
資料角力(有時也稱為資料改寫),簡單來說是將資料整理成合乎需求的格式,以利後續視覺化或者套用機器學習模型。今天要來介紹一些運用Pandas操作進行資料角力的方式。
Data wrangling (sometimes referred to as data munging) is the process of transforming and mapping data from a raw data form into another format which is more appropriate for analytics or other purposes like visualization or to fit machine learning models. Today, we are going to talk about some functions in Pandas which are pretty essential for data wrangling.
import pandas as pd
用於通過一個或多個鍵將兩個資料集的行連接起來。
Merge two DataFrame through one or more keys.
DataFrame.merge(self, right, how='inner',
on=None, left_on=None, right_on=None, left_index=False, right_index=False,
sort=False,
suffixes=('_x', '_y'),
copy=True, indicator=False, validate=None)
連接的方式,方式有'inner'(內連線,交集),'left'(左外連線,並集),'right'(右外連線),'outer'(全外連線)。
Type of merge to be performed.
'left'/'right': use only keys from left/right frame(SQL left outer join).
'outer': use union of keys from both frames(SQL full outer join).
'inner': use intersection of keys from both frames(SQL inner join).
on 用來連接的列索引名稱,在兩個要連接DataFrame物件中都要存在。
left_on, right_on 用左或右側DataFrame連接鍵的列名。
left_index, right_index 用左或右側DataFrame的行索引做為連接鍵。
on:Column or index level names to join on. These must be found in both DataFrames.
left_on, right_on:Column or index level names to join on in the left/right DataFrame.
left_index, right_index:Use the index from the left/right DataFrame as the join key(s). If it is a MultiIndex, the number of keys in the other DataFrame (either the index or a number of columns) must match the number of levels.
如果上述所有連接參數都沒有指定,預設會以兩個DataFrame的列名交集做為連接鍵。
If on is None and not merging on indexes then this defaults to the intersection of the columns in both DataFrames.
將合併的資料進行排序。
Sort the joined DataFrame.
要合併的兩個DataFrame如果存在相同列名時,會在列名加上字尾。
Suffix to apply to overlapping column names.
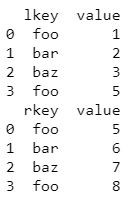
# 創作兩個不同的DataFrame:df1與df2 create two DataFrame df1 and df2
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
print(df1)
print(df2)
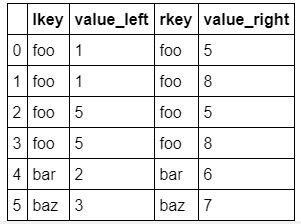
df1.merge(df2, left_on='lkey', right_on='rkey',
suffixes=('_left', '_right'))
沿著指定軸或連接方式將兩個資料框架堆疊(連線、繫結)到一起,相當於資料庫中的全連線。
Concat two DataFrame along axis by stacking(concatenation, binding) them together(SQL union all).
pd.concat(objs, axis=0,
join='outer', ignore_index=False,
keys=None, levels=None, names=None,
verify_integrity=False, sort=None, copy=True)
要結合的物件,一般而言是列表或字典。
The objects we want to concat, normally list or dictionary.
指定連線軸向,0為沿索引,1為沿欄位名。
pd.concat([obj1, obj2], axis=0)效果與obj1.append(obj2)相同;
pd.concat([df1, df2], axis=1)效果與df1.merge(df2, left_index=True, right_index=True, how='outer')相同。
The axis to concatenate along.
pd.concat([obj1, obj2], axis=0) is similar to obj1.append(obj2).
pd.concat([df1, df2], axis=1) is similar to df1.merge(df2, left_index=True, right_index=True, how='outer').
改成True重建索引為0, 1,...,n - 1。
If True, use 0, 1,...,n - 1 instead of the original index values along the concatenation axis.
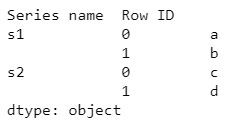
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
print(s1)
print(s2)

pd.concat([s1, s2], ignore_index=True)

pd.concat([s1, s2], keys=['s1', 's2'])

pd.concat([s1, s2], keys=['s1', 's2'],
names=['Series name', 'Row ID'])
將資料依照需要的欄位名分組。
Group the data by specified column name.
DataFrame.groupby(self, by=None, axis=0, level=None,
as_index=True, sort=True, group_keys=True,
squeeze=False, observed=False, **kwargs)
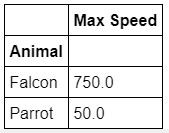
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'],
'Max Speed': [380., 370., 24., 26.]})
print(df)
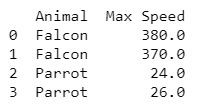
df1 = df.groupby('Animal')
print(df)
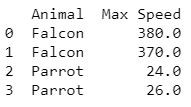
df1.groups
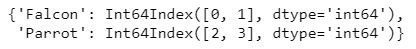
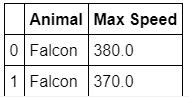
df1.get_group('Falcon')
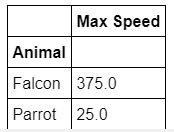
df.groupby(['Animal']).mean() # 也可以計算平均 get mean
df.groupby(['Animal']).sum() # 計算總和 get sum
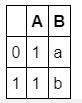
去除特定重複行。
Return DataFrame with duplicate rows removed, optionally only considering certain columns.
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
用以指定僅考慮特定列有無重複,預設為考慮所有列。
Only consider certain columns for identifying duplicates, by default use all of the columns.
'first', 'last' 僅保留首/末次出現的項。
False 刪去所有重複。
'first', 'last':Drop duplicates except for the first/last occurrence.
False:Drop all duplicates.
刪除重複後要取代原始資料框架或新增一個副本。
Whether to drop duplicates in place or to return a copy.
df = pd.DataFrame({'A':[1, 1, 2, 2], 'B':['a', 'b', 'a', 'b']})
print(df)

df.drop_duplicates('B', keep='first', inplace=True)
df
許多運算符號(>, ==, <, ~)都可以在Pandas作為篩選條件使用。
Many Conditional operators (>, ==, <, ~) could use in Pandas in conditional screening.
本篇程式碼請參考Github。The code is available on Github.
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[2] Python Data Analysis Library
[3] Data Wrangling with pandas Cheat Sheet
[4] DataFrame
[5] Data wrangling
[6] 【pandas】[3] DataFrame 資料合併,連線
[7] Pandas之drop_duplicates:去除重复项
