
在Day04的文章中介紹了幾種常見可供替補N/A或離群值的數值,本日文章來實際操做,以Kaggle競賽Titanic: Machine Learning from Disaster作為使用的資料集演示。
In the Day04 article we talked about several values that could be used to fill N/As and Outliers. Today, we are going to show how to actually replace missing and extreme data with those values using the data downloaded from Titanic: Machine Learning from Disaster.
import pandas as pd
import numpy as np
import copy
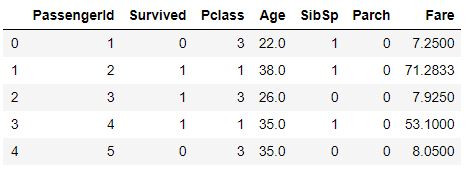
df = pd.read_csv('data/train.csv') # 讀取檔案 read in the file
df.head() # 顯示前五筆資料 show the first five rows

# 只取int64, float64兩種數值型欄位存到 num_features中
# save the columns that only contains int64, float64 datatypes into num_features
num_features = []
for dtype, feature in zip(df.dtypes, df.columns):
if dtype == 'float64' or dtype == 'int64':
num_features.append(feature)
print(f'{len(num_features)} Numeric Features : {num_features}')

# 去掉文字型欄位,只留數值型欄位 only keep the numeric columns
df = df[num_features]
df.head()
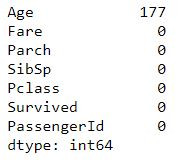
# 檢查欄位缺值數量 check N/As
df.isnull().sum().sort_values(ascending=False)
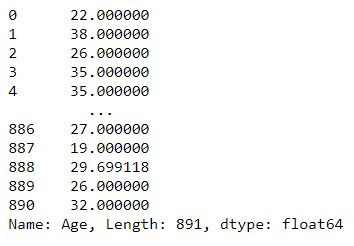
df_mn = df.fillna(df.mean())
df_mn['Age']
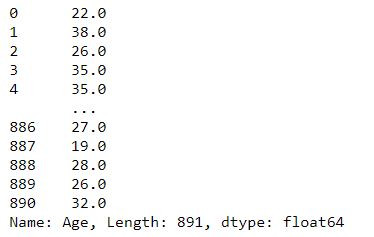
df_md = df.fillna(df.median())
df_md['Age']
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[2] Titanic: Machine Learning from Disaster
