statsmodels 、 scikit-learn 統計分析套件介紹包含有許多經典統計模型,但不包含 Bayesian 方法和機器學習模型。
內含有的常用模型包括:
- 線性模型(linear regression)、 廣義線性模型(glm)、 穩健線性模型(robust)
- 線性混和效應模型(linear mixed effect model)
- 變異數分析 ANOVA
- 時間序列模型
- 廣義動差估計(generalized method of moment)
這是我們再進行機器學習建模時常常用到的好用套件!
除了建立監督、非監督式和強化學習的機器學習模型外,它還能協助進行「模型選擇評估」、「資料仔入轉換」和「模型的保存」。
模型訓練上還提供交叉驗證( Cross-validation )優化挑整係數等等功能的函式,可以幫助避免訓練出的模型過度擬合( overfitting )。
套件可應用領域包含「分類」、「分群」和「預測」等等。
常用模型包括:
| 模型 | Import code |
|---|---|
| Linear Regression | from sklearn.linear_model import LinearRegression |
| Ridge Regression | from sklearn.linear_model import Ridge, |
from sklearn.kernel_ridge import KernelRidge, |
|
from sklearn.linear_model import BayesianRidge |
|
| Elastic-Net Regression | from sklearn.linear_model import ElasticNet |
| SVM ( Support Vector Machine ) | from sklearn.svm import SVR |
| Gradient Boosting | from sklearn.ensemble import GradientBoostingRegressor |
| Stochastic Gradient Descent Regression | from sklearn.ensemble import SGDRegressor |
| XGBoost | from xgboost.sklearn import XGBRegressor |
| CatBoost | from catboost import CatBoostRegressor |
[注意]
⇒ Python上函式庫裡套件大部分都沒辦法接受資料中有遺失值,所以應用時記得檢查是否有遺失值!
# 確認沒有 NaN 或遺失值, 如果有記得進行填補
df.isnull().sum()## 確認沒有 NaN 或遺失值
##遺失值填補
df.fillna(method ='ffill', inplace = True) #舉例: 遺失值填補方法為向前填充(遺失值填充和前一個相同的值)
