也許你會覺得,這個標題下得很神經。沒錯!因為今天要正式進入新的主題-神經機器翻譯。我們今天將會從機器翻譯這個課題出發,綜覽在自然語言處理的發展中機器翻譯演算法的演進,最終深入現今主流的深度學習翻譯架構。
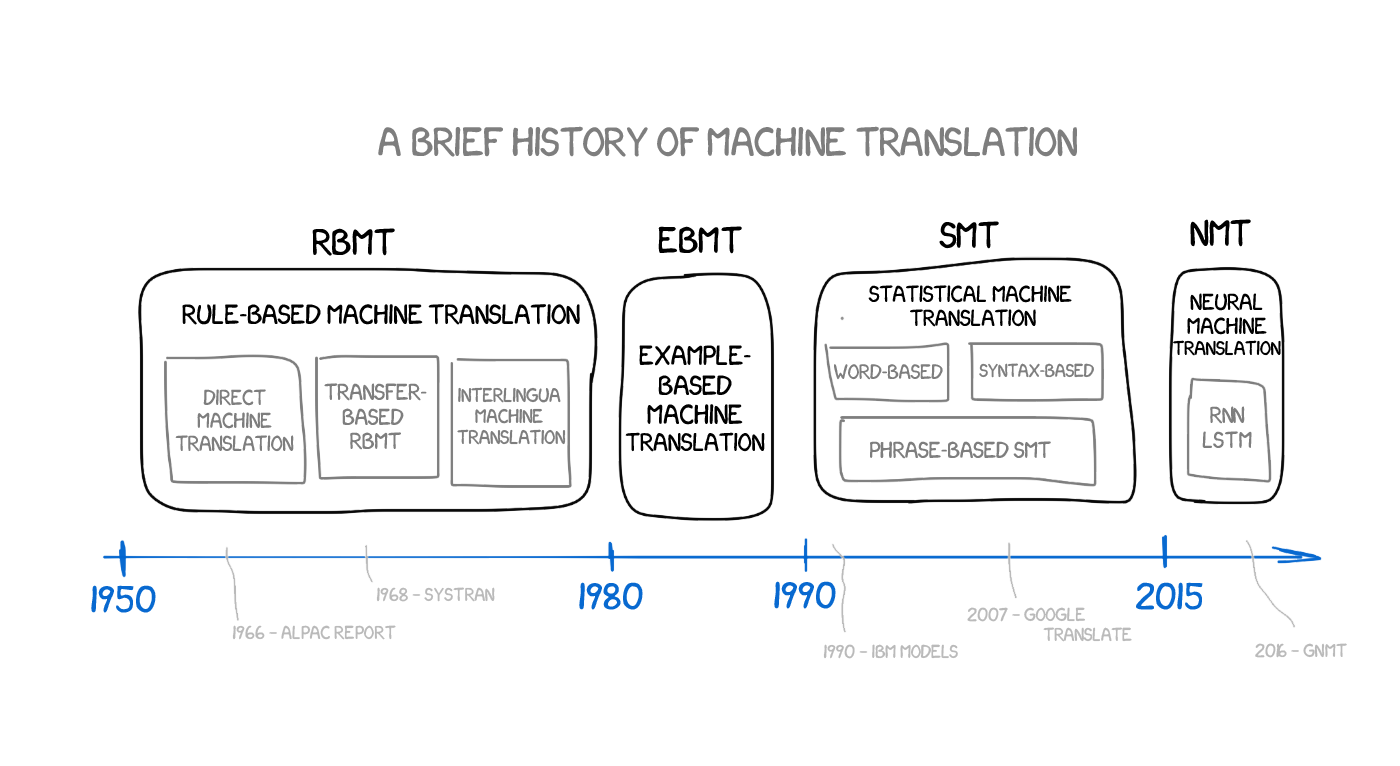
機器翻譯( machine translation )就是演算法將一段文字訊息從來源語言( source language )轉換為目標語言( target language )的過程,既保留語意又符合文法規則,長久以來一直都是自然語言處理中的熱門研究議題。以處理方法來區分,伴隨著自然語言處理的演進,機器翻譯歷經了四個重要時期,由早期到現代分別為: rule-based machine translation ⟶ example-based machine translation ⟶ statistical machine translation ⟶ neural machine translation ,分別由以下簡述:
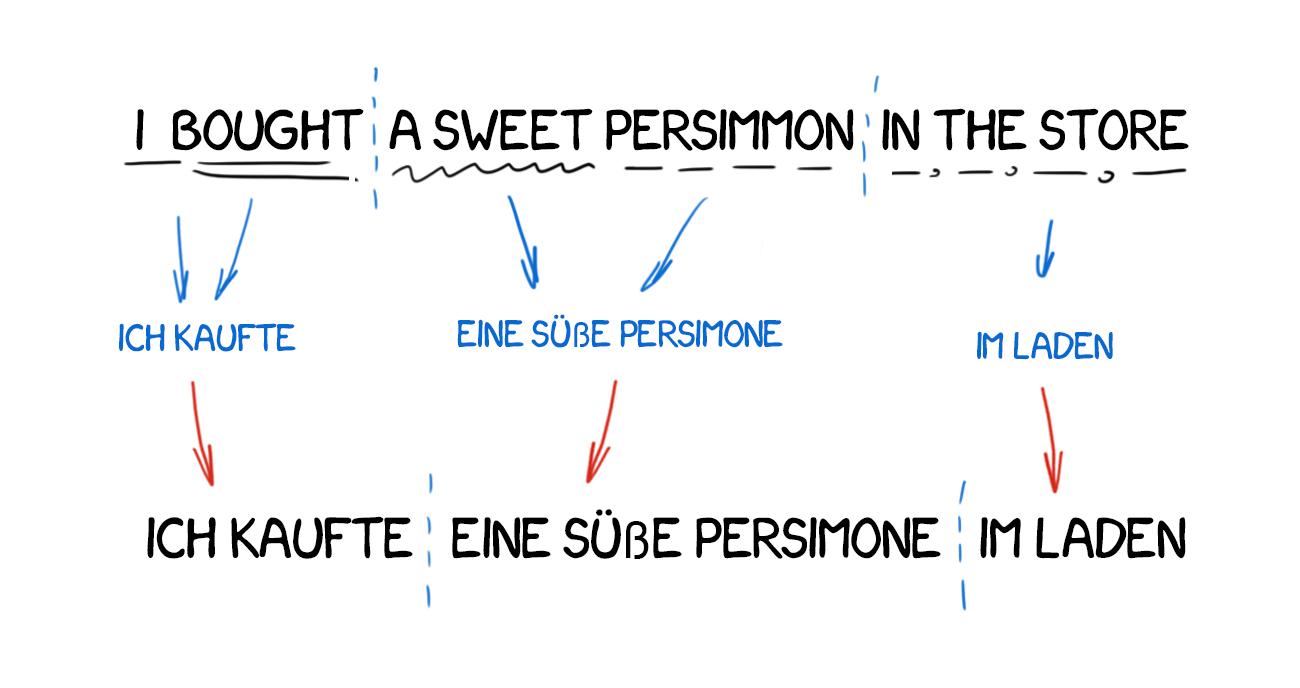
最早期的處理手法須必須仰賴手刻來源語言和目標語言的單詞對應辭典和語法規則。過程中會使用 rule-based 前處理方法如斷詞( tokenisation )、詞性標註( POS tagging ),藉由部分語法分析( partial parsing ,詳見本系列第七天關於語法分析的介紹)來確立兩種語言的文法結構,以生成一段目標語言的句子。