TensorFlow、PyTorch 是目前佔有率最高的深度學習框架,初學者常會問『應該選擇PyTorch或 TensorFlow套件』,依個人看法,PyTorch、TensorFlow好比倚天劍與屠龍刀,各有擅場,兩個套件的發展重點有所不同,例如在偵錯方面,PyTorch比較容易,但TensorFlow/Keras建模、訓練、預測都只要一行程式,另外,物件偵測主流演算法YOLO,第四版以TensorFlow開發,第五版則以PyTorch開發,若我們只懂TensorFlow,那就無法使用最新版了。
其實PyTorch與TensorFlow基本設計概念是相通的,只要採用相同的approach,就可以同時學會兩個套件,在後續的介紹及範例程式我們會印證這個想法。
PyTorch 認為兩個主要對手,『TensorFlow 1.x版把簡單的事情複雜化』,『Keras把複雜的事情太過簡化』,因而促使TensorFlow 2.x版依據Keras規格重新開發並納入TensorFlow中,現在Keras已變成TensorFlow最重要的模組。
而PyTorch特色如下:
另外,文件說明還是以TensorFlow/Keras較為詳盡,且較有系統性,PyTorch方面,筆者常須依靠谷大哥搜尋,這也是筆者撰寫PyTorch入門書籍的原因。
雖然存在以上差異,PyTorch與TensorFlow基本設計概念是相通的,採用相同的approach,可以同時學會兩個套件,以下我們以一些簡單範例印證這個想法。
梯度下降法是神經網路主要求解的方法,計算過程會使用張量(Tensor)運算,另外,在反向傳導的過程中,則要進行偏微分,計算梯度,如下圖: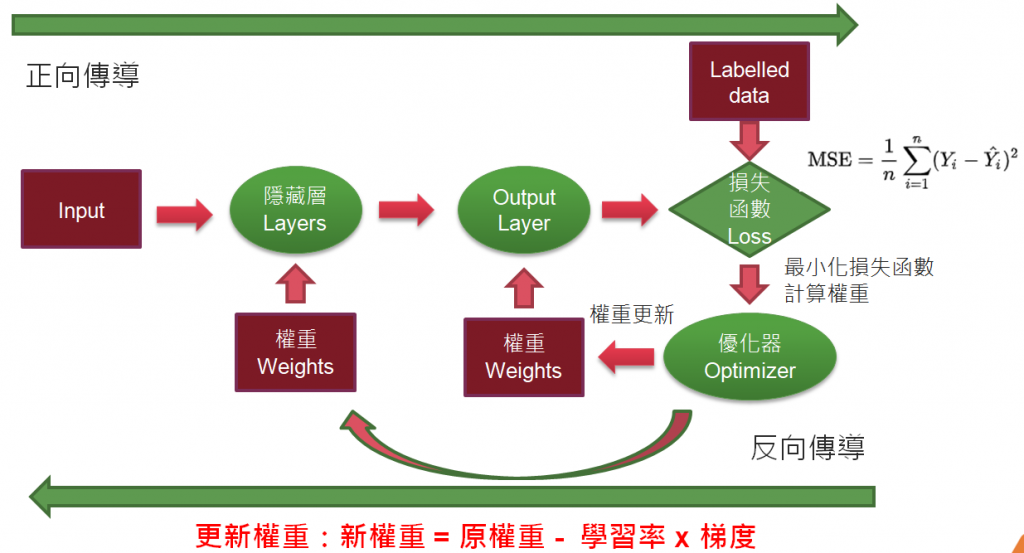
圖一. 神經網路求解過程
基於上述求解過程的需求,大多數的深度學習套件至少會具備下列功能:
因此,學習的路徑可以從簡單的張量運算開始,再逐漸熟悉高階的神經層函數,以奠定扎實的基礎。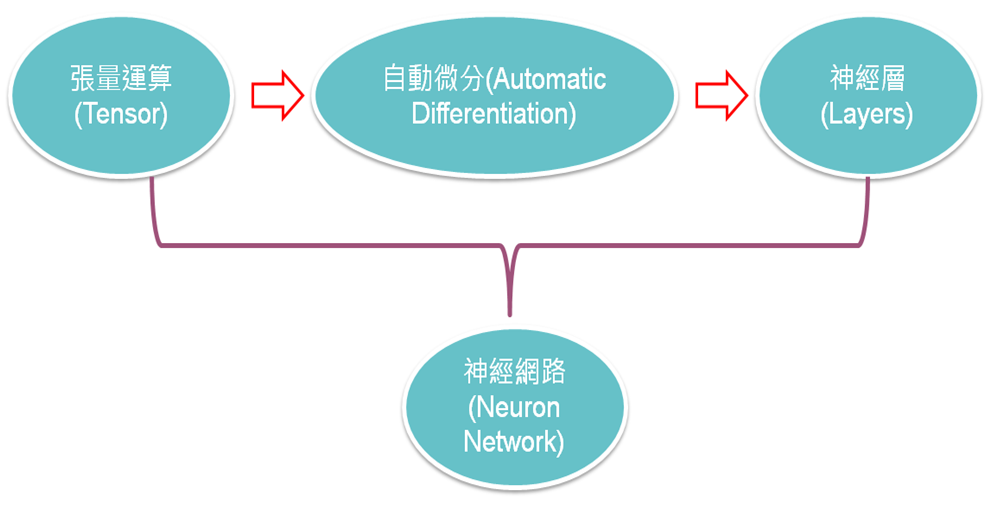
圖二. 神經網路學習路徑
神經網路通常會有很多神經層,每一層又有很多神經元,如果加上 Activation Function,要以純數學求解相當困難,因此通常會使用梯度下降法,逐步逼近最佳解的方式,求得近似解。相關說明可詳閱『Day N+1:進一步理解『梯度下降』(Gradient Descent)』、『Day 02:梯度下降與自動微分』,這裡只說明TensorFlow/PyTorch的實作。
以 為例,求解最小值。
# 載入套件
import numpy as np
import matplotlib.pyplot as plt
# 損失函數
def func(x): return x ** 2
# 損失函數的一階導數:dy/dx=2*x
def dfunc(x): return 2 * x
# 超參數(Hyperparameters)
x_start = 5 # 起始權重
epochs = 15 # 執行週期數
