今天來整理一下以前的筆記,聊聊比較分類模型的評判依據:confusion matrix.
下圖是常見的confusion matrix的圖: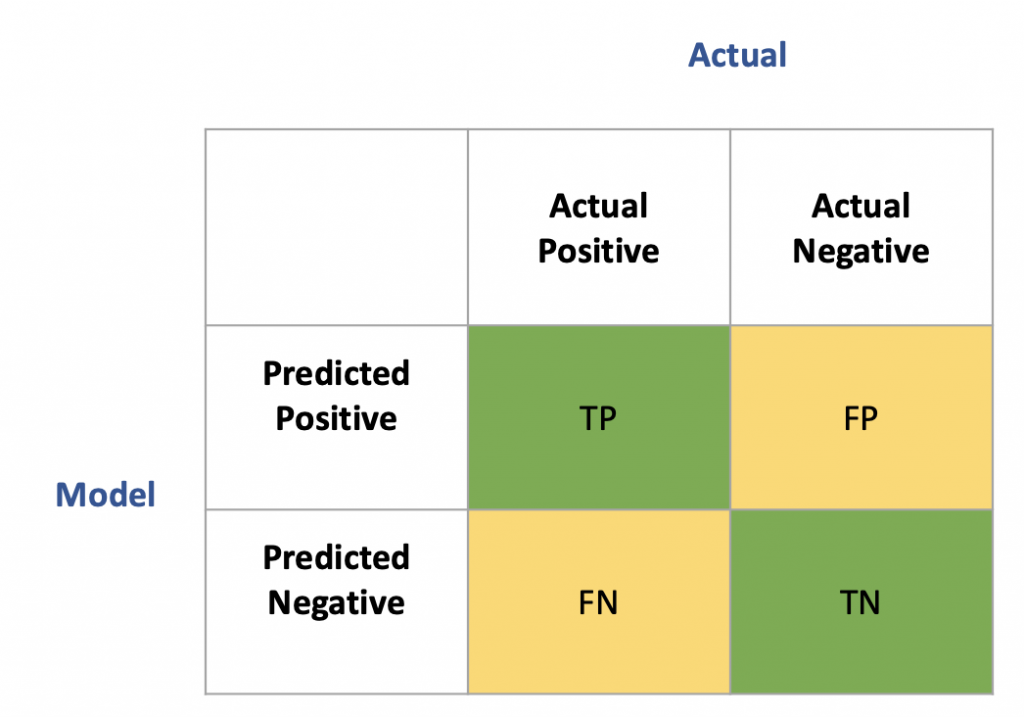
用個例子來解釋上圖:
假設我們今天根據血壓身高體重等資料預測一群人是否有心臟病
TP(true positive):實際有心臟病且模型預測正確(有)
TN(true negative):實際沒有心臟病且模型預測正確(沒有)
FP(false positive):實際沒有心臟病但模型預測說有,又稱 type1 error
FN(false negative):實際有心臟病但模型說沒有,又稱 type2 error
所謂的true/false表達的是模型預測是否正確,而positive/negative會根據假設對應不同的情況,我們都希望模型預測高,所以會希望TP/FP的數量高,當純比較數字會有點難以比較不同的模型,所以之後就衍生出了不同的比率,常見的有:
根據不同的情境會使用不同的比率來比較,如果今天識別“有心臟病”的病患是主要目標,那我們就可以選擇recall rate當評判標準,反之若識別“沒有心臟病”的病患是主要目標的話,就可以使用specificity。

