細示範。
indexing_bool_list = np.random.randint(0,2,size=len(df)) == 1 #我們首先先創造出一個,隨機的、只有True跟False的、與df等長的list
print(indexing_bool_list[:30]) #看一下它前30個長什麼樣
df.loc[indexing_bool_list] #然後我們看看DataFrame會如何反應
接著我們可以看到,我們剛剛所設的條件,是不是與這個格式相符。這邊用了一個滿好用的計數器Counter,想要看一個list裡面甚麼樣的元素出現了幾次,便可以使用這個工具,其import方式為from collections import Counter,記得collections要加上s,Counter的C要記得大寫。
print(len(pd.isnull(df['Cabin'])), Counter(pd.isnull(df['Cabin'])))
print(len(df['Sex']=='male'), Counter(df['Sex']=='male'))
print(len(df['Age']> 70), Counter(df['Age']> 70))

其更新其實跟索引的使用方法沒差太遠,只是更新一個值或是更新多個值的方法有些不同而已。其實,也就是把值指派給所以出來的欄位而已。
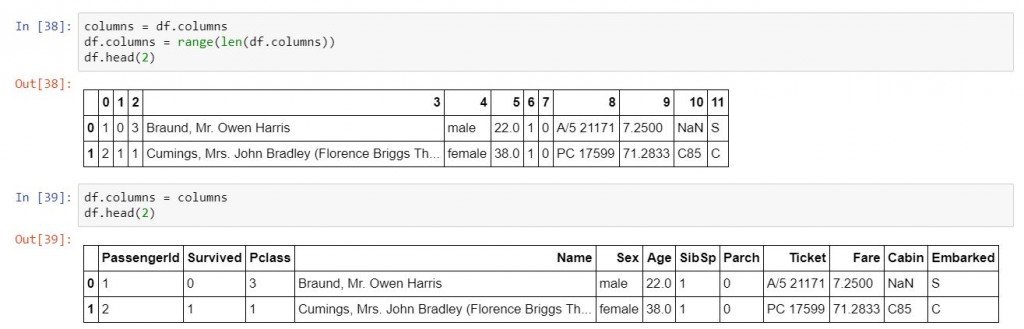
columns = df.columns # 把原本的column記錄下來
df.columns = range(len(df.columns)) #指派0到11的range做為新的columns,務必確保新的column的長度與原本的columns長度要等長
print(df.head(2))
df.columns = columns
print(df.head(2))
# 指派一個值會讓索引到的每一個值,都被指派為新值
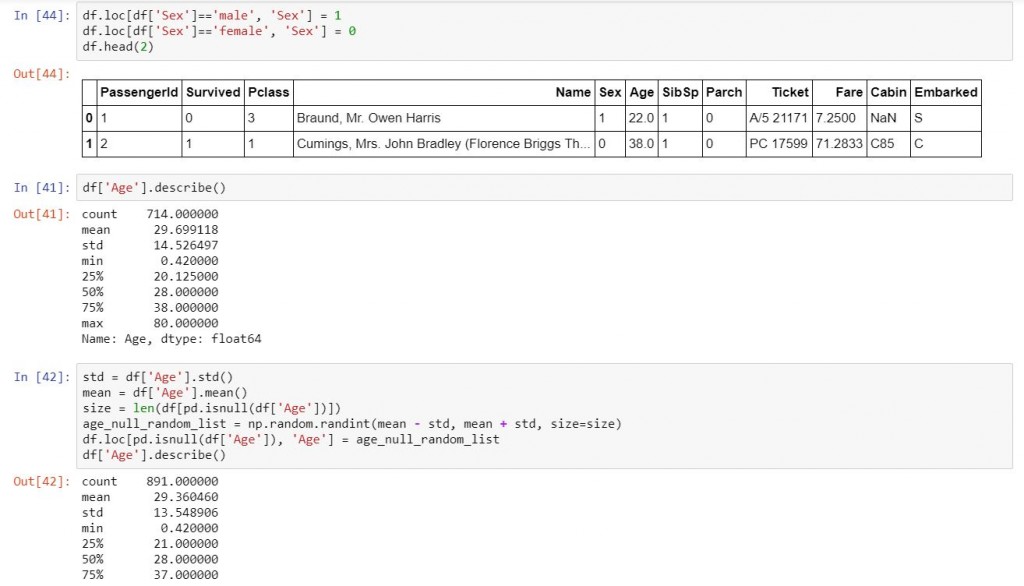
df.loc[df['Sex']=='male', 'Sex'] = 1
df.loc[df['Sex']=='female', 'Sex'] = 0
# 指派一個list
std = df['Age'].std() #算出標準差
mean = df['Age'].mean() #算出平均數
size = len(df[pd.isnull(df['Age'])]) #算出null值的長度
age_null_random_list = np.random.randint(mean - std, mean + std, size=size) #產生一個屆在一個標準差之內的隨機整數
df.loc[pd.isnull(df['Age']), 'Age'] = age_null_random_list # 將隨機整數指派給null值