
今天來閱讀 How Google does Machine Learning 的第三章節~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第三章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
Introduction
ML Surprise
The secret sauce
課程地圖

ML是什麼?
ML是一種透過讓電腦寫程式去完成一項任務。
而這個電腦只需要看一大堆"例子",就可以自動想到最好的"程式"。
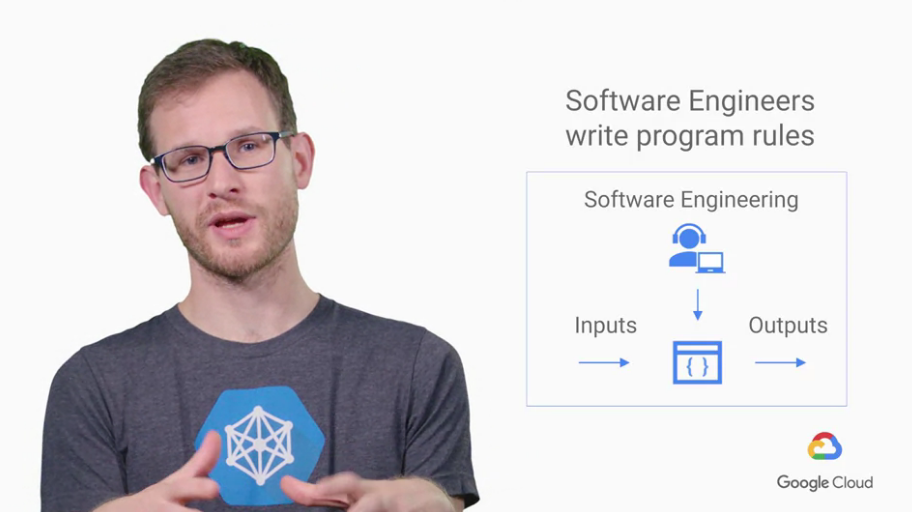
傳統的軟體工程
軟體工程師寫一大堆code(描述rules),
使我們能達成目標(inputs能產生對應Outputs)
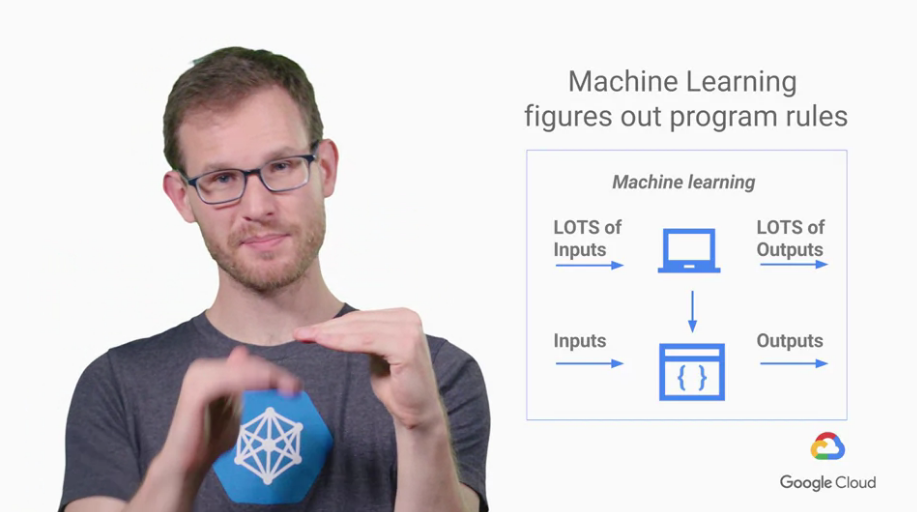
ML會自己想出這些rules該怎麼完成
一樣能使我們能達成目標(inputs能產生對應Outputs)

