
今天繼續完成 How Google does Machine Learning 的第二章節最後一部分~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第二章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
A data strategy
Training and serving skew
An ML strategy
Transform your business
Transform your business
Lab Intro - ML use case
Non-traditional ML use case
課程地圖
這邊講到google map的一些應用
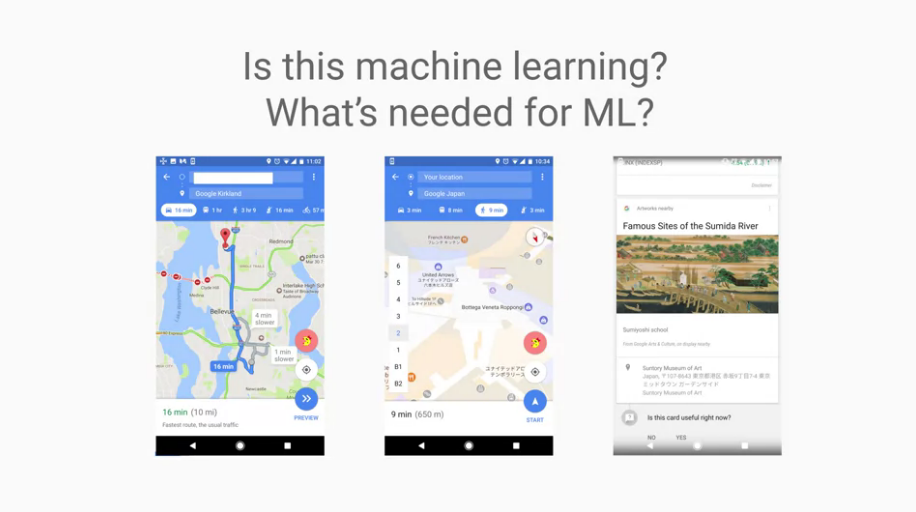
左圖:依照rule"搜尋最快路徑"
需要參考的東西:交通堵塞? 橋未開放?
怎麼蒐集上述的資料?
最後使用 A* algorithm 解決問題 (最短路徑演算法)
以結果來說,終究只是在設定rule
中間:另外一個例子,如何知道使用者在二樓?
wi-fi points, barometric pressure, typical walking speed 之類的資料
你有了這些數據,嘗試使用ML來避免寫rule
右邊:google地圖還能夠推薦使用者?
連接使用者過去的歷史,清楚使用者偏好,並進行推薦
我們希望google map能成為使用者的虛擬助手,
這問題只有ML能夠實現地圖服務的"個人化"
因此,ML就是能超越手寫規則的方法,
手寫規則有太多有可能無法實現的事情了。
從上例中左圖(通用)到右圖(個人化),
越個人化的事情越只能靠ML來實現,
(前面章節也有提到,這就是local data的問題)
但不管需不需要ML,要完成這些事情我們都需要大量大量的data,
對我們而言,寫rules或models相對來說只是小case。
比喻:ML是火箭引擎,data就是燃料
If machine learning is a rocket engine, data is the fuel.

不論任何的階段,Data永遠是勝利的關鍵,
收集data除了要求量之外,也需要多樣化,
以認識下圖為例子,如果資料太少,你可能用再複雜的規則也不知其形,
隨著資料夠多,整理的樣子就會更加得清楚。

因此,ML最重要最首先的事情,就是收集數據的策略。
ML strategy is first and foremost a data strategy.
課程地圖
在ML之前,我們還是必須要先分析一下數據
換句話說,如果不會數據分析,也不能做ML。
有一個常見ML產品的fail原因: training-serving skew
簡單說是兩個單位收集資料的方式不同,造成資料訓練與服務時沒有對應
The problem is that the result of stream processing and the result of batch processing have to be the same.
