2016年AI圍棋軟體AlphaGo連續擊敗韓國及中國等世界頂尖的好手,使得它背後的演算法 -- 強化學習(Reinforcement Learning)一炮而紅,發明AlphaGo的英國公司 DeepMind 也同時成為強化學習研發的龍頭,在此同時也出現了一位台灣之光 -- 黃士傑,因為他在每一次戰役中都擔任 AlphaGo 的代理人。
強化學習以 Try and Error 的方式,透過不斷的嘗試與學習,累積經驗,修正行動策略,在訓練成功後可以依情勢選擇較佳的行動決策。所以,它不只能下棋,也能應用到玩遊戲、機器人行走/揀貨/焊接、自動駕駛、醫療手術、股票投資...等方面,但是到目前為止,DeepMind 的發展還是集中在電腦遊戲的攻略上面,距離全面的開花結果,還待時間的考驗。
距離比賽要求還剩下三篇,我們就集中火力,針對強化學習一探究竟,了解其運作原理及相關程式的撰寫。
強化學習機制如下圖,非常簡單:

總而言之,強化學習的目的,就是經由代理人不斷的學習,累積經驗,找到最佳行動策略,在真正派上用場時,能將學習到的最佳策略應用到實戰上。
透過上面機制的描述,我們可以制定程式架構如下圖: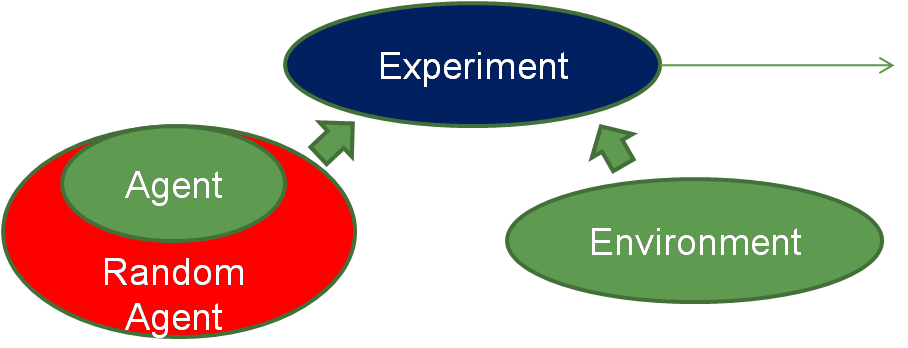
圖二. 強化學習程式架構
採取物件導向設計(OOP),總共有兩個類別,其職責(方法)如下:
最後撰寫成一個類別或一段程式,稱之為【實驗】(Experiment),用來建立環境、代理人兩個物件,讓系統動起來。
就上面設計規格,撰寫程式測試看看。
import random
class Environment:
# 初始化
def __init__(self):
# 最多走10步
self.steps_left = 10
def get_observation(self):
# 狀態空間(State Space)
return [0.0, 1.0, 2.0]
def get_actions(self):
# 行動空間(Action Space)
return [0, 1]
def is_done(self):
# 回合(Episode)是否結束
return self.steps_left == 0
# 步驟
def step(self, action):
# 回合(Episode)結束
if self.is_done():
raise Exception("Game is over")
# 減少1步
self.steps_left -= 1
# 隨機策略,任意行動,並給予獎勵(亂數值)
return random.choice(self.get_observation()), random.random()
class Agent:
# 初始化
def __init__(self):
pass
def action(self, env):
# 觀察或是取得狀態
current_obs = env.get_observation()
# 採取行動
actions = env.get_actions()
return random.choice(actions)
if __name__ == "__main__":
# 實驗
# 建立環境、代理人物件
env = Environment()
agent = Agent()
# 累計報酬
total_reward=0
while not env.is_done():
# 採取行動
action = agent.action(env)
# 進到下一步
state, reward = env.step(action)
# 報酬累計
#print(reward)
total_reward += reward
# 顯示累計報酬
print(f"累計報酬: {total_reward:.4f}")

為了讓強化學習開發者更容易入門,OpenAI公司開發了Gym 套件,提供一個標準架構,並實現許多個遊戲,讓大家可以盡情開發各種策略,進行實驗及演算法的開發。
Gym 套件安裝很簡單,執行下列指令即可:
pip install gym
但以上指令只會安裝簡單的文字遊戲(toy text)及傳統遊戲(classic control),如果要安裝全部遊戲,可執行下列指令,但是 Windows 環境下安裝會有錯誤,可以參考【How to Install OpenAI Gym in a Windows Environment】試試看,我照表操作是失敗的。
pip install gym[all]
Gym 官網如下:https://gym.openai.com/
Gym 官網沒有列出現成的遊戲名稱,只能參考【GitHub網站】,每個目錄代表一個類別,目錄內的每個檔案是一個遊戲。
使用說明在 【這裡】,並沒有列出每一個遊戲的規則,只能直接查看原始程式碼。
台車(Cartpole)是 Gym 套件內的一個遊戲,分兩個版本,CartPole-v0 規則如下:
Gym 程式架構與上述簡單架構相似,只是不必實作環境(Environment),即遊戲與規則,因為Gym都幫我們搞定了。以下採取隨機策略,實作台車(Cartpole)遊戲,程式碼如下:
import gym
import pandas as pd
env = gym.make("CartPole-v0")
total_rewards = 0.0
total_steps = 0
obs = env.reset()
no = 50
all_steps=[]
all_rewards=[]
while True:
# 隨機行動
action = env.action_space.sample()
# 進入下一步
obs, reward, done, _ = env.step(action)
# 渲染
env.render()
# 累計報酬
total_rewards += reward
# 累計步驟總數
total_steps += 1
if done:
# 重置
env.reset()
all_rewards.append(total_rewards)
all_steps.append(total_steps)
total_rewards = 0
total_steps=0
no-=1
if no == 0:
break
env.close()
沒有贏半個回合,真慘。可以參考【這裡】的程式,執行看看,會顯示在第幾回合,它贏得比賽。
筆者嘗試以不一樣的切入點介紹【強化學習】(Reinforcement Learning),希望能降低初學者進入的門檻,如果要照正規的路徑學習,可參考強化學習的聖經【Reinforcement Learning: An Introduction】,全書共548頁,只含基礎理論,要涉獵較新的演算法,需另外覓食。
本篇範例包括 28_01_agent_env.py、28_02_cartpole_random.py,可自【這裡】下載,程式需要渲染畫面,Jupyter Notebook 無法顯示,故直接使用 Python 檔。

