在評價資訊檢索時,人們在意的指標有很多面相,在過去比較重要的像是搜尋的數量跟速度,但隨著科技的進步,現在更趨向於不同面相精準,這也是本章節的重點。不過值得一提的是使用者介面(UI)、使用者體驗(UX)也是在這個領域當中有人持續關注及研究的議題,例如google使用的top-10 result method一個頁面中只回傳前十筆相關資料,又或者是Searchme Visual Search提供一個創新的搜尋結果可預覽的呈現方式,然而這些資訊實在太難以被量化研究,因此,本章將主要聚焦在精準度的呈現。
我們要評價一個檢索系統的精準度,我們需要以下三項測驗資源:
其中前面兩者個蒐集都相對容易,不過第三者的蒐集則相當耗費人力,因為必須針對每個問題(以下稱Query)去標籤出那些文章(以下稱Document)是相關的,聽說當年微軟為了追上顧狗,即在印度聘了無數人每季要標籤出無數Queries中相關的無數Documents,然後拿去搜尋引擎做測試,另外,後來一些國家及大型組織也逐漸意識到這個query跟相關Document的測試集合的重要,因此著手蒐集測試資料集,詳細資料可以見Interdoction to Information Retrieval 第8.2節,裡面概述了各個資料集。但如何建立資料集並不是這一章的重點,因此以下假設我們已經得到含有上述三者資訊的資料集,並往下進行討論。
在此我們還有一個議題需要被討論,那就是使用者搜尋的Query以及使用者真實的資訊需求,舉例來說:
然而這樣的問題,掌握在使用者身上,很難用科學的方式去處理,當然現在可能漸漸有辦法透過數據解決,不過上述幾個比較有名的資料集中所提供的Query大都避開了這樣的問題,透過詳述問題的方式呈現Query,因此本章也暫時當作Query以及資訊需求是相等的。
以下介紹兩個這個領域當中最基礎的評價指標,分別為precision以及recall,需特別注意的是這兩個指標在應用時,要求的相關文章標記僅為二元的,也就是說,如果該文章相關rel=1,如果該文章不相關rel=0
1.Precision: 在所有檢索出的結果中有多少相關的文章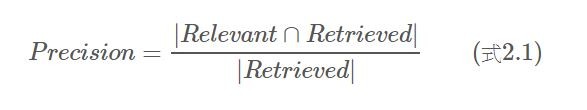
2.Recall: 在所有相關的文章中,有幾篇被檢索出來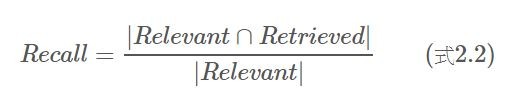
其中「Relevant」代表所有相關文章集合,「Retrieved」代表被系統檢索出來的文章的集合,而「倒U」則代表聯集,絕對值「||」在集合中則是取總數的意思,所以「|Relevant 聯集 Retrieved|」代表被系統檢索出來的文章中同時是跟Query相關的。
為了更清楚的理解,我們也可以用這種方式來看待Precision以及Recall。如果我們把所有的文章分成以下四類:True Positive(TP)、False Postive(FP)、True Negative(TN)、False Negative(FN),其中Positive以及Negative指得是系統的判斷,而True與False則是人為判斷是否相關,從下面這張表可以更清楚的理解其中意思。
| Retrieved | Non Retrieved | |
|---|---|---|
| Relevant | True Positive(TP) | False Negative(TN) |
| Irrelevant | False Postive(FP) | True Negative(TN) |
| ps.這邊大家常常容易搞混,如果真的弄不清楚,可以想想醫院最害怕遇到甚麼狀況,無非是機器判斷了沒有生病,可是其實是嚴重的隱性疾病,那末這種情況將被歸類在False Negative。 |
如果把這個邏輯套用到Precision以及Recall上,則兩個指標的計算公式則可以改寫如下:
那麼,你可能會問,為何我們不直接計算: 所有文章當中,準確被檢索以及準確被拒絕的文章(式2.5),如此一來將能夠用一個最直觀指標來衡量檢索系統。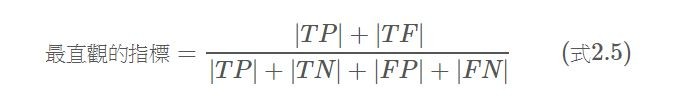
然而你也可以想像的到,在資訊檢索領域中,要從海量資料當中找出使用者需要的前十份,拒絕的文章數必定非常可觀,也就是說,|TN|(準確被拒絕者)將非常非常大,一但在分子與分母兩者都加上|TN|,這個指標將會非常接近1,也就難以衡量系統的優劣了。
因此,在資訊檢索領域中,並不會用這樣的方式來衡量檢索統的好壞。不過機器學習中的分類問題,如果資料沒有inbalance的問題,則很常用這樣的指標進行衡量。
首先釐清這兩個指標之間的互斥關係關係,一般來說,如果檢索系統做得有點基本的品質的話,前面幾篇檢索出來的文章,相關的機率通常都會比較高,也就是說Precision會隨著檢索出的文章越多而下降。
相反的,隨著檢索出的文章越多,相關的文章數也會越接近相關文章的總數(「|Relevant 聯集 Retrieved|」會越來越接近「|Relevant|」),如此一來,一旦某系統的設計將所有文章都檢索出,則必定可以打早一個Recall = 100%的檢索系統。
要更清楚的理解兩者之間的關係,我們必須透過下圖(取自Interdoction to Information Retrieval p158 Figre 8.2)來理解: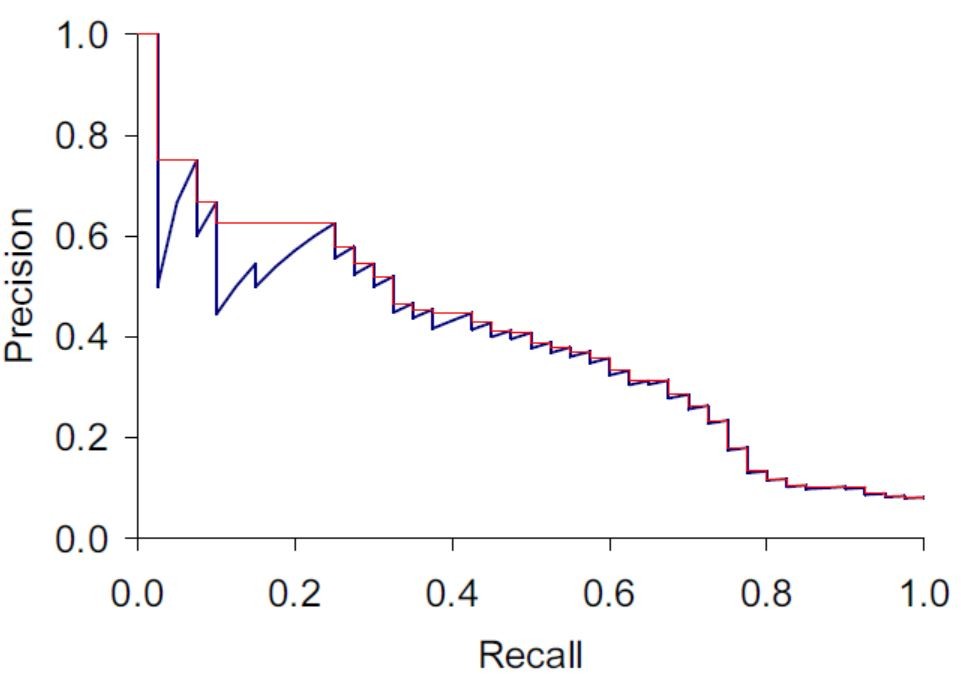
我們先忽略紅線,本文後段會再行解釋,此處先觀察其趨勢即可。由於Recall在所有文章檢索出時,必定等於100%,因此使用Recall的值從0到1作X軸,Y軸則放置Precision,如上所述,Precision會隨著檢索出文章變多而下降,在這張圖就可以看到明顯的體現。
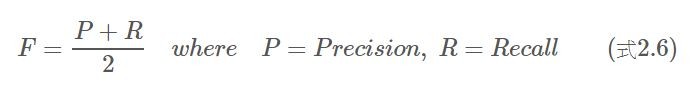
很明顯的,這個指標存在與上述一樣的問題。只要把Recall(全部檢索出)或Precision(檢索出極少)兩個指標其中之一做得很高,將保證50%的F。因此,這在資訊檢索領域中也不是一個好的指標。
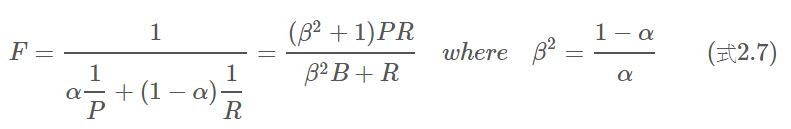
相對的幾何平拘束則可以改善上述問題。其中alpha是常數,介在0到1之間,代表著給予P與R的權重(alpha越高或是beta<1代表P越重要)。等號最右邊的式子,純粹方便計算,可以參考下式,並將alpha帶入原式。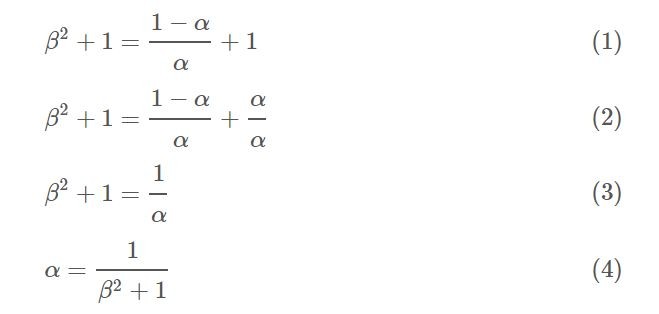
而在此F的計算之中,把P與R的相加關係,改成相乘關係,因此,一旦有其中之一非常低,將會受到非常嚴格的懲罰,F值就會趨近於零,因此可以改善前述問題。
不果如果各位想要更了結Recall及Precision代表的實際意涵,可以思考一下,面對道甚麼類型的使用者,應改給予Recall比較高的權重,而又在甚麼樣的情況底下,應該比較在意Precision。
F-beta表示幾何平均數F的一個特殊狀況,也就是我當我們給予P以及R相同的權重的時候(alpha=0.5, beta^2=1):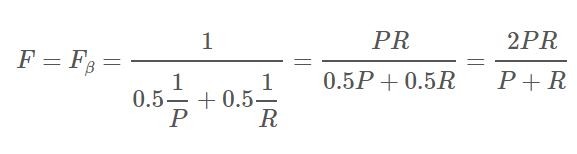
在理解MAP之前,我們先從Average Precision的觀念下手,比較容易理解。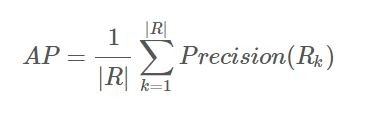
其中|R|代表相關的文章總數。在一個Query中,系統將從第一份資料開始抽取,假設系統設定會持續抽到最後一份,而隨著抽取的量越大,則會逐步檢索出每一份相關的文章$R_k$,而每當檢索出一份相關文章時,Recall也會跟著改變,此時我們重新計算Recall及其對應的Precision。因此,我們大約可以描繪出下圖藍線的部分(與前面是同一張圖):
