近年來以谷歌的 Google Assistant 、蘋果的 Siri 和微軟的 Cortana 為首的聊天機器人能夠如真人一般與人類進行日常聊天,成為大家所關注的焦點。而甚至有消息指出現在的 AI 技術也能自己寫程式了,究竟 AI 是如何接收資訊並做出決策,產出人類可以識別的自然語言呢?在上回的探討中,我們瞭解到機器翻譯的第二階段就是生成人類可閱讀的文本,於是今天我們就來聊聊機器如何寫文章。

圖片來源:Medium
文本生成( text generation )泛指所有根據輸入資料進而寫出人類可讀的是語句或是文件的過程,又稱為自然語言生成( natural-language generation, NLG )。輸入的資料可以是文本資料、影像資料或聲音訊號等等,而輸出的語句本身因著單詞的多寡與排列會有不同的意義,是一種帶有次序性的資料( sequential data )。模型最終預測出序列出現的機率,因此文本生成是一類序列預測問題( sequence prediction problem )。
文本生成的應用相當廣泛,從先前提過的翻譯器、聊天機器人、能夠根據使用者口語的提問進行精確回答的問答系統( question answering system ,更分為基於聲音或是基於文字的系統)、看圖說故事的圖像描述( image captioning )到自動天氣預報等等。
根據圖像產生情境描述:
圖片來源:www.tensorflow.org
在這一小節我們將關注的範圍限縮在輸入文字資料以產生文字資料的過程。一般而言,輸入的文字資料為一個到多個句子,因此可視為文字序列。而輸出的文本按照容易到困難又可以區分為生成一個單獨的字符和生成單詞。
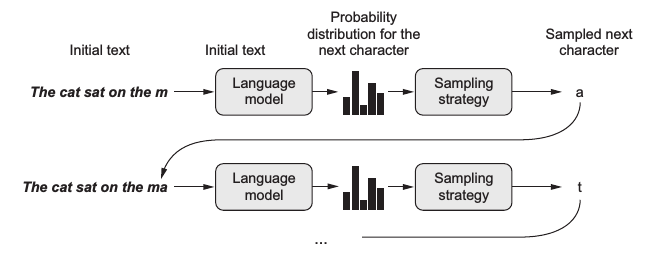
當見到一段未完成的文句:「 It's winter and the roa 」,我們也許會猜測下一個出現的字母是 d 。
我們可以訓練模型一個字母一個字母地預測,直到寫出一個整個句子,被稱為是 character-level text generation 。
當我們看見一段文字:「It's winter and the road is covered with 」,不難會聯想到下一個出現的單詞很可能為snow 。這種給定單詞序列到生成單詞的過程被稱為 word-level text generation 。相較於只預測下一個字符的模型,訓練的時間較久,但是精準度較高。
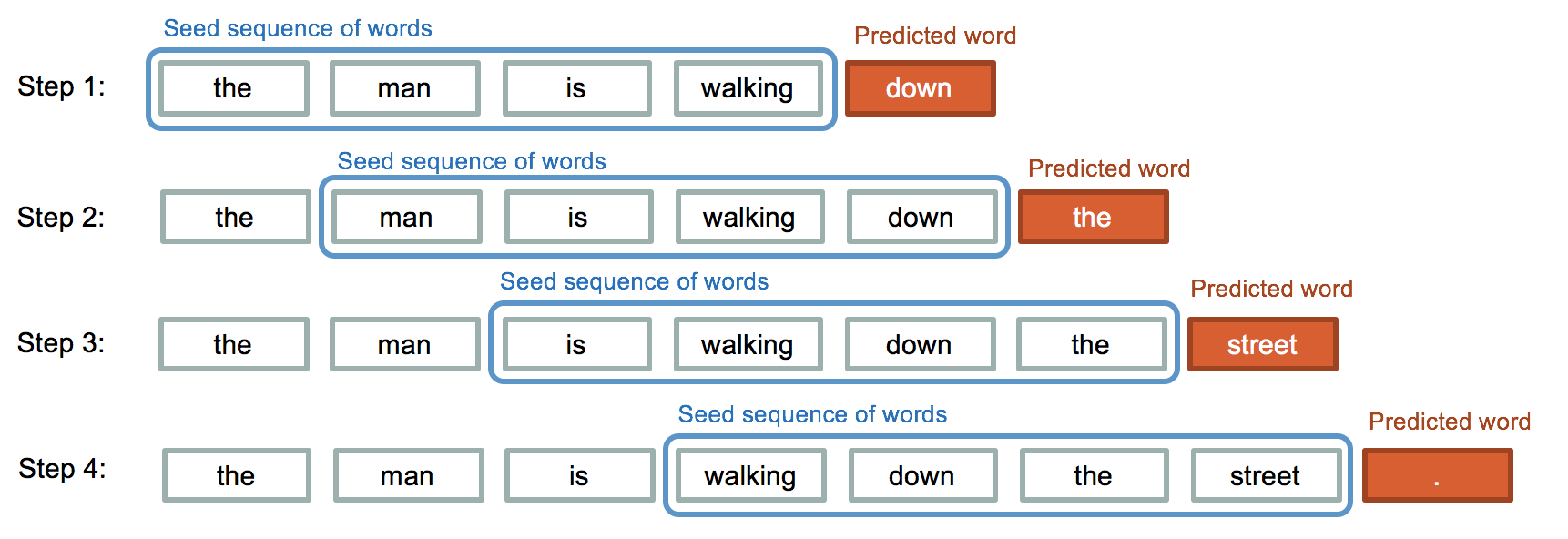
圖片來源:iq.opengenus.org
今天的介紹比較簡短,也還沒搆著神經網絡的核心,明日再接再厲!