回應上一篇關於詞嵌入Token Embedding的討論,BERT的輸出就是文本序列中每個詞單位的高維向量表示,你也可以把它當成一連串抽取的特徵。所以BERT類型的模型本質上做的是抽取特徵的工作,也有人把負責這個過程的模型稱為Encoder,將原始資料變成計算機方便運算、可以理解的格式。在進入後續的Decoder,也就是為不同類型的具體任務設計模型輸出之前,讓我們先釐清BERT的輸出是什麼、格式如何、有什麼意義。
如果你還不太了解BERT的機制,對於深度學習也缺乏實作經驗,而只是先使用了一些範本Script跑BERT模型,你可能會困惑於BERT的輸出。因為在Python中列印這些輸出,你只會看到一連串數字的排列。如果用shape或size之類的功能查看維度,你通常會獲得類似下方的輸出:
torch.Size([12,160,768])
看上去是一個三維的矩陣,但不同的數字各自代表什麼意義,每一個維度又是什麼。這好像與我們之前所說的每一個詞都被編碼為高維度向量不一致。別著急,讓我們先來瞭解一下在實作中BERT模型的運算過程。
<CLS>,<SEP>等),所以送給模型的序列長度通常比原始資料的文本長度更長一些。以上三個概念正是對應於BERT Encoding後的模型輸出的三個維度的數值。在上面的例子中,12代表Batch Size為12,160指的是該批次中最長的樣本的序列長度(其他短於160的樣本則被<PAD>補齊到160),768則代表Hidden State Size,說明這是一個Base版本BERT模型的輸出,每一個詞都被轉化為768維的向量了。它們共同構成了一個三維的大型矩陣。
以視覺化的方式來理解則是這樣:
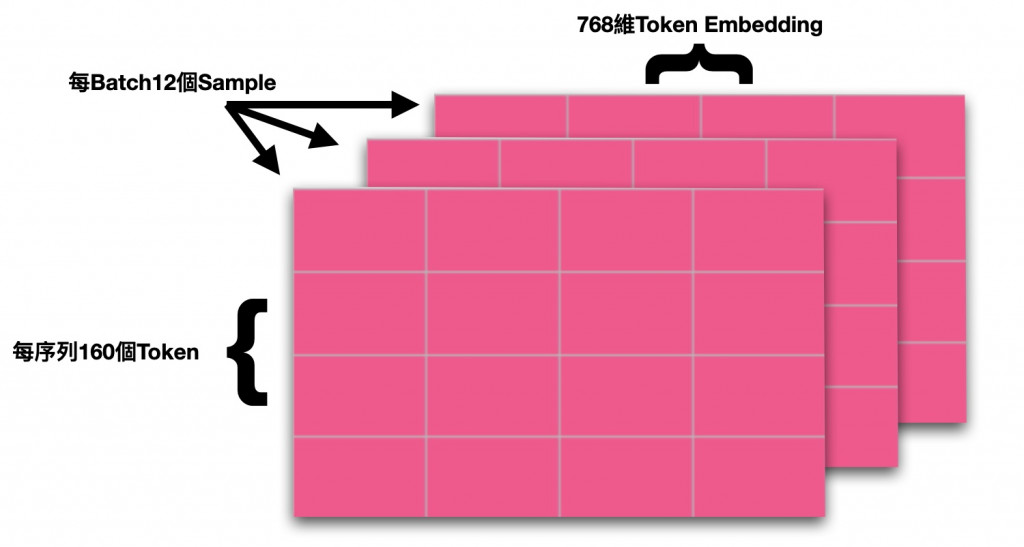
理解清楚輸出的格式對於後續的實作會有極大幫助,許多時候模型的資料處理的問題都出在矩陣維度上。
Word2Vec生成的詞嵌入大概已經成為NLP的常識了,國王-王后或是各國名稱與首都在空間上的相似距離這類說明已經有不少人進行過講解。現在的問題是BERT所輸出的Contextualized Word Embedding與一般的Word Embedding有什麼差別?