RBMT翻譯系由層次低至高可分為 direct system ⟶ transfer system ⟶ interlingual system ,有興趣的讀者可參閱下方參考資料 [2]。另外,維基百科以英文翻譯成德文為例解釋了RBMT的一般處理流程,因此我們就不贅述。
Transfer system以分析語塊分析來對應片語:
上述的 rule-based 翻譯系統適用於語言學分支、語序接近的兩種語言,如英文⟷德文,但若要從英文翻譯成日文就會碰上則制定文法規則與兼顧語意對應關係十分複雜的挑戰。 EBMT 不需要手刻大量的文法規則,而是透過匹配雙語平行文本( bilingual parallel corpus )中的例句來進行翻譯。雙語文本將來源語言與目標語言具有相同語意的例句一一對應並條列出來,每行成對的例句僅在絕對位置上有少數單詞的差異。
雙語文本中的平行例句對:
輸入文句之後,系統會搜尋來源文句中與之最接近的例句,並在辭典中找尋缺失單詞對應的單詞,填入空缺來生成目標文句。
EBMT的翻譯流程:
另一種翻譯方式則是估計條件機率分布,其中 s 與 t 分別為雙語平行文本中來源語言和目標語言的文句,並找出具有使得有最高機率值的語句
。
下圖簡單說明了 SMT 如何利用貝氏定理( Bayes theorem )將德文的「 Ich liebe dich 」(我愛你)翻譯成英文: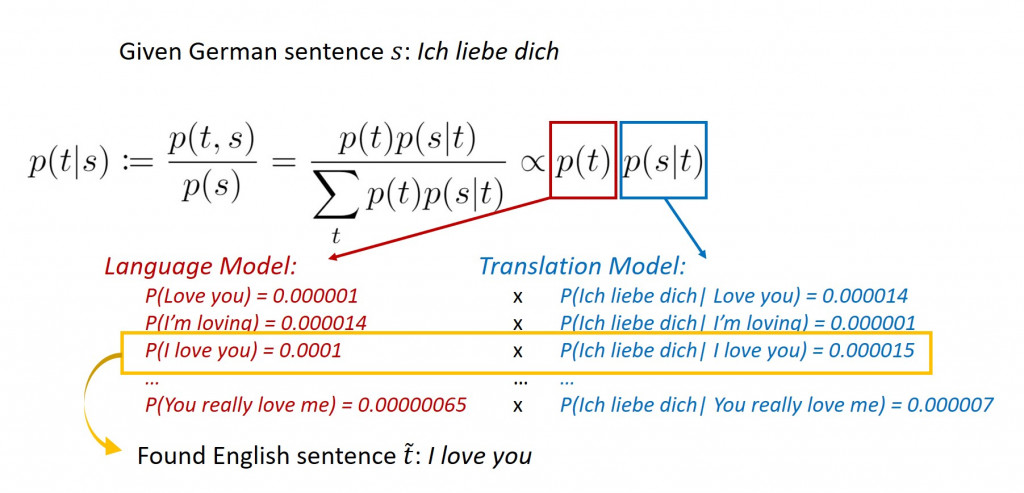
