前一篇介紹了 RNN 的模型結構,接著我們來測試幾個完整的應用,藉以了解各個環節如何使用 Keras 撰寫,內容包括:
先實作一個簡單的例子,程式修改自【官網】,完整程式碼為 26_01_IMDB_Using_LSTM.ipynb。
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# 只考慮 20000 個字彙
max_features = 20000
# 每則影評只考慮前 200 個字
maxlen = 200
# 可輸入不定長度的整數陣列
inputs = keras.Input(shape=(None,), dtype="int32")
x = layers.Embedding(max_features, 128)(inputs)
# 使用 2 個 bidirectional LSTM
x = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(x)
x = layers.Bidirectional(layers.LSTM(64))(x)
# 分類
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.summary()
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(
num_words=max_features
)
# 不足長度,後面補0
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
model.compile("adam", "binary_crossentropy", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=32, epochs=2, validation_split=0.2)
model.evaluate(x_test, y_test)
執行結果:
這個程式修改自【官網】,完整程式碼為 26_02_IMDB_Using_LSTM_complete.ipynb。
raw_train_ds = tf.keras.preprocessing.text_dataset_from_directory(
"aclImdb/train",
batch_size=batch_size,
validation_split=0.2,
subset="training",
seed=1337,
)
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode="int",
output_sequence_length=sequence_length,
)
# 去除 labels 欄位
text_ds = raw_train_ds.map(lambda x, y: x)
# 呼叫 adapt 函數建立字彙表
vectorize_layer.adapt(text_ds)
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# 呼叫 vectorize_layer 轉換資料
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
# 呼叫 cache/prefetch,獲得較佳的效能
train_ds = train_ds.cache().prefetch(buffer_size=10)
val_ds = val_ds.cache().prefetch(buffer_size=10)
test_ds = test_ds.cache().prefetch(buffer_size=10)
# Input for variable-length sequences of integers
inputs = keras.Input(shape=(None,), dtype="int32")
# Embed each integer in a 128-dimensional vector
x = layers.Embedding(max_features, 128)(inputs)
# Add 2 bidirectional LSTMs
x = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(x)
x = layers.Bidirectional(layers.LSTM(64))(x)
# Add a classifier
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.summary()
inputs = tf.keras.Input(shape=(1,), dtype="string")
# Turn strings into vocab indices
indices = vectorize_layer(inputs)
# Turn vocab indices into predictions
outputs = model(indices)
# 建立一個模型,使用已訓練的權重(in outputs)
end_to_end_model = tf.keras.Model(inputs, outputs)
end_to_end_model.compile(
loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"]
)
# Test it with `raw_test_ds`, which yields raw strings
end_to_end_model.evaluate(raw_test_ds)
以深度學習進行翻譯工作,是一個很好的方向,因為,全世界有幾百種文字,兩兩對轉就有幾萬種,若採用人工整理,不知要花費多少人力資源。上述的模型只需要最後的結果,而翻譯是一個 Sequence to Sequence 模型,我們需要每一個隱藏層的輸出,如下圖,才能輸出完整的字句。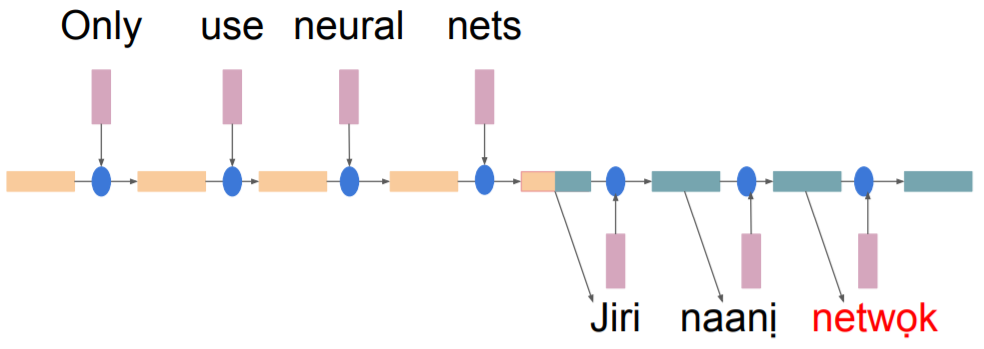
圖一. Sequence to Sequence 模型,圖片來源:CIS 530, Computational Linguistics: Spring 2018。
以下範例修改自【官網】,完整程式碼為 26_03_Translation.ipynb,原為英文翻法文,筆者改為英翻中。
decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True)
model.fit(
[encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
)

以上介紹自然語言處理(NLP)的簡單應用,還有許多的應用,尚待努力。
本篇範例包括 26_01_IMDB_Using_LSTM.ipynb、26_02_IMDB_Using_LSTM_complete.ipynb、26_03_Translation.ipynb,可自【這裡】下載。
有個題外問題想請教,https://keras.io/examples/vision/captcha_ocr/
這個例子,想請教前輩,為什麼要驗證碼辨識的模型CNN後,又要接Bidirectional LSTM,
用意在哪邊,想聽聽前輩的想法,謝謝~
因為驗證碼不只一碼,所以,可能是認為多個號碼有上下文關聯,故接Bidirectional LSTM,純屬臆測,還是應參考原作。