lr = 0.3 # 學習率
# 梯度下降法
def GD(x_start, df, epochs, lr):
xs = np.zeros(epochs+1)
x = x_start
xs[0] = x
for i in range(epochs):
dx = df(x)
# 更新 x_new = x — learning_rate * gradient
x += - dx * lr
xs[i+1] = x
return xs
# *** Function 可以直接當參數傳遞 ***
w = GD(x_start, dfunc, epochs, lr=lr)
print (np.around(w, 2))
t = np.arange(-6.0, 6.0, 0.01)
plt.plot(t, func(t), c='b')
plt.plot(w, func(w), c='r', marker ='o', markersize=5)
# 設定中文字型
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei'] # 正黑體
plt.rcParams['axes.unicode_minus'] = False # 矯正負號
plt.title('梯度下降法', fontsize=20)
plt.xlabel('X', fontsize=20)
plt.ylabel('損失函數', fontsize=20)
plt.show()
執行結果如下: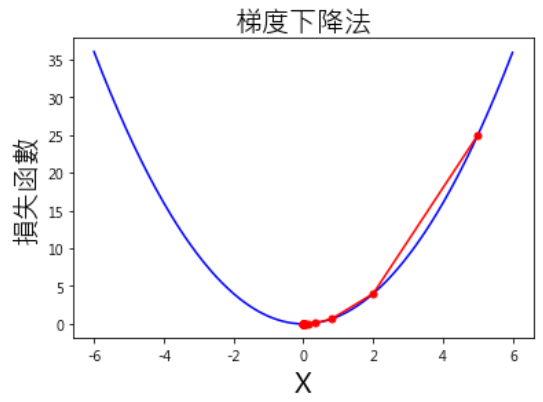
圖四. 求解過程視覺化
修改 dfunc 函數,改用 TensorFlow/PyTorch 提供的自動微分及梯度計算功能,取代 dfunc 函數的程式碼如下:
def dfunc(x_value):
x = tf.Variable(x_value, dtype=tf.float32) # 宣告 TensorFlow 變數(Variable)
with tf.GradientTape() as g: # 自動微分
y = x ** 2 # y = x^2
dy_dx = g.gradient(y, x) # 取得梯度
return dy_dx.numpy() # 轉成 NumPy array
def dfunc(x):
x = torch.tensor(float(x), requires_grad=True)
y = x ** 2 # 目標函數(損失函數)
y.backward()
return x.grad
完整程式請自『這裡』下載,程式名稱為 src/03_02_自動微分.ipynb。
TensorFlow/PyTorch 基本設計概念是一致的:
下一篇我們繼續比較神經網路及神經層的差異。
以下為工商廣告:)。
PyTorch:
開發者傳授 PyTorch 秘笈
TensorFlow:
深度學習 -- 最佳入門邁向 AI 專題實戰。
 I code so I am
I code so I am
