
在 day2 時,我們介紹了如何用 tf.summary.FileWriter() 產生 tfevent 來觀察 graph,但 tfevent 可以存的東西可不光光僅此如此,我們也可以將訓練過程中所產生的數字或權重存下,並產生圖表來觀察。
一樣,我們先打造模型結構,我們面對的問題和昨天一樣,是 xor 的分類問題:
global_step = tf.train.get_or_create_global_step()
x = tf.placeholder(shape=[None, 2], dtype=tf.float32, name='x')
y = tf.placeholder(shape=[None], dtype=tf.int32, name='y')
net = tf.layers.dense(x, 64, activation=tf.nn.relu6,
kernel_initializer=WEIGHT_INIT,
bias_initializer=BIAS_INIT,
kernel_regularizer=REGULARIZER,
bias_regularizer=REGULARIZER,
name='dense_1')
net = tf.layers.dense(net, 64, activation=tf.nn.relu6,
kernel_initializer=WEIGHT_INIT,
bias_initializer=BIAS_INIT,
kernel_regularizer=REGULARIZER,
bias_regularizer=REGULARIZER,
name='dense_2')
logits = tf.layers.dense(net, 2, kernel_initializer=WEIGHT_INIT,
bias_initializer=BIAS_INIT,
kernel_regularizer=REGULARIZER,
bias_regularizer=REGULARIZER,