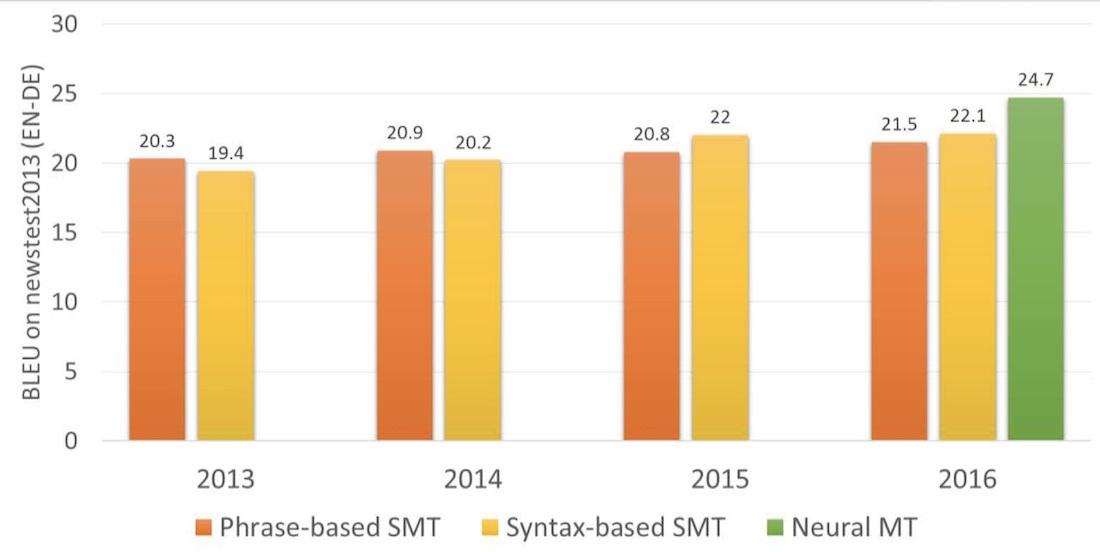
2014年 Google 團隊首次發表論文將深度神經網絡運用翻譯任務上,使用了長短期記憶( long short-term memory, LSTM )將英文翻譯成法文,開啟了機器翻譯的新紀元。由於文句本質上是單詞與標點符號所構成的序列,翻譯任務被看作是序列到序列的推論過程。神經網絡架構的翻譯器較先前提出的統計模型有較好的翻譯表現( BLEU, bilingual evaluation understudy 是用來評估機器翻譯品質好壞的指標),因此 NMT 成為了今日機器翻譯領域的主流。
相對於SMT,NMT取得較高的 BLEU比分:
機器翻譯發展的里程碑:
圖片來源:translartisan.wordpress.com
一個神經機器翻譯系統主要由編碼器( encoder )與解碼器( decoder )所組成。句子中的單詞依序傳入神經網絡的神經元,先是分別在來源語言底下進行 word embedding 成為向量之後,傳入由質神經網絡構成的編碼器進行編碼。編碼器內由數個記憶細胞所構成, word embedding 序列的前後依賴資訊被記錄在記憶細胞中的內部狀態( weight 與 bias 等參數)。編碼過後的序列之後再傳入解碼器,解碼器內部一樣具有記憶細胞以紀錄目標語言底下 word embedding 的次序性。