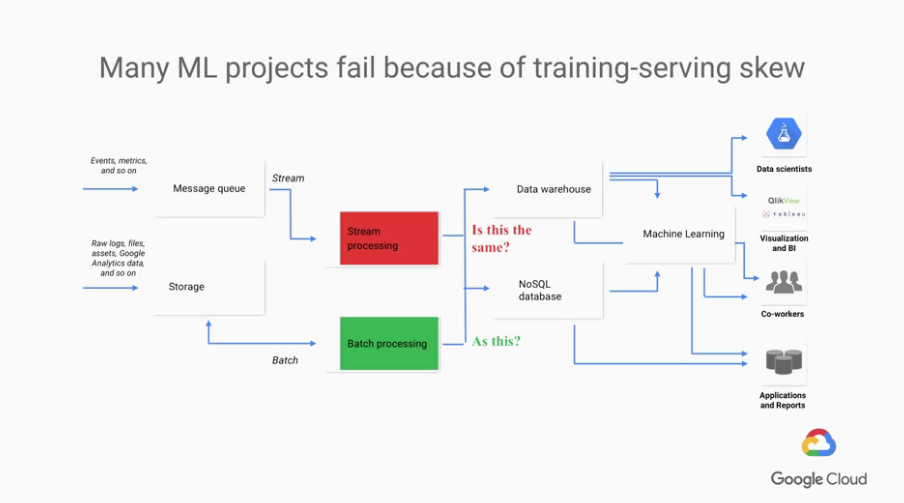
解決(減少問題發生的機會)方法:
用一樣的方法蒐集資料,一個同時處理batch與stream的階段
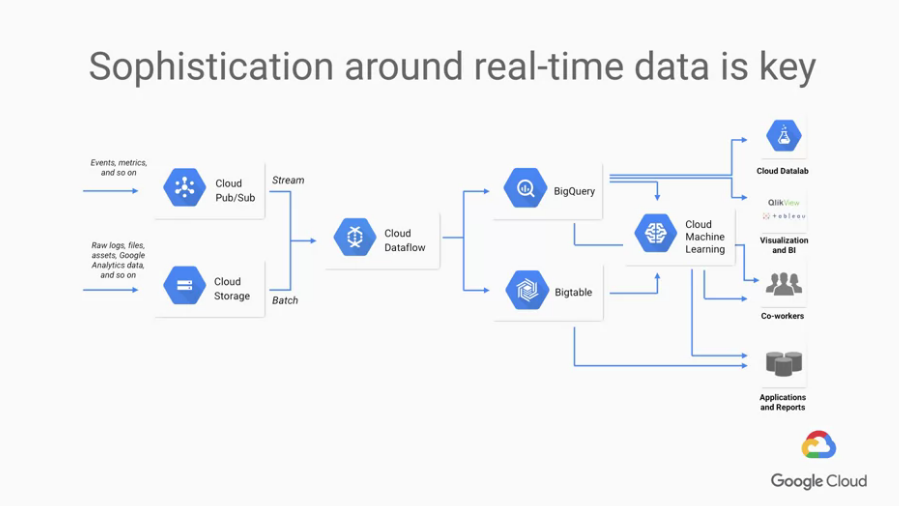
所以較好的架構應該如下圖:
課程地圖
ML要注意的事情:"ML的重點在量而不是在複雜度"
即使是小的ML model有有它的價值。
另外一個心態是,多盡快失敗並反覆重試
The idea is that if you're failing fast, you get the ability to iterate. This ability to experiment is critical in the realm of machine learning.