name='final_dense')
這次我們來觀察 loss 值,共有 inference loss、weight loss 和 total loss 三種,另外我們也來記錄訓練過程中的準確度 accuracy,
inference_loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=y), name='inference_loss')
wd_loss = tf.reduce_sum(
tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES), name='wd_loss')
total_loss = tf.add(inference_loss, wd_loss, name='total_loss')
acc, acc_op = tf.metrics.accuracy(y, tf.argmax(logits, 1), name='accuracy')
套上昨天介紹的 gradient
opt = tf.train.GradientDescentOptimizer(learning_rate=0.1)
grads = opt.compute_gradients(total_loss)
train_op = opt.apply_gradients(grads, global_step=global_step)
產生我們需要的 tf.summary.FileWriter() ,此外,我們多宣告了一個 summaries 的 list,以便等等紀錄我們想要的數值。
summary = tf.summary.FileWriter(OUTPUT_PATH, graph=tf.get_default_graph())
summaries = []
而在 tfevent 中,想記錄 gradient 數值的話,適合用分佈圖來呈現,可以使用 histogram,而所有的 gradient 都可以在 opt.compute_gradients 取得, 以下就用 for 迴圈記錄一遍。
for grad, var in grads:
if grad is not None:
summaries.append(
tf.summary.histogram(var.op.name + '/gradients', grad))
而如果想記錄每層權重值的分布的話,也是使用 histogram,呼叫 tf.trainable_variables() 就可以取得該 tensor。
for var in tf.trainable_variables():
summaries.append(tf.summary.histogram(var.op.name, var))
最後是前面提到的 loss 和 accuracy 值,因為每個 step 各個值都只有一個值,所以適合用 scaler 來畫曲線圖,紀錄完這些數值之後,最後就用 tf.summary.merge 將 summaries 包起來即可。
summaries.append(tf.summary.scalar('inference_loss', inference_loss))
summaries.append(tf.summary.scalar('wd_loss', wd_loss))
summaries.append(tf.summary.scalar('total_loss', total_loss))
summaries.append(tf.summary.scalar('accuracy', acc))
summary_op = tf.summary.merge(summaries)
最後就可以丟參數訓練啦,每次想記錄時,就執行 summary.add_summary() 寫入。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for _ in range(0, 100):
x_v, y_v = get_xor_data()