但還有一個棘手的問題要解決,就是藍線的雜訊非常多,因此作者這邊用內插法的方式找出每一個Recall下的Precision(interpolated Precision),以去除雜訊。而所謂內插法即是將內原本每個Recall下的Precision,取成每一個Recall下未來最大的Precision(圖中紅線部分),以下用一個例子說明:
假設有一個檢索系統,總共抽了10篇文章,且總共有4篇相關的文章,節果如下:
| 編號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 相關 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 累積 | 1 | 1 | 1 | 2 | 3 | 3 | 3 | 4 | 4 | 4 |
| R | 0.25 | 0.25 | 0.25 | 0.50 | 0.75 | 0.75 | 0.75 | 1.00 | 1.00 | 1.00 |
| P | 1.00 | 0.50 | 0.33 | 0.50 | 0.60 | 0.50 | 0.43 | 0.50 | 0.44 | 0.40 |
| 其中我們把有抽到文章的四個點萃取出來,獨立成一張表: |
| R | 0.25 | 0.5 | 0.75 | 1 |
|---|---|---|---|---|
| P | 1 | 0.5 | 0.6 | 0.5 |
| intropolated P | 1 | 0.6 | 0.6 | 0.5 |
我們便可以計算出AP = (1 + 0.6 + 0.6 + 0.5) / 4 = 0.675,這個數字大家也可以將其想像為,上面圖中紅線下的面積。
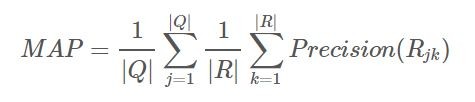
如果上面的AP可以理解,在理解這個式子的時候就非常簡單了,差別只是在,AP只有一個Query的Recall及Precision,但是MAP計算多個Query。其中MAP多了一個Mean的意思,就是平均計算了每一個Query項下的Recall及Precision。從圖形上來理解,假設有50個Query,可以想像成堆疊上面那張圖(不同Query畫出的)五十次,並將所有圖中的藍線下面積相加除以五十。
而比起F measure,MAP是比較常被拿來使用的評價方式之一,因為這個指標考量的不是單一個Recall下的Precision,而是通盤考量每一個狀況下所作出的指標。
如果上面觀念都理解了,Precision at k也就非常容易理解了,其中k指的是檢索出的文章總數,其餘的也就是字面上的意思,需特別說明以下二點。
第一、之所以特別使用一個點的指標其實其來有自,指標最終是要直接反映使用者的感受,而各位在透過顧狗去檢索資訊時,可能往往翻不到兩頁,發現找不到資訊就會直接換另一個Query作檢索,因此,針對特定的前幾筆文章,用Precision at k去衡量是最符合使用者直觀感受的。
第二、然而這個指標也存在一個非常大的問題,由於大部分使用這個指標的作評價的系統,k都不會設太大,大多為10、20或是30,因此一旦相關的文章總數非常高的話,Precision也會非常高。
R-Precision是Precision at k的延伸應用,只是R-Precision把k設為相關文章的總數(「|Relevant|」)。如此一來,你會發現一件有趣的事,Precision等於Recall了: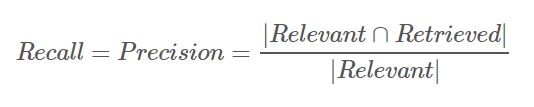
書上把Precision及Recall相等的點稱作_break-even point_,在理論上來說,幾乎沒辦法解釋我們為什麼要對_break-even point_產生興趣。但在實務上來說,儘管$R-Precision$指衡量某一Recall上的Precision,但她卻與MAP高度相關。
