
要來討論今天主題前,先來複習一下什麼是交叉熵 Cross-Entropy ,我覺得這部影片介紹得很不錯,簡而言之,我們可以將交叉熵當作資訊的亂度,也就是我們一般所說的 loss 值,在做機器學習訓練時,我們訓練的目的是將這個值降的越低越好,而根據交叉熵的公式可以得出,要讓這個值變小就需要預測值和真實值越符合。
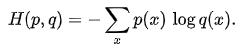
而在 Tensorflow 中,提供了三種交叉熵可以使用,分別是CategoricalCrossentropy, SparseCategoricalCrossentropy 和 BinaryCrossentropy。
我們今天主要介紹 SparseCategoricalCrossentropy 和 CategoricalCrossentropy 兩者的使用方式和模型訓練比較。
從名稱來看 Sparse 及代表稀疏的意思,也就是說這個訓練集的資料中,在最後一層的dense node 只會有一個是1其他都是0,假設是mnist,視覺呈現上如下
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[1 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 1 0 0 0 0 0 0 0 0]
也因為每筆資料只會對一個屬性為1,所以訓練時可以不用手動去做 one-hot 的動作。
相對CategoricalCrossentropy 的應用場景,一筆資料可能在其他屬性上也可能是1,假設今天的分類器是分析人臉屬性,我們的 label 可能是[男 女 高興 生氣 難過 有眼鏡 有鬍子],那麼資料視覺呈現可能就會是
[1 0 0 1 0 0 1] # 一位有鬍子表情生氣的男性
[0 1 1 0 0 1 0] # 一位有眼鏡表情高興的女性
[0 1 0 0 1 0 0] # 一位表情難過的女性
[1 0 0 1 0 1 1] # 一位有鬍子有眼鏡表情生氣的男性
實驗一: SparseCategoricalCrossentropy
前幾天的訓練中,我們持續使用的 entropy,在使用時,需要注意 label 必須是個 integer ,也就是像這邊如果有102個分類,那餵進來的前五筆 label 必須是 [32, 44, 72, 100, 82] ,直接表明是第幾個 label 的編號,所以在normalize_img中,我們直接將 label 輸出即可。
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., label
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 5.0338e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4206 - val_sparse_categorical_accuracy: 0.8775
實驗二: CategoricalCrossEntropy
如上所述,由於一筆資料可能會有多個屬性(雖然我們用的這個資料集不是),所以我們必須將 label 做 one-hot 轉換。
def normalize_img_one_hot(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., tf.one_hot(label, NUM_OF_CLASS)
def normalize_img_one_hot(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., tf.one_hot(label, NUM_OF_CLASS)
ds_train = train_split.map(
normalize_img_one_hot, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img_one_hot, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
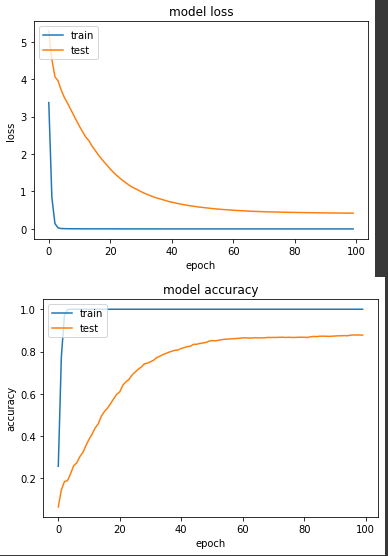
產出:
loss: 3.9605e-04 - categorical_accuracy: 1.0000 - val_loss: 0.4483 - val_categorical_accuracy: 0.8804
從結論來看,兩者最終的準確度都差不多,CategoricalCrossEntropy 略高一些,但從收斂速度來看,SparseCategoricalCrossentropy 在第38個 epoch 準確度達到80%,CategoricalCrossEntropy 則是第42個 epoch 準確度達80%,但如果說我們都確定今天這個資料集每筆只會有一個屬性為1的話,當然還是建議大家直接使用SparseCategoricalCrossentropy。