這方面也有人做過具體的研究了,以Cold這個詞為例,通常有以下三種可能的意義:溫度上的冷、態度上的冷或症狀上的冷(醫學中使用)。而Yuqi Si等人的研究就是針對BERT研究Cold的嵌入表達是否能有效區分出它在不同脈絡下的意義。以下這張圖是我們理想中的結果,中間的X代表Word2Vec這種固定的詞向量,而周圍三個則是BERT針對不同脈絡下的嵌入表達。
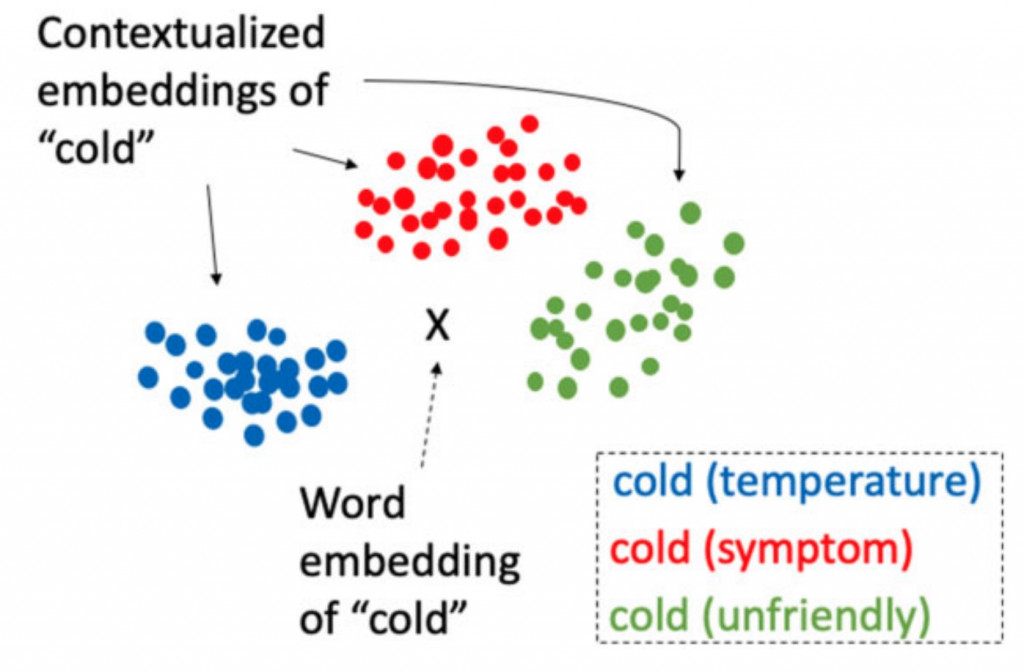
實驗證明,BERT確實很好地完成了這項任務,而在MIMIC(一個臨床文本資料集)上預訓練的BERT則比在維基百科等通用文本上訓練的BERT表現得更好:
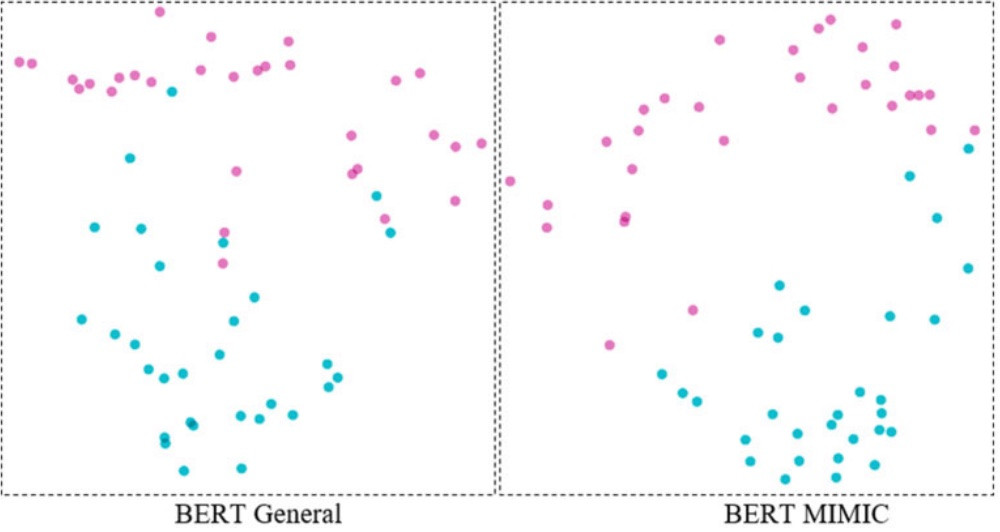
這張圖片中的粉色代表溫度意義上的Cold,而藍色則代表症狀意義上的Cold。這張圖是PCA降維後的結果,將768維向量降到2個維度,方便視覺化展示。所以,尤其在一些用語意義與一般情境不同的專業領域,BERT這類預訓練模型因為其區分的精細程度更好、有上下文脈絡,而可以比Word2Vec發揮更大的用途。
今天的BERT輸出只是簡單介紹,後續我們還會有一篇專門文章來討論BERT模型不同層之間的嵌入差別。但這要在講解完BERT模型的一些內部結構(Transformer)之後,敬請繼續關注。
Si, Y., Wang, J., Xu, H., & Roberts, K. (2019). Enhancing clinical concept extraction with contextual embeddings. Journal of the American Medical Informatics Association, 26(11), 1297-1304.


 iThome鐵人賽
iThome鐵人賽