具備怎樣特質的計程車司機是最賺錢的呢?根據政府提供的計程車營運狀況調查,觀察變數,我試著找到對於收入最有利的變數,變數欄位相當廣,從計費方式、有無加入車隊、平常出沒的時間、地點,甚至到平常聽的電台,不過資料算是相當凌亂的(可以說是髒資料吧!)
要討論這些的大前提,必須把資料好好整理。而資料欄位當中的"C9.一天營業總收入",便是我的目標變數(y),順帶一提,6665位計程車司機平均"一天營業總收入"約為1535元,
資料大概長這樣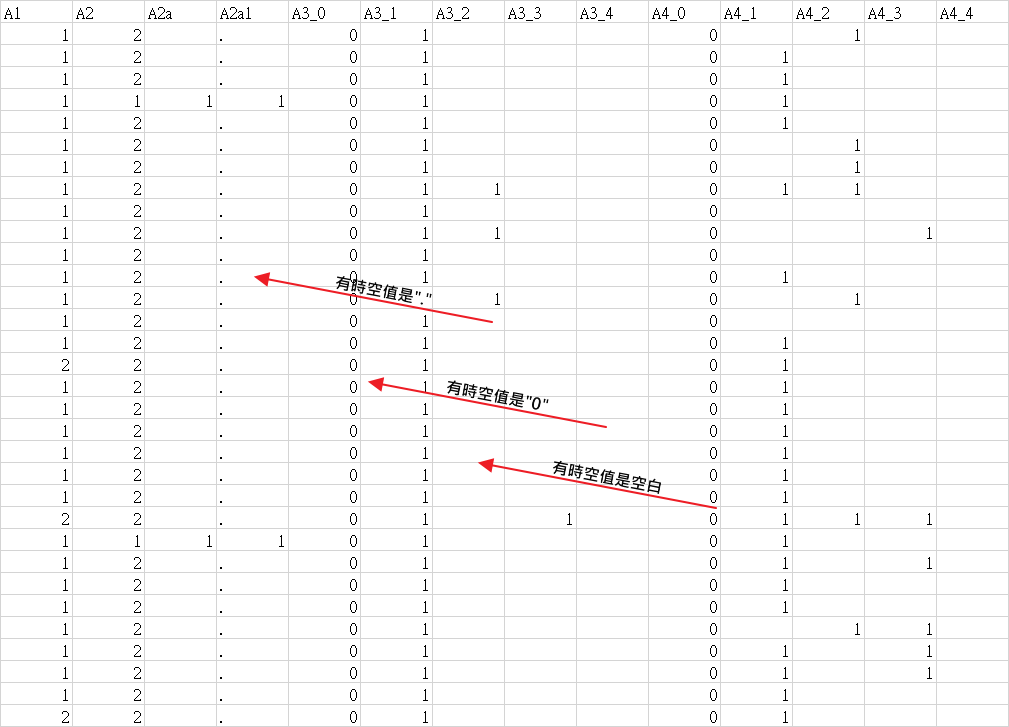
變數名稱長這樣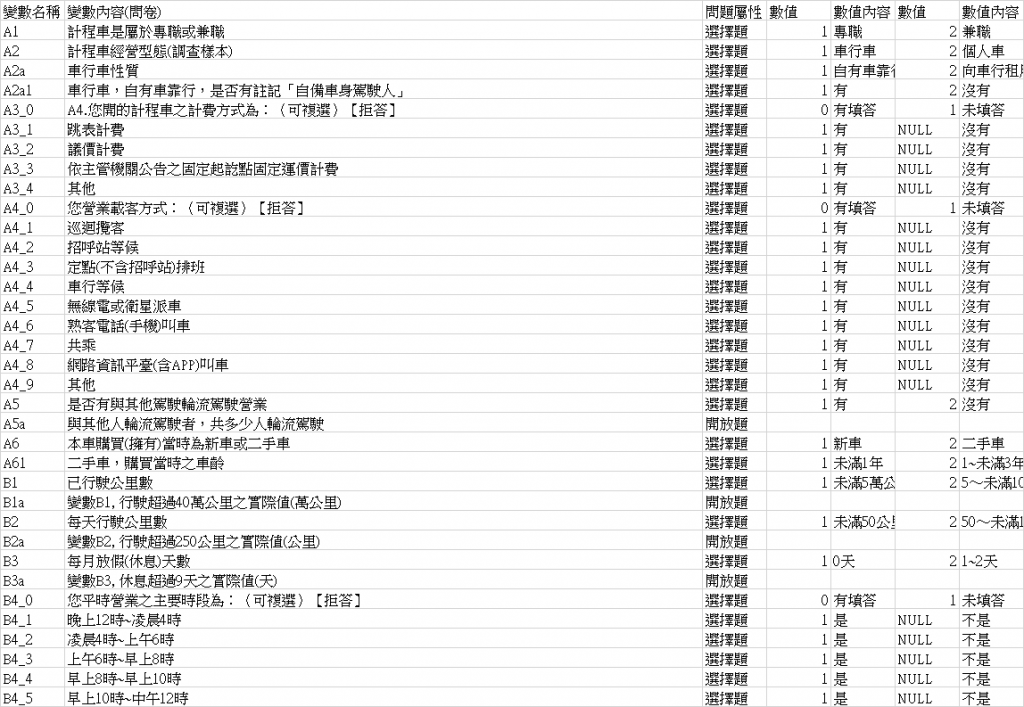
要想辦法把它變成可以閱讀的資料
這資料
#IF沒有請先安裝
library(tidyverse)
library(magrittr)
#x是資料本身
#y是變數名稱
#這一行在做快速分析的時候很好用,複製你要的資料然後跑這行資料就會讀進R_code,然後我對資料集x(資料本身)事先轉置了
x = read.table("clipboard",header = T , sep = '\t')
y = read.table("clipboard",header = T , sep = '\t')
#把NA值先全部改成-1
x[is.na(x)] = -1 #改成0的話會跟其他的搞混
for (i in 1:149){ #共149個變數
#要把資料本身NA,0,1,2改成變數名稱,方便閱讀,用excel_vlookup的方式
for_vlookup = y[-(1:2),(i+1)]
for_vlookup = for_vlookup[-which(for_vlookup == "" )] %>% as.character()#擷取一整行然後扣掉空值
a = 1:length(for_vlookup) #告訴我總共有多少變數