_, _, summary_op_val, count = sess.run(
[train_op, acc_op, summary_op, global_step],
feed_dict={x: x_v, y: y_v})
summary.add_summary(summary_op_val, count)
print(f'iter: {count}')
summary.close()
產生 tfevent 後,我們就可以來判讀啦!第一個是整個模型圖: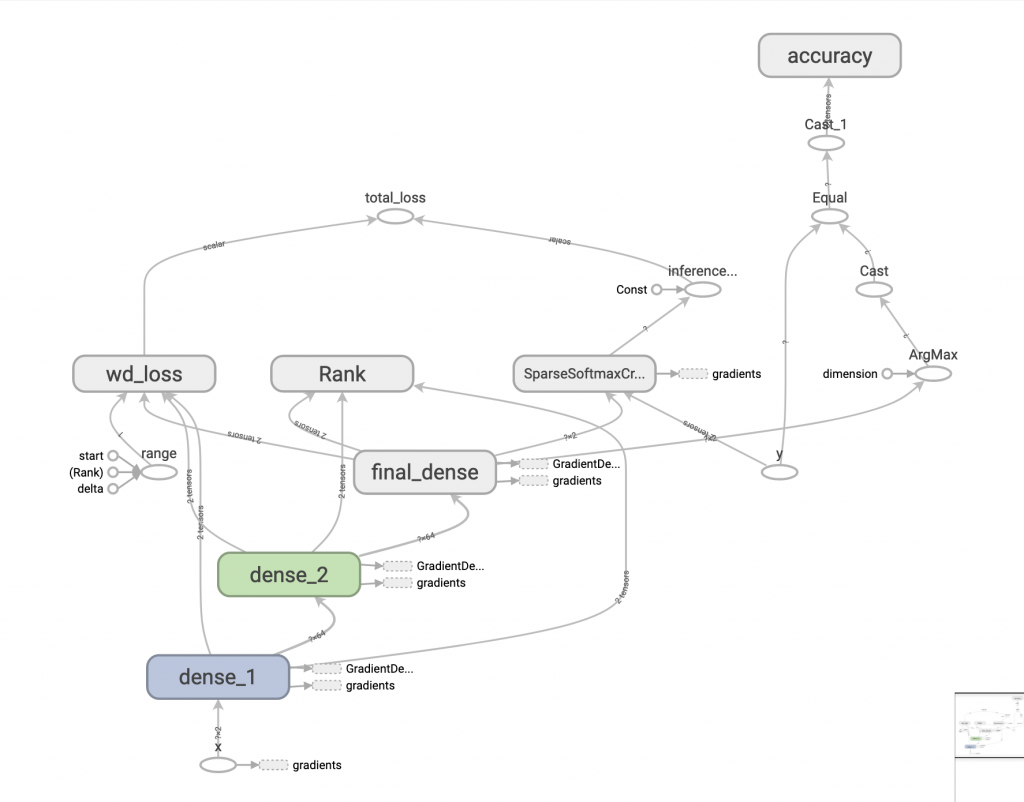
點擊左上方 scalars 可以看到曲線圖,我們先來讀 accuracy,x 軸是 step,y 軸是準確度,基本上可以看到曲線圖直線上升。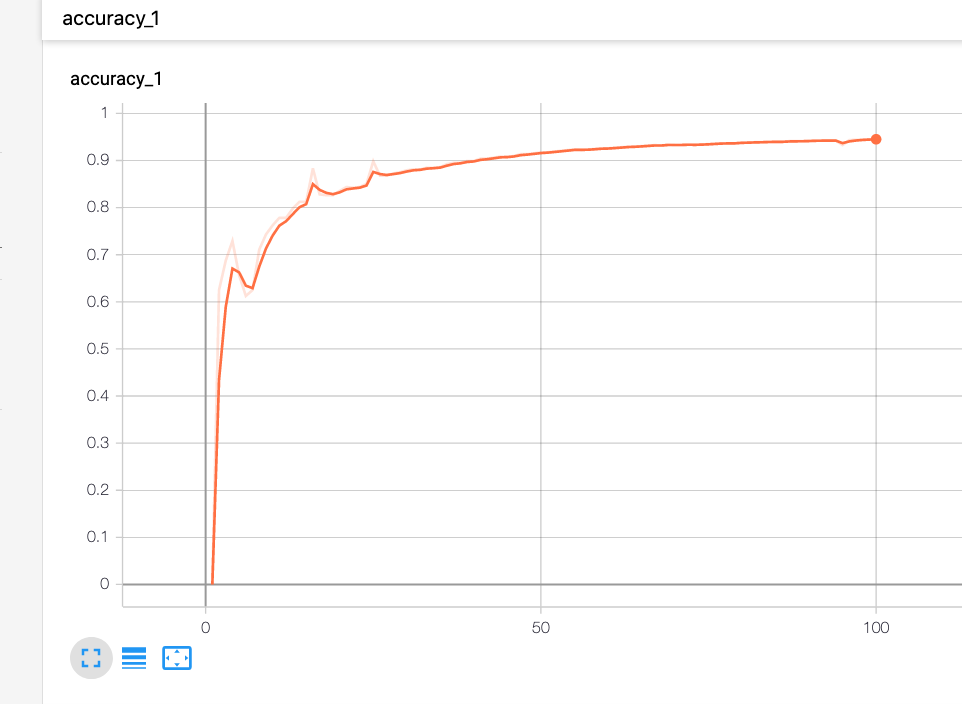
而為什麼圖中有實現和虛線呢?這是因為他有平滑度可以調整,左邊面板有個 smoothing,
接著來看 total_loss,也可以觀察到 loss 值隨著 step 下降。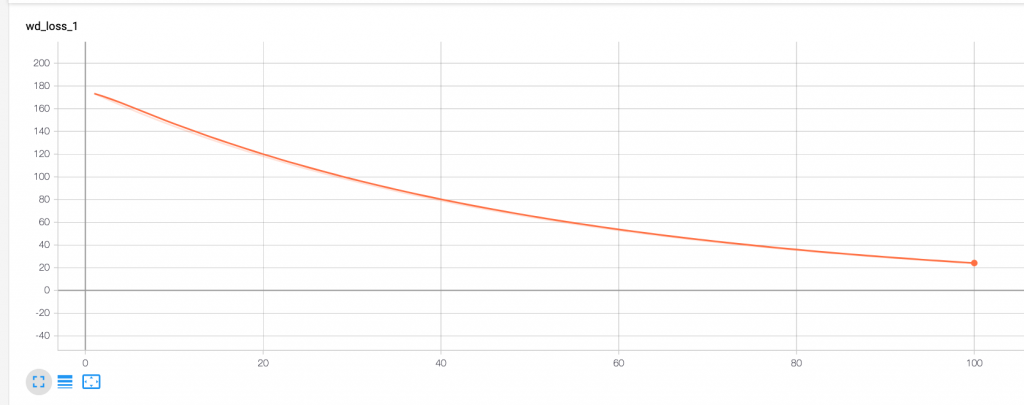
點擊左上方 HISTOGRAMS 我們來看權重值,以 dense_1/kernel_1 為例,x 軸是權重的分佈,y 軸是 step,你可以在圖表上移動滑鼠,tensorboard 可以看到鼠標的座標,而從圖表上也可以看到權重值範圍隨著訓練,從原本亂無章法的分散收斂變小。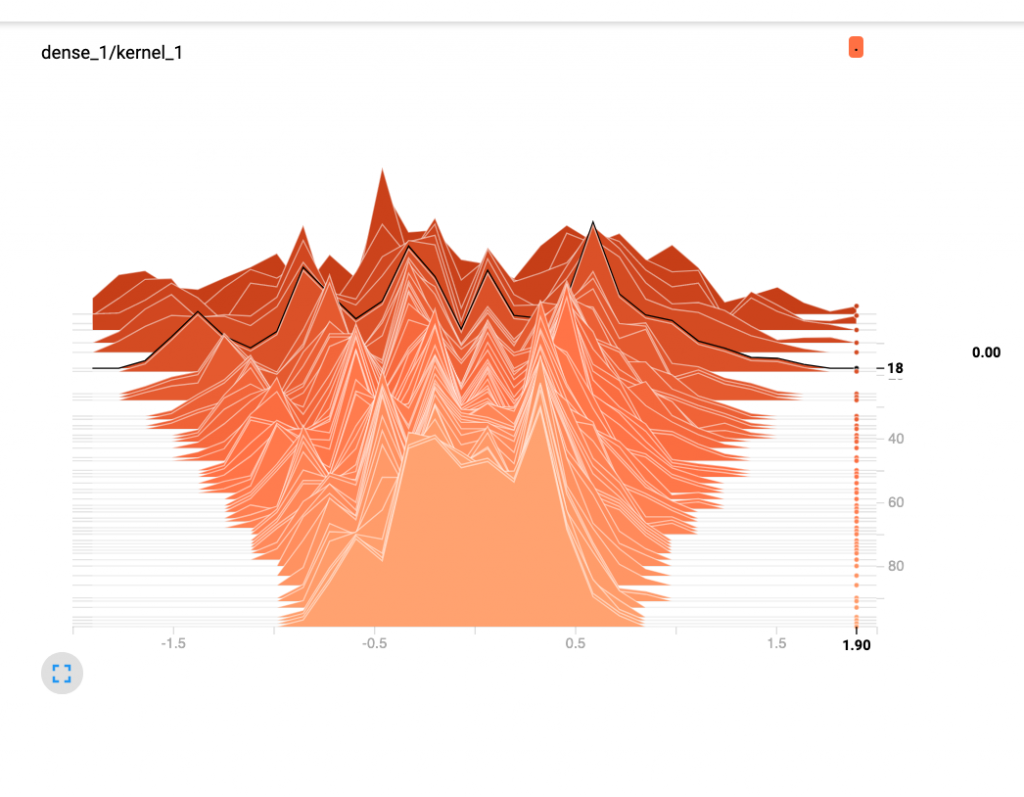
最後我們來看 dense_1/kernel/gradients 的變化,也可以看到 gradient 有很明顯地收斂狀況。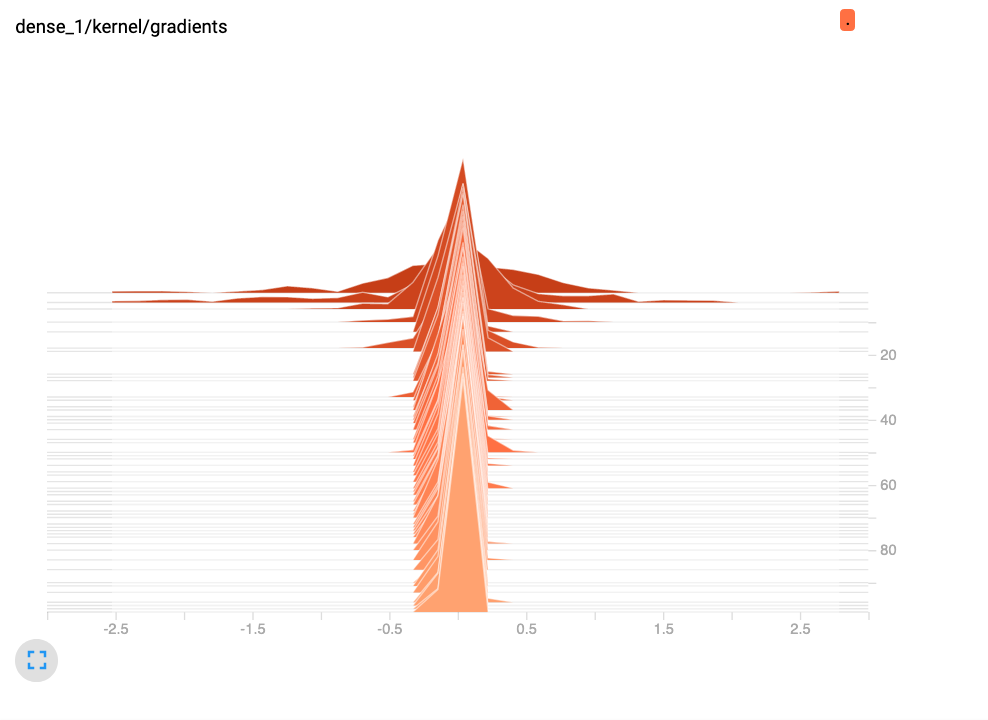
以上就是今天 tf_summary 的介紹,其實還有更多細節沒介紹,但其實都很好理解,就請大家自己去探索囉!

 iThome鐵人賽
iThome鐵人賽