ML Surprise
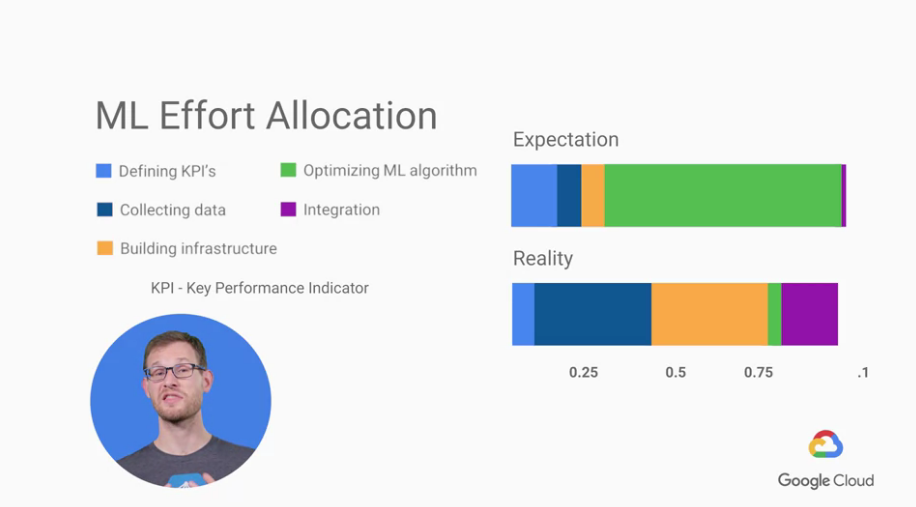
上圖我們會發現一件事情是,很多公司會期待如上方的時間分布,
但我們真實的時間分布應該如下圖,
有許多公司花太多時間在優化演算法上,
甚至會想要不斷的使用最新最強的演算法,
但就結果而言這樣並不會比較好,我們甚至更應該花時間在找資料上。
另外還有一點是,我們也應該花少一點時間去訂KPIs,
ML的影響力有可能短期對於KPI並不會有很大的影響,
但就長期來看,ML的預測準確性會不斷提升,影響力是非常長遠的。
課程地圖
這個章節講到ML失敗的最常見10大陷阱,也算是google自己對客戶的經驗談,
(配合前一章節提到的五個階段)

只依靠演算法建ML系統,實現演算法的過程仍需要一堆透過軟體才能實現的事,
而這件事情往往只會使整個過程更加複雜。
所以我們更推薦先從簡單的軟體開始先寫。
就請先停止別做ML,去蒐集資料吧,沒有資料你是做不了ML的。
這裡還有一種的經驗是,很多企業說自己擁有資料,
但那些資料是已過時,甚至沒有人整理過的,
沒有整理過的資料,甚至都不清楚資料裡面有什麼,
公司內也沒有人最近有去查看這些資料並提出新的想法,
這些都算是"沒準備好data"(還沒有"價值"的data)。相信我,等到要開始訓練ML時,你會花更多的心力在處理資料上,
甚至是為了乾淨的資料還要重新收集,這才會是更大的挫折。
當有人開始在系統中訓練ML的系統時,那些人會變得相當重要。
這段個人的理解是,以google來說,
使用者通常能夠提供ML的結果反饋,
我們需要想辦法讓人能持續地給系統的反饋,
(因為沒有這些人,我們就沒有資料,他們非常的重要)
以使用者的角度來說,不論他們得到的是不是ML的結果,
他們會更在乎的是有沒有得到好的建議或很酷的觀點。
一開始,從我們ML系統得到的結果也許不是最好的,
但我們要使使用者能喜歡我們的產品,使他們不斷持續地投入。
這樣我們的結果就能不斷的更加優化。
提到這裡也還有另外一個可能的問題,
我們也要避免不正當的得到回饋,
例如像是讓使用者一定要定期回饋使用心得,
或者我們採取了不好的方式取得資料,像是一定要點擊某個結果,
這部分是需要思考的,因為這有可能使我們的ML學習到不良的內容。
要記得去思考你的ML結果對世界有沒有幫助,
你訓練了他,把他放在那裡為用戶服務,
但無法說他有多好,或沒辦法分辨他有辦法讓客戶能終身參與,
或是使他具有終身價值,這樣沒辦法向人說明這個ML是有用的。
使用pre-train model在初期能夠省下不少時間,
初期使用也能幫助功能快速完成,而且也較容易使用。
事實證明,一個好的ML演算法需要訓練非常非常多次,
很多人會只訓練一次,並拿結果來說很好,
但事實上可能只完成了10%左右,
一個好的ML演算法,他需要被訓練很多很多次。
這是一種特殊的陷阱,事實上以NLP來舉例,
google解決這些問題都是經過數十年的研究而得到很好的調整,
而以商用來說,你幾乎只需要一個現成的、已經製作好的或已經定義好的,
先不要嘗試在這部分試圖做自己的研究,這會非常的貴。
聽到這你可能會覺得,天啊,ML怎麼會有這麼多的陷阱,
但好消息是,ML的價值是長遠的,
而且ML能達成幾乎比任何已經有的產品還要更好的結果。
同時,當你覺得ML難時,你的競爭者也會覺得ML很難。
但當你有ML產品釋出時,你能給顧客帶來更好的使用者體驗,
而且不斷的使用者回饋能使你的ML開始一直一直不斷的精進。

coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