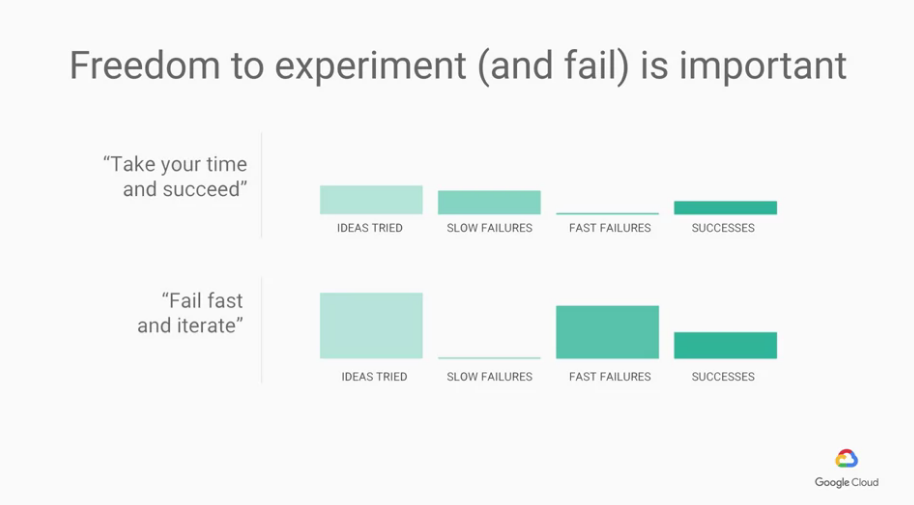
從上圖我們可以看到,多嘗試,多快速的失敗,更能夠達到成功。
(慢慢嘗試後得到的慢速失敗(採取比較穩紮穩打的作法),反而成功的機會會小一些。)
另外提到資料,90%的企業資料皆是沒有被結構化的
試想 emails, video footage, texts, reports, catalogs, fashion shoots, events, news, you name it. All unstructured data.>
不過幸運的是,我們現在處理這些未結構化的資料,
因為有了google的各種pre-trained model已經變很簡單了,
我們就把這些unstructured data丟進這些ML APIs,
我們就能得到一些像entities, places, labels, people... 之類的資料,
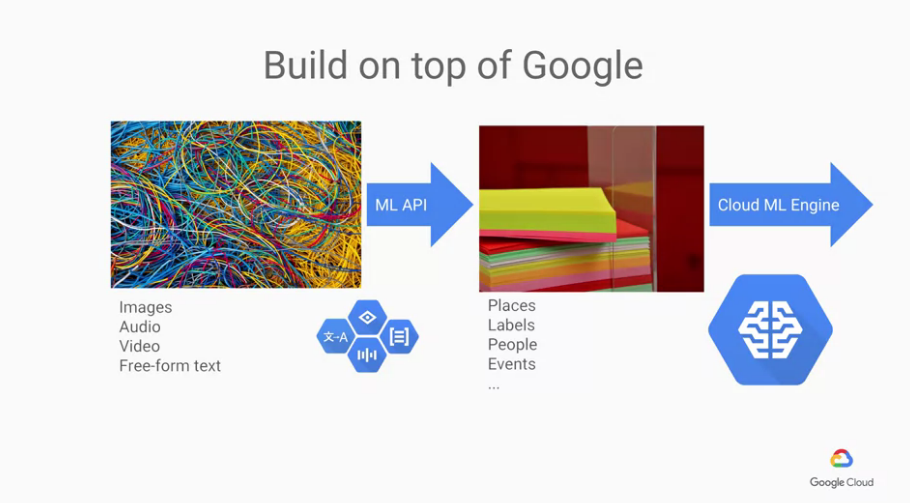
因此我們不必在花時間去處理unstructured data,
丟進這些ML APIs,拿結果再丟進我們的 custom ML model 訓練即可。
課程地圖
這章節在講ML在商業上怎麼應用
使用ML訓練的方向是什麼? 記住一個字:"delight"
如何使你的使用者開心就是訓練的目標。
影片中的舉例:
只要是需要想辦法讓使用者開心的問題,都可以是我們訓練的目標。
另一個例子:既然你喜歡的音樂可能有版權問題,
何不自己用ML生一個音樂? 一定會是你最喜歡的。
商業上能受惠於ML的三種方式:
簡化使用者輸入、更適應用戶
簡化業務的流程、創造新的商業機會
用ML讓你的使用者開心。預測需求,並為他們量身打造
而這裡又有份學習單:
試著去思考公司內一個已經存在的應用,去想哪個部分能夠用ML取代呢?
這樣做的優點是什麼?
你想要這樣做需要收集什麼資料?
你現在能取得這樣的資料嗎?
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
