Google 在2016年公開宣布翻譯系統的全面改革,一改沿用多年的 Phrase-Based Statistical Machine Translation ,轉而採用了當時最新穎技術的 sequence-to-sequence model (簡寫為 Seq2Seq)來提升翻譯品質。今天就讓我們深入來探討這個模型背後的架構!
Google Translate採用 Seq2Seq 模型之後大幅提升翻譯品質:
圖片來源:Google AI Blog
Seq2seq是一類將序列轉化為序列技術的統稱,最初即是由 Google Translate 研究團隊所開發( 首次公布於 2014年的論文 Sequence to Sequence Learning with Neural Networks ),並最終在2016年之後 GNMT 系統全面取代了既有的統計翻譯方法。目前 seq2seq 除了用來翻譯之外,還被使用來自動整理文件摘要、建立聊天機器人等任務。
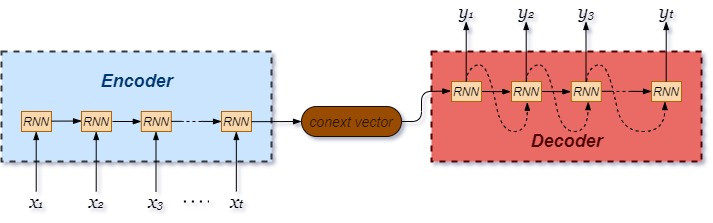
Seq2seq 的基本架構由一個編碼器( encoder )和一個解碼器( decoder )所組成,因此又被稱為 encoder-decoder network 。 當某一串序列(字符排列、句子或其他時間序列)輸入encoder 後會被轉為 context vector (也被稱為 sentence embedding ),其將當下的輸入字詞以及上下文保留起來,並傳入 decoder ,最後得到另一串序列。 Encoder 本身是一個由諸多遞迴小單元(或稱記憶細胞)所串聯而成,可以是 RNN 、 LSTM 或是 GRU 等具有循環性值的神經網絡。 decoder 的組成與 encoder 極為相近,差別在於當下輸出的 會當作下一個時刻 t+1 的輸入。
以RNN作為循環小單元的seq2seq架構:
在上一篇關於文本生成的介紹中我們提到字符級的生成器,其輸入序列可以是字符序列(例如{'A', 'B', 'C', '<EOS>'})也可以為單詞序列(例如{"I", "would", "like", "to", "say", "<EOS>"}),而輸出則是字符序列;單詞級的生成任務則是預測單詞序列。而以機器翻譯而言,輸入序列則是 word embedding 向量序列, 輸出序列亦然。
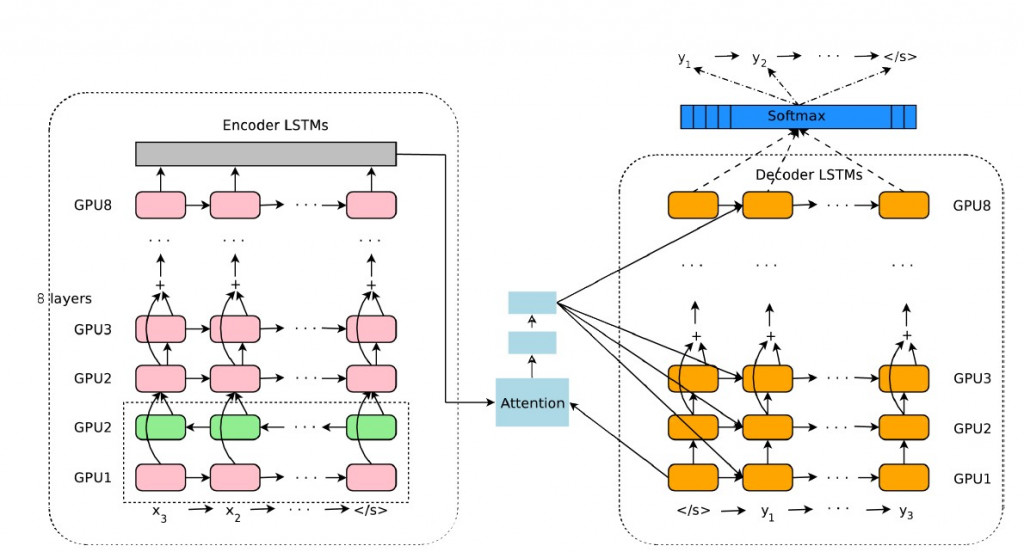
Google NMT的encoder-decoder神經網絡,以LSTM作為編碼器及解碼器的設計:
今天先介紹 seq2seq 模型的架構,明天我們會從最簡單的 RNN 架構的編碼器講起,再提到 LSTM 架構,藉此補足先前未細談的模型數學式,並且以深度學習框架 Tensorflow 撰寫 encoder LSTM 及 decoder LSTM 的Python 程式碼。今天是假期過後的第一天,各位也和我一樣經歷了 Monday blue 嗎?廢話不多說,我們明天見!