決策樹的概念,我想版上很多文章都寫的都比我還清楚,我做的事情就是拿一筆我也不知道會發生什麼事的資料,丟進去,不多說先上第一次結果的結果。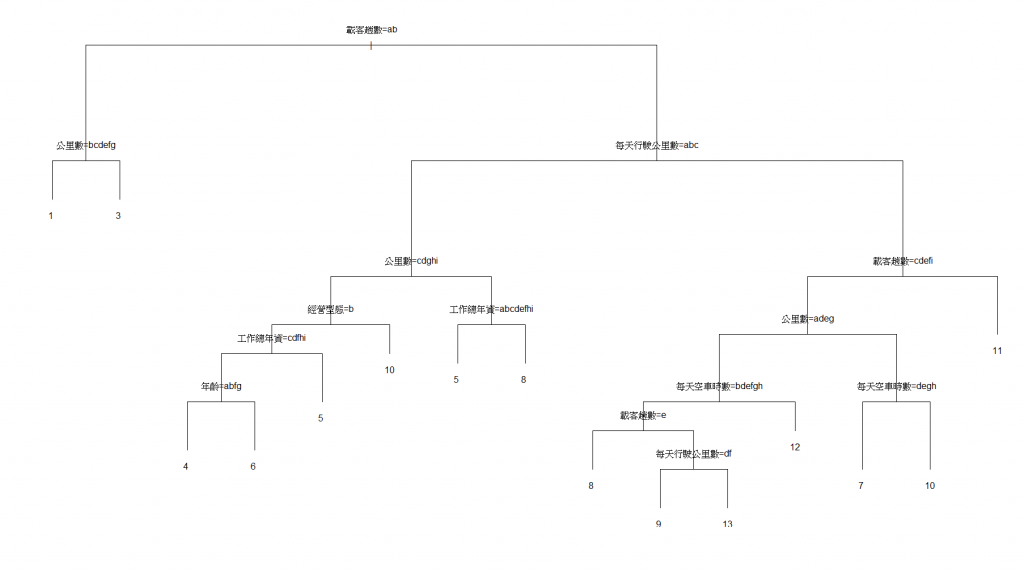
library(rpart)
np = ceiling(0.1 * nrow(taxi)) #資料筆數
test.index = sample(1:nrow(taxi),np)
taxi.testdata = taxi[test.index,]
taxi.traindata = taxi[test.index,]
taxi.tree = rpart(一天營業總收入~.,data = taxi)
plot(taxi.tree);text(taxi.tree)
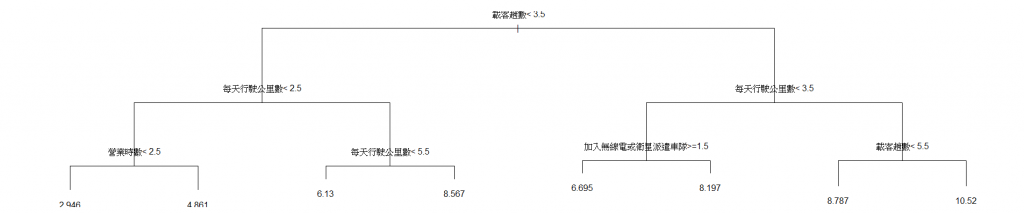
然後觀察這張圖(我變數的部分也還沒處理好,你們理解成abc這種的數字都比較小就對了字母越大數字也就遞增),"一天營業總收入"數字越高就代表賺的越多,我發現我的變數選擇上有一些基本共變異問題,**第一層分類,載客趟數越少(只有ab的話),則賺的越少,**雖然看起來是廢話,不過也幫助了我在閱讀決策樹上一些幫忙,也就是說決策樹的 = 是寫在左邊,!=是寫在右邊,第一層分類告訴我,行駛公里數越多錢賺的越多,OK,基本上可以確定,這種變數等下都可以丟掉了,廢話中的廢話。
在來說說我覺得有意思的變數,年資、年紀、車行的車/個人的車、空車時數這些是真的會影響收入,這算是一個發現吧!
我一開始是不太相信年資跟年紀的!因為在我印象中,我想坐計程車,就是直接從路上叫一台,或是打55688,理論上年資可能有影響但也就是猜想而已,但這顆決策樹告訴了我,對,沒錯,年資是會影響的。我明天還會在試著畫一棵更加合理,可能附有更多資訊的決策樹。
天啊....我才發現...上班又要每日一PO真的很累...,每天一點學習吧!會努力堅持下去的!
證明正確率的部分...我也會補上的,然後"補遺失值"部分,我也希望能在鐵人賽中與各位交流。