df.dropna(inplace = True)# 舉例: 直接刪除有遺失值(Nan)的資料row
那這邊直接開始補充線性迴歸模型的 Python code範例:
接下來範例的資料和昨天一樣,以 California Housing price 資料作為示範。
from sklearn.datasets import fetch_california_housing
columns_drop = ["Longitude", "Latitude"]# 刪除經度、緯度.欄位
housing_df = fetch_california_housing(as_frame=True).frame
housing_y = fetch_california_housing(as_frame=True).target
housing_x=fetch_california_housing(as_frame=True).data
columns_drop = ["Longitude", "Latitude"]# 刪除經度、緯度.欄位
housing_df = housing_df.drop(columns=columns_drop)
housing_x = housing_x.drop(columns=columns_drop)
# 觀察資料
housing_x.head()
housing_x.describe()
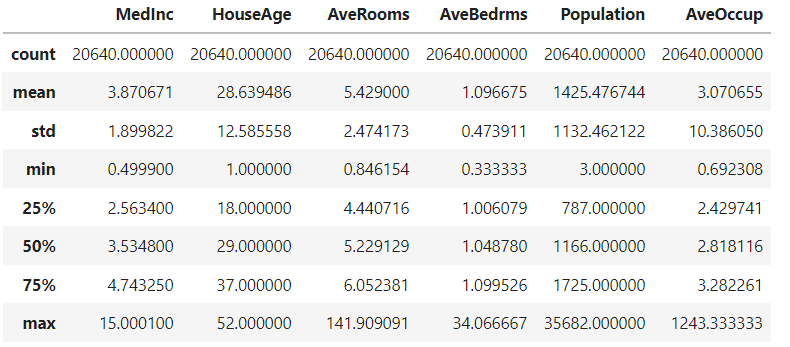
statsmodels )建立模型:
sm.OLS(Y,X):最小平方法線性迴歸import statsmodels.api as sm
X = housing_x
Y = housing_y
model = sm.OLS(Y,X)
result=model.fit()
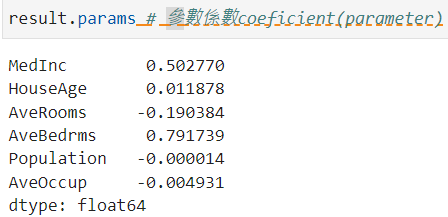
模型參數估計(係數) coeficient( parameter ):
result.params # 參數係數coeficient(parameter)
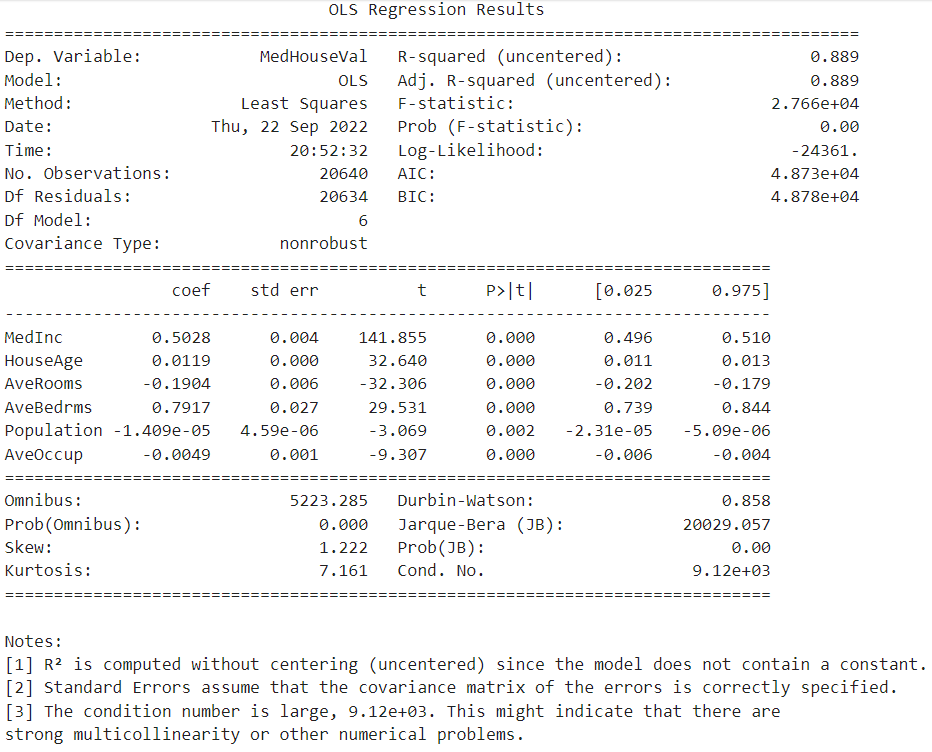
報表結果:
print(result.summary()) # 相關的報表結果
用.predict( )來預測:
test = housing_x[:5] # 測試投入前五筆資料的 X ,用來預測 Y
result.predict(test) # 放入 X 值進行預測,輸出預測的y值
smf.ols('y ~ x1 + x2 + x3', data = data)import statsmodels.formula.api as smf
X = housing_x
Y = housing_y
data=housing_df
model = smf.ols('MedHouseVal ~ MedInc+ AveRooms + AveBedrms', data=data)
result= model.fit()
result.params # 參數係數coeficient(parameter)
