在我們將資料放入機器學習的演算法之前,如何利用程式幫我們準備好資料是重要的,常常聽到 "Garbage in, garbage out",因為機器學習的演算法假設資料有經過適當的處理才進行後續的分析與建模,因此將什麼樣的資料當成input就會決定演算法有什麼樣的output,而這些資料就可以藉由程式來幫助我們對資料做適當的處理以及找出資料的問題,今天將介紹如何以Python匯入資料與摘要統計,並且利用表格或圖表來呈現。語法與概念雖然簡單,但數據分析處理的資料往往都是不完善的,利用這些動作在進行資料分析前能幫助我們更了解資料的特性或發現資料有問題之處,找到更適合的方法來建構資料的模型。
pd.read_csv()匯入csv檔(以鳶尾花資料集為例)import pandas as pd
urlprefix = 'https://vincentarelbundock.github.io/Rdatasets/csv/'
dataname = 'datasets/iris.csv'
iris = pd.read_csv(urlprefix + dataname)
.info()查看變數的資料型態、資料筆數與欄位數,也觀察是否有遺失值(missing value)iris.info()
.head()或後幾筆資料.tail()(預設為六筆),其中參數可以控制想查看的筆數iris.head()
iris.tail()
.drop()移除不需要的欄位iris.drop("Unnamed: 0", 1)
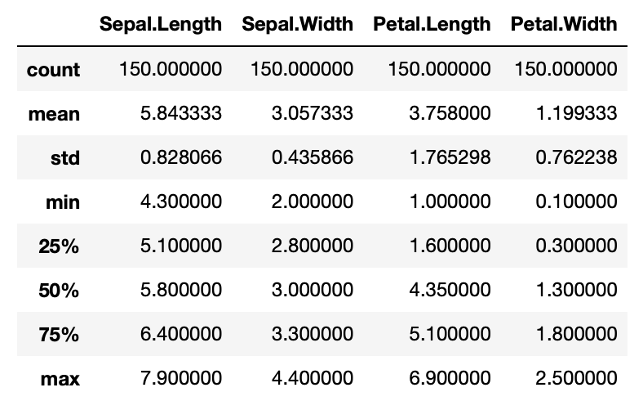
.describe()
iris.describe()
也可以利用以下的程式分別計算需要的統計量
iris.mean() #平均數
iris.quantile(q = [0.25, 0.5, 0.75]) #百分位數
iris.var() #變異數
iris.std() #標準差
.value.counts(),如iris資料集中的變數Species,計算每個類別個數iris["Sepcies"].value_counts()

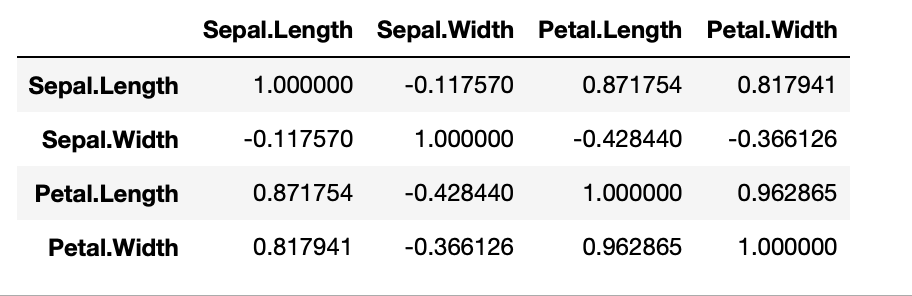
corr(),在配飾模型時變數之間的相關性也會影響到模型的表現。iris.corr()


 iThome鐵人賽
iThome鐵人賽