
上一篇有說明Linear regression利用SGD來train,今天我們就把一些相關概念一次解釋清楚,之後在train模型,或者自己運用在自己的case上的時候會更清楚了解,如何運作,以及如何debug模型。今天主要會講兩個概念: Gradient descent以及Optimizer。
梯度下降 (Gradient Descent)
GD(Gradient Descent)主要是透過對loss function偏微分等方法,找出最佳的參數,是一個最佳化的方法。簡單來說就是透過微積分找極端值求出微分等於0的解。而爲什麼他會被稱為梯度下降法,因為這個方法會沿著梯度的反方向走,找出最小值。也因為Gradient Descent應用於各大Deep Learning or Machine learnig的方法。所以一般來說activation function都要找可微分的。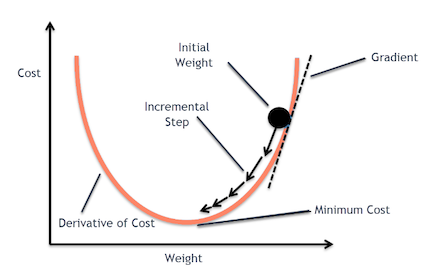
Gradient Descent
這邊我們跳過證明求導的部分,可參考李宏毅老師課程的部分,因此我們可以簡單將一個GD公式描述如下: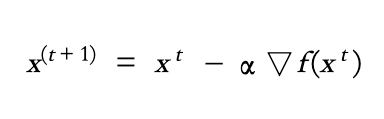
每次的更新可視為此次參數剪掉learning rate乘上gradient。這邊的t為第t次更新參數,alpha為learning rate。learning rate為控制每次要更新的大小。而learning rate的設定很重要,可以搭配下圖來看。假如設太大,一次跨步的距離太大,很有可能從這個山頭,直接跳到另外一個山頭。但設太小,有時候就像樹懶一樣,雖然最終會達到目的地,但是學習速度非常緩慢。因此,針對learning rate調整有許多方法,一般來說,在一個整個learning process,一開始的learning rate要比較大,後面learning rate逐漸變小,開始"地毯式"的搜尋。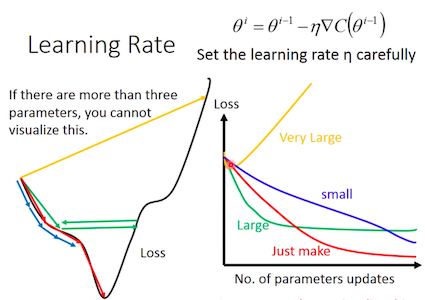
Learning rate 大小比較 (Sourece: 李教授投影片)
因此,learning rate需要隨著training 時間而改變,所以有許多研究改變了optimize的公式,讓training結果能更好 。
Adagrad
為了要解決learning rate隨著epoch而遞減,因此,有人有研究一些方法去改變update function,讓learning rate可以隨著時間針對某種要素改變。像是Adagrad。Adagrad主要概念就是將learning rate除以過去所有gradient的平方和。而運算過程如下: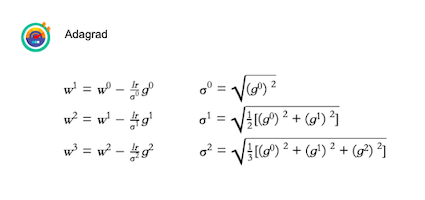
RMSProp
當然,Adagrad也有一些缺點可以改進。例如:隨著learning process,過去的gradient裡應來講重要性要越來越低,新的gradient的重要性相對要較高 (類似Decay的概念)或者是Error surface 太complex,讓adagrad無法解決 (learning rate需要忽大忽小)。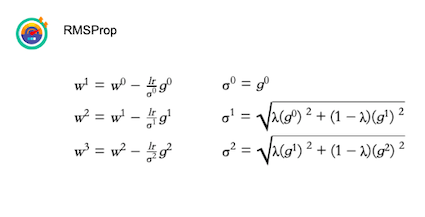
Adam
Adam就是RMSprop加上Momentum,因此一般來說,不管在DNN,CNN等等都會先使用Adam做為optimizer。
而什麼是momentum呢?在跑DNN或者NN的時候,有時候會看到momentum這個參數 ,大家可能會有疑惑想說Momentum是什麼東西?賣球鞋品牌?。Momentum簡單來說就是動能,若momentum參數調的適當,他除了可以增快學習速度,也可以透過動能可以讓GD在遇到local minimun的時候衝過去。簡單來說,就像一顆球在山波上丟下去,當下坡階段,球速度越來約快,你的learning速度也會越來越快,若設定太高,也有可能衝破Global minimun。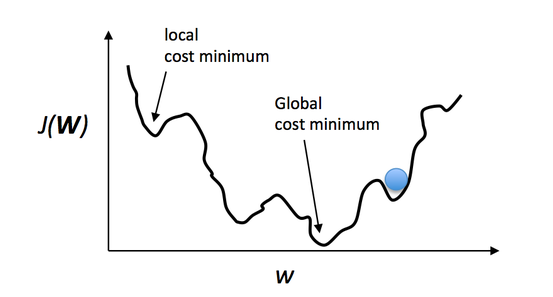
Momentum
因此,當加入Momentum,GD的update公式就會轉變成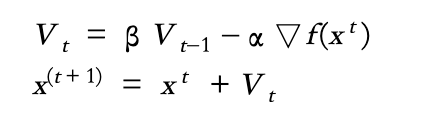
一般來說,Momentum所設定就是beta的參數。
TF2.0
一般來說,你在程式的model部分最常會看到這段code:
#optimizer
optimizer = tf.optimizers.Adam(learning_rate)
Tensorflow已經幫你把optimizer都做好變成api,因此你只要在tf.optimizers下去換即可。
大致上瞭解了GD到各式optimizer,接下來就會討論如何build一個NN或者DNN。感謝大家,漫長閱讀。了解SGD以及optimizer的應用對於在tune一些參數會更有感覺。之後會在其中一天說明overfiting 跟 underfiting的issue。
一日一梗圖:
Source

 iThome鐵人賽
iThome鐵人賽