
初次嘗試使用美味的湯爬資料,先做小一點的試試水。今天是從德國求職網站達石來下載職缺列表,先試看看不翻頁只爬第一頁100筆職缺訊息。
Today is my first try on BeautifulSoup, so the goal is to scrape 100 job posting on one page from Stepstone. This code doesn't contain page looping.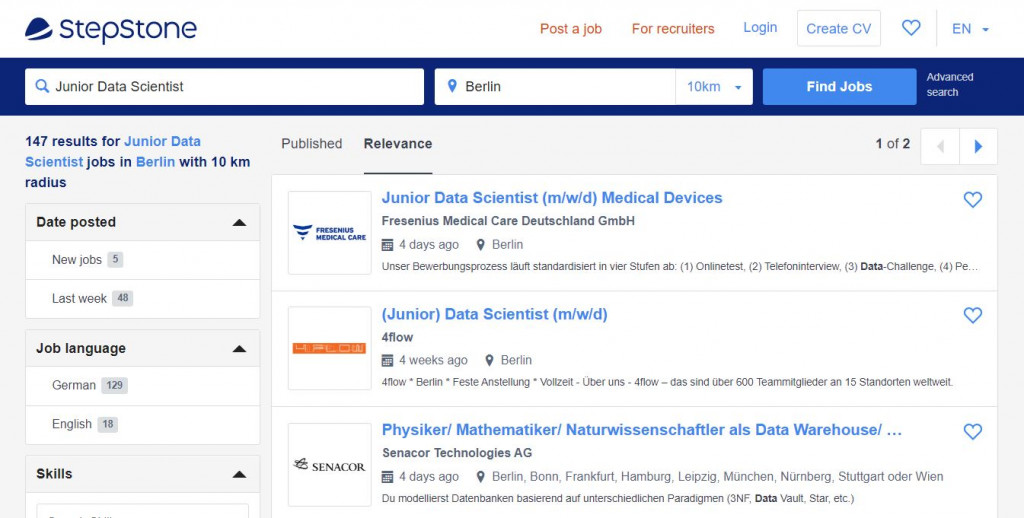
import requests
from bs4 import BeautifulSoup
# 指定網址 specify the url
url = "https://www.stepstone.de/5/job-search-simple.html?stf=freeText&ns=1&companyid=0&sourceofthesearchfield=resultlistpage%3Ageneral&qs=%5B%5D&ke=Junior%20Data%20Scientist&ws=Berlin&ra=10&suid=b830ebdc-e1ed-43cf-931b-006b0ad341c5&li=100&of=0&action=per_page_changed"
resp = requests.get(url)
resp.encoding = 'utf-8' # 轉換編碼至UTF-8 transform encoding to UTF-8
# 顯示網頁狀態,200即為正常 show the page status, code 200 means the page works just fine
resp.status_code
# 創建一個BeautifulSoup物件 create a BeautifulSoup object
soup = BeautifulSoup(resp.content, 'html.parser')
After cheking the code, we found that it seems like Stepstone saves each job posting using article. Print out the first one to have a look.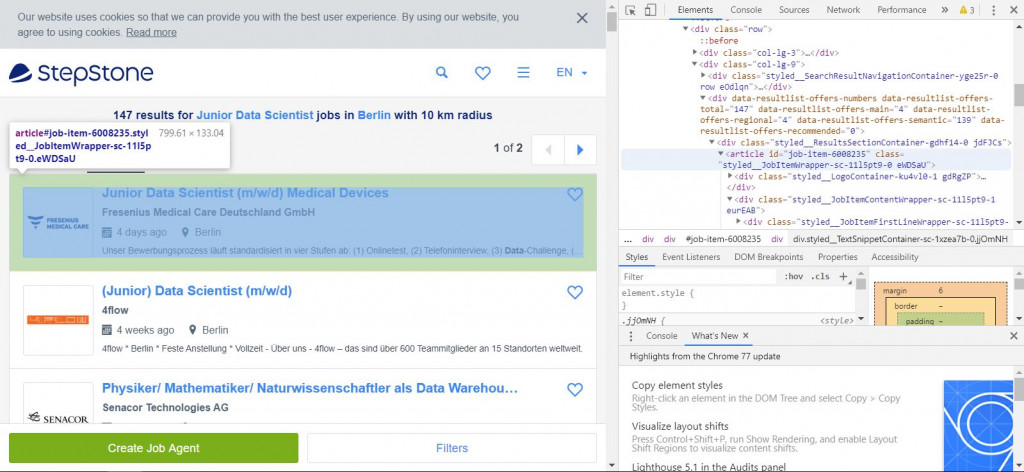
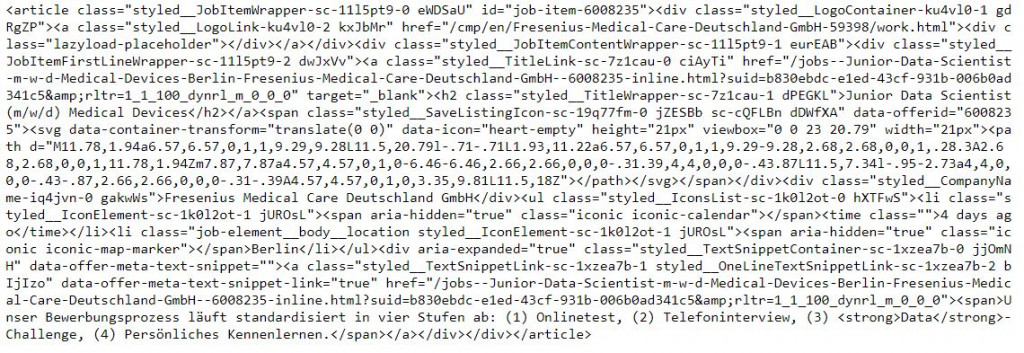
listing = soup.find_all('article')
print(listing[0])
Use .find_all() to save the job position into list.
job_list = soup.find_all('h2', attrs={'class': 'styled__TitleWrapper-sc-7z1cau-1 dPEGKL'})
jobs = []
for j in job_list:
job = j.text.strip()
jobs.append(job)
print(jobs[0:3])

Use .find_all() to save the company name into list.
company_list = soup.find_all('div', attrs={'class': 'styled__CompanyName-iq4jvn-0 gakwWs'})
company = []
for c in company_list:
comp = c.text.strip()
company.append(comp)
print(company[0:3])
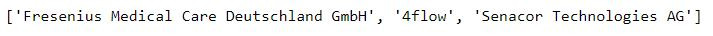
Use .find_all() to save the location into list.
location_list = soup.find_all('li', attrs={'class': 'job-element__body__location styled__IconElement-sc-1k0l2ot-1 jUROsL'})
location = []
for l in location_list:
locat = l.text.strip()
location.append(locat)
print(location[0:3])

Use .find_all() to save the short discriptions into list.
a = soup.find_all('a', attrs={'class': 'styled__TextSnippetLink-sc-1xzea7b-1 styled__OneLineTextSnippetLink-sc-1xzea7b-2 bIjIzo'})
description = []
for i in a:
des = i.find('span').text.strip()
description.append(des)
print(description[0:3])
len(description) # 確認筆數沒有錯 check if the post amount is correct

Transform the lists we created above into dictionaries then into dataframe. After that, save as csv file.
import pandas as pd
data = {'Jobs':jobs, 'Company':company, 'Location':location, 'Description':description}
df = pd.DataFrame(data)
df.head()

df.to_csv('df.csv')
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] Tutorial: Python Web Scraping Using BeautifulSoup
[2] Stepstone

 iThome鐵人賽
iThome鐵人賽