#把每一行都轉換成一個VLOOKUP用的表格
df1 = data.frame(
x1 = c(as.numeric(as.character(for_vlookup[a[a%%2==1]])),-1),
x2 = c(as.character(for_vlookup[a[a%%2==0]]),"miss值")
)
#每一行的資料
df2 = data.frame(
x1 =as.numeric(as.character(x[,i]))
)
#VLOOKUP
w = df2 %>% inner_join(df1 , by = "x1")
#取代掉原本的數字,變成方便閱讀的中文
x[,i] = w[,2]
}
df1是把資料從excel一行轉換成一個表格
待續吧...我跑出來大概長這樣...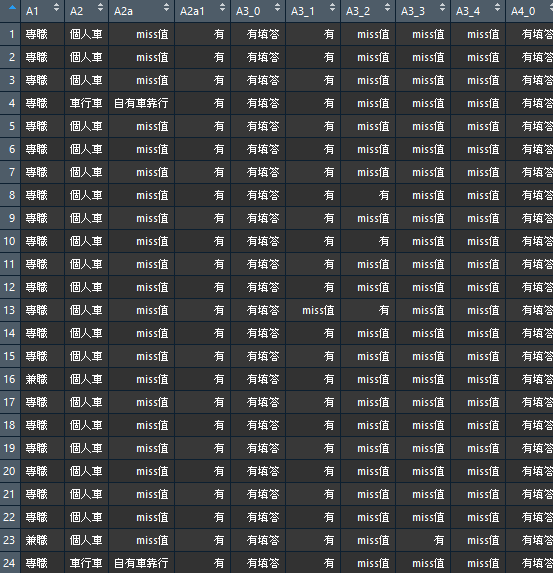
看的出來有許多數值看起來明顯是空值,我卻判斷為遺失值了,要想一下怎樣去判斷這資料集的空格誰是空值誰是遺失值...
拍謝資處可能比較無聊,我也是這樣覺得,但是卻很花時間,這篇比較有意思的地方:
x = read.table("clipboard",header = T , sep = '\t')
只要複製Excel資料跑這行就可以讀入資料很方便!!
然後把資料處理成可以vlookup,然後用R跑vlookup的用法,明天見!!
code解釋的好清楚喔XDD
平常有養成瘋狂寫註解的習慣,我記得我那年考高考資料處理有一題問說,程式碼最重要的是什麼(簡答題),我答案寫"程式碼最重要的是多寫註解",我是不知道正確答案啦...但...額...怪不得我沒考上哈哈哈哈
哈哈我也覺得寫註解超棒的
但有時候以為自己會記得忘記寫
結果三個月再去看根本不知道自己在幹嘛 XDD
還要上網查一下函式然後佩服一下三個月前的自己這樣 