print(result.summary()) # 相關的報表結果
## .predict( ),輸出預測的y值
# 放x 或是df的資料形式來預測都可以,因為smf.ols('y ~ x', data = data)形式是從df裡找x的col.
result.predict(housing_x[:5]) # 放x的資料形式
result.predict(housing_df[:5]) # df的資料形式
scikit-learn )建立模型:
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(housing_x, housing_y )
模型參數估計(係數)結果 coeficient( parameter ):
intercept=regr.intercept_
coeficient=regr.coef_
print('intercept 截距項 : ',intercept)
print('coeficient 係數 : ',coeficient)
# 輸出好看一點:
col_names=housing_x.columns
coefdf=pd.DataFrame(coeficient,col_names).T
coefdf.insert(0, 'Intercept', intercept)
print(coefdf.to_string(index=False))

sklearn裡還提供了變數篩選( RFE )的函式:
RFE 的原理和 stepwise 選取變數的方式很類似,能夠支援很多種的機器學習模型下的變數選擇。
示範以線性迴歸模型的變數選擇為例,並假設我今天想選出3個對預測(y)最有貢獻度的解釋變數(x)。
from sklearn.feature_selection import RFE
X = housing_x
Y = housing_y
# fit model
model = LinearRegression() #線性迴歸模型
# feature extraction
#RFE(estimator=DecisionTreeClassifier(), n_features_to_select=3)
rfe = RFE(model, 3) # 填寫想篩選的變數數目,這裡示範 3
fit = rfe.fit(X, Y)
print("Num Features: %d" % fit.n_features_)
print("Selected Features: %s" % fit.support_)
print("Selected Features: %s" % list(col_names[fit.support_]))
print("Feature Ranking: %s" % fit.ranking_)
變數篩選輸出結果:
Num Features: 3
Selected Features: [ True False True True False False]
Selected Features: ['MedInc', 'AveRooms', 'AveBedrms']
Feature Ranking: [1 2 1 1 4 3]
我們這裡使用進行機器學習的建模時常常使用到 SciKit-learn Package。
使用資料接續上同一個 California Housing price data。
Python code 參考網站。
import pandas
from numpy import absolute
from numpy import mean
from numpy import std
from sklearn import model_selection # CV
X = housing_x
Y = housing_y
# Lasso Regression
from sklearn.linear_model import Lasso
kfold = model_selection.KFold(n_splits=5) #用 k-fold=5折方法
model = Lasso() # defualt alpha=1.0
使用 k-fold cross-validation 計算average MAE(mean absolute error),可以用來評斷不同模型之間的好壞。
scoring = 'neg_mean_squared_error'
scores_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
scores = absolute(scores_results)
# average MAE across the 5-fold cross-validation.
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))
補充網站(LASSO參數挑選)
補充網站(sklearn.linear_model.LassoCV)
# Ridge Regression
from sklearn.linear_model import Ridge
kfold = model_selection.KFold(n_splits=5)
model = Ridge()
scoring = 'neg_mean_squared_error'
scores_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
scores = absolute(scores_results)
# average MAE across the 5-fold cross-validation.
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))
#ElasticNet Regression
from sklearn.linear_model import ElasticNet
kfold = model_selection.KFold(n_splits=5)
model = ElasticNet()
scoring = 'neg_mean_squared_error'
scores_results = model_selection.cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
scores = absolute(scores_results)
# average MAE across the 5-fold cross-validation.
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))
scikit-learn course
https://inria.github.io/scikit-learn-mooc/python_scripts/datasets_california_housing.html
https://machinelearningmastery.com/spot-check-regression-machine-learning-algorithms-python-scikit-learn/
Sklearn Regression Models, Simplilearn.
https://www.simplilearn.com/tutorials/scikit-learn-tutorial/sklearn-regression-models#:~:text=Scikit-learn%20%28Sklearn%29%20is%20the%20most%20robust%20machine%20learning,learning%2C%20like%20classification%2C%20regression%2C%20clustering%2C%20and%20dimensionality%20reduction.
Spot-Check Regression Machine Learning Algorithms in Python with scikit-learn
https://machinelearningmastery.com/spot-check-regression-machine-learning-algorithms-python-scikit-learn/
Recursive Feature Elimination (RFE) for Feature Selection in Python
https://machinelearningmastery.com/rfe-feature-selection-in-python/