差別在於當下經過預測得出的 word embedding 會作為輸入值傳入下一個記憶細胞。最後將依序輸出的 目標語言 word embedding 還原成自然語言,完成向量序列到向量序列的翻譯工作。
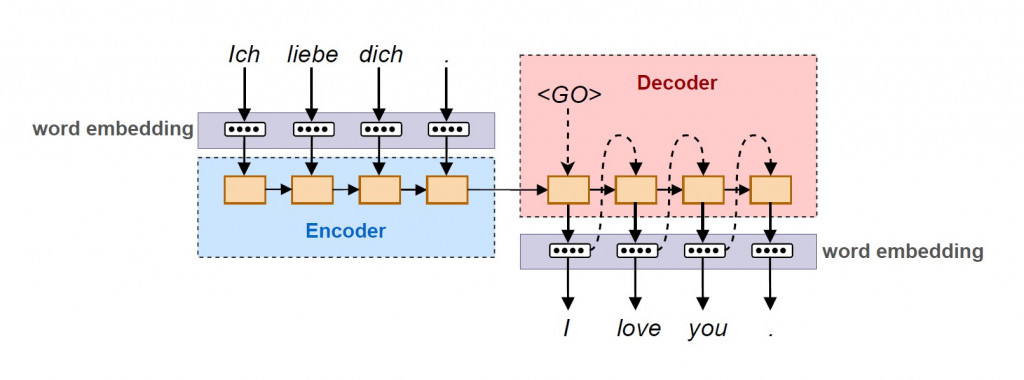
編碼器可由單純的 RNN 或其衍生模型 LSTM 、 GRU 等具有記憶性質的神經網絡所構成。而 RNN 對於向量序列編碼到單一向量時會出現問題,因此後期在編碼器到解碼器之間又出現了可以依照重要程度分派注意力的 attention 機制。
LSTM記憶細胞的設計架構:
圖片來源:Designing neural network based decoders for surface codes
今天我們快速瀏覽了各時期的翻譯手法,最後駐足在以神經網絡為基礎的翻譯模型,也是今日的主流。在 Google 將神經網絡全面投入翻譯系統之後,筆者親自感受到其翻譯品質的大幅提升,許多令人啼笑皆非的翻譯結果都已成為過去式。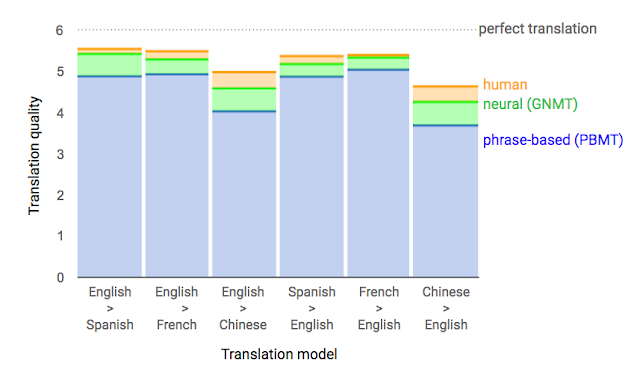
圖片來源:Google AI Blog
最後補充一下,翻譯的過程可分為前期的語言分析(包含了語法分析、型態分析和語意關聯性分析等)與後期產生文句兩階段,因此明天我們將會花一些心思探討文本生成( text generation ),它也是自然語言處理中的主要任務之一。今天的文章就寫到這兒,明天繼續!