再進入最後一個評價方法之前,必須提醒大家的是,到目前為止,我們對於文章相關或不相關的計量,都還停留在Binary(1或0)。接下來要介紹的最後一個評價方法NDCG,則是採納了給予不同相關程度的資料不同的層級的計量的方法。
NDCG其實是按照
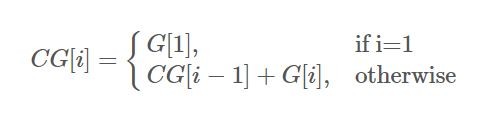
Discounted Cumulative Gain(DCG)在每個Gain上除以一個log項(隨著減縮出的文章數而增加),以使得越後面抽出來的文章,得到的Gain會得到適當的懲罰: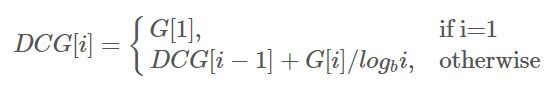
其中log的底數b可以自己設定,設定越高則懲罰越輕(課本上的例子設定為2,供大家參考)。最後Normalized Discounted Cumulative Gain(NDCG)則是指先假設一個最理想的檢索順序,也就是把「相關分數」最高的幾篇文章排在最前面,然後「相關分數」比較低的依次遞減往後排,然後算出其DCG,稱為Idealized DCG(IDCG)。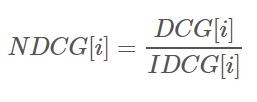
大家可以透過如下例子理解NDCG。
實際檢索狀況:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| G[i] | 2 | 0 | 0 | 3 | 5 | 0 | 0 | 4 | 0 | 0 |
| CG[i] | 2 | 2 | 2 | 5 | 10 | 10 | 10 | 14 | 14 | 14 |
| Log2i | 0.00 | 1.00 | 1.58 | 2.00 | 2.32 | 2.58 | 2.81 | 3.00 | 3.17 | 3.32 |
| DCG[i] | 2.00 | 2.00 | 2.00 | 3.50 | 5.65 | 5.65 | 5.65 | 6.99 | 6.99 | 6.99 |
理想檢索狀況:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| G[i] | 5 | 4 | 3 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| CG[i] | 5 | 9 | 12 | 14 | 14 | 14 | 14 | 14 | 14 | 14 |
| Log2i | 0.00 | 1.00 | 1.58 | 2.00 | 2.32 | 2.58 | 2.81 | 3.00 | 3.17 | 3.32 |
| IDCG[i] | 5.00 | 9.00 | 10.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 |
NDCG:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| DCG[i] | 2.00 | 2.00 | 2.00 | 3.50 | 5.65 | 5.65 | 5.65 | 6.99 | 6.99 | 6.99 |
| IDCG[i] | 5.00 | 9.00 | 10.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 | 11.89 |
| NDCG[i] | 0.40 | 0.22 | 0.18 | 0.29 | 0.48 | 0.48 | 0.48 | 0.59 | 0.59 | 0.59 |
本章主要討論論不同的評價方式,並逐步推論各種評價方式,從最基本的Precision以及Recall計算出的F measure(F-beta),到Mean Average Precision(MAP),再到Precision at k及R-Precision,最後談到可以給予不同相關程度的文章不同分數的NDCG。總體而言可以這樣分類:



{kind=link}