昨天說明以 TD learning 的方式評估狀態價值,現在我們有狀態函數後,下一步就是考慮怎麼獲得動作價值,並加以實現控制。
如同 Day21 中推論狀態價值的思路,我們可以推論出動作價值,這邊直接提供推論的結果: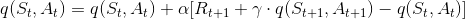
好的,現在我們有動作價值,接著透過 - greedy 挑選動作,就可以確定在什麼狀態下,應該採取什麼動作。
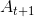 應該代入什麼?
應該代入什麼?在繼續往下說明演算法之前,先說明一個在模擬過程中遇到的問題 ─ 「On-Policy 與 Off-Policy」。這個問題會延伸出兩個不同的強化學習方法 ─ 「SARSA 與 Q-Learning」。
在使用 - greedy 的情況下,如果剛好遇到探索的情況,在
應該代入探索的動作?還是 greedy 選擇的動作?
On-Policy
按照我們過去在蒙地卡羅控制的思路,「探索」是為了讓我們有更多機會估計其他動作價值,增加我們找到更好的動作的機會。在這個思路下, 應該代入探索的動作,使得我們可以估計其他動作價值。這個思路下,我們遵守 - greedy 這個策略,因此屬於 on-policy,流程如下:

Off-Policy
相反的,如果我們在遇到探索時,仍然使用 greedy 的結果更新動作價值,那麼就沒有遵守 - greedy 這個策略,所以屬於 off-policy,流程如下:

[補充說明]
- 上述提到的 On-Policy 方法,即是 SARSA;而上述提到的 Off-Policy 方法,即是 Q-Learning。判斷演算法是 On-Policy 還是 Off-Policy ,由「演算法是否完全按照 policy 更新動作價值」判斷。
- 在歷史上,Watkins 先在 1989 年提出 Q-learning 及
- greedy,Rummery 與 Niranjan 後於 1994 年提出 modified Q-Learning, Sutton 於 1996 年將 modified 更名為 SARSA。我不清楚 Sutton 書上先介紹 SARSA 後介紹 Q-Learning 的原因。
3. 1994 年所提出的 SARSA 是以 episode 為單位更新動作價值,同年 Wilson 提出以 step 為單位更新動作價值的 SARSA。原本是在 Sutton 的書上看到,但後來去看 1994 年 Rummery 與 Niranjan 的原文,找不到支持這點的論述,故先刪除。
那麼,這兩個演算法會有什麼差異呢?明後天我們分別實作這兩個演算法,來比較這兩個算法的差異。

