
特徵工程是把原始資料對應到後續評估分數的轉換過程,是在擬合模型前重要的步驟。常見特徵有:數值型特徵、類別型特徵與時間序列特徵,之後會有文章分別介紹。一般而言,我們取得的資料都會包含類別型(文字型)特徵以及數值型特徵,所以在特徵工程中就會包含進行編碼以及特徵縮放的部分。
Feature engineering is the process of turning raw data into features, it is an essencial step before we fit data to models. There are three types of frequently seen features: numeric features, categorical features, and time series features. We will discuss through them in the following articles. Generally, there will be both numeric features categorical features in our data, so we will have to include at least encoding and feature scaling methods in our feature engineering.
除了前面文章中提過的編碼方式外,這邊再列出幾種常見的編碼方式。要針對不同的問題類別選擇不同的編碼。
Some other mothods of encoding are listed as below. We decide which encoding method to use depend on the problem type.
把原始資料縮放到(0,1)的區間內,統一數據的衡量標準以消除單位的影響。Sklearn中最常用的方法是MinMaxScaler。
Transit raw data into 0-1 range. The most commonly used method in Sklearn is MinMaxScaler.
把資料按比例縮放到一個限定的區間。但如果資料不遵從高斯正態分布時,標準化表現會比較差。常用的標準化方法有Z-score、StandardScaler等。
Normalize data into a specified range. Normalization wouldn't perform so good if the distribution of data is far from normal. Most commonly used methods are z-score normalization, StandardScaler, etc.
資料分布偏斜的方向與程度,分為正態分布(及偏度=0)、右偏分布(正偏分布,偏度>0)、左偏分布(負偏分布,其偏度<0)。
Skewness is a measure of the asymmetry of the probability distribution. Could be either symmetric distribution (skewness=0), positive skew (skewness>0), or negative skew (skewness<0).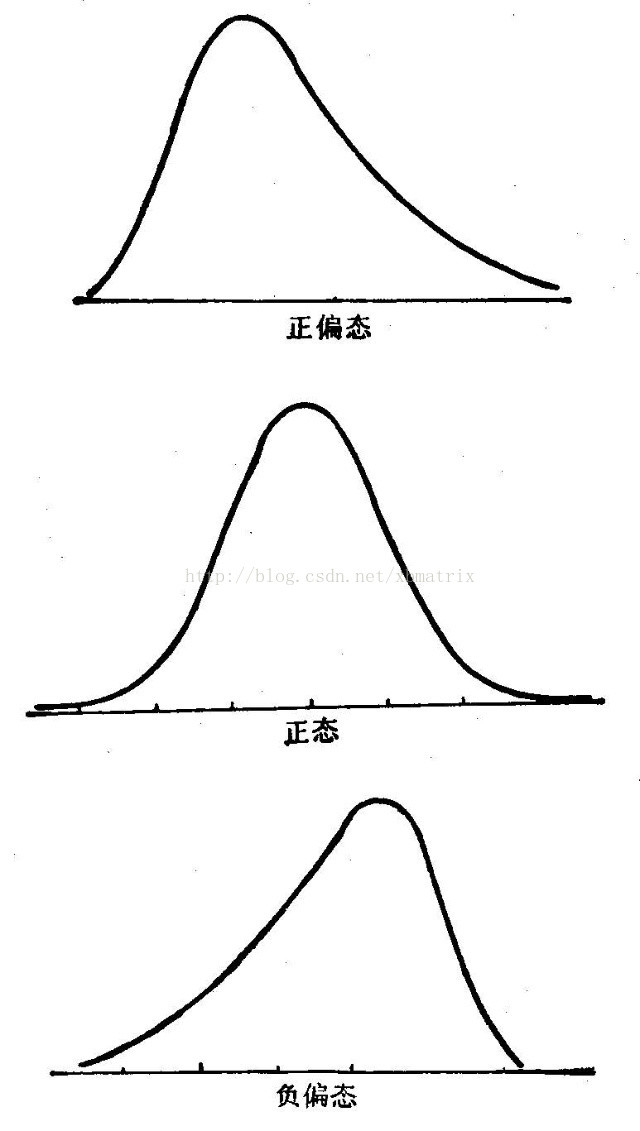
衡量分布的峰態。峰度包括正態分布(峰度值=3),厚尾(峰度值>3),瘦尾(峰度值<3)。
Kurtosis is a descriptor of the shape of a probability distribution.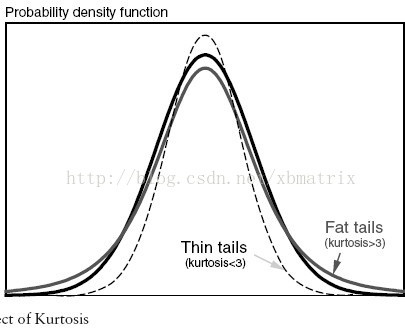
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[3] 特征工程
[4] 特征工程到底是什么?
[5] 一文看懂常用特徵工程方法
[6] 特征工程方法:一、类别变量编码
