終於到了實作天,今天將會教導大家如何評估模型,準備好我們就開始囉~
這次我們將用回鳶尾花數據集來呈現,匯入File後,先用個簡單的分類方法訓練模型,那就是在上上篇為大家科普的邏輯迴歸(Logistic Regression)啦~
而為了避免過度擬合(overfitting),我們會用訓練集建立模型,接著用測試集測試此模型的表現。
我希望以多次重複這個動作來平均準確率,所以將會用到Test & Score這個組件來看其成效。
(下一張圖會有更詳盡地解釋~)
補充說明 : overfitting
當模型在樣本數據上訓練的時間過長,抑或是過於複雜,它會開始學習數據集中的“noise”或不相關的訊息。若模型記住了這個噪聲,並與訓練集擬合得太緊密時,模型則會變得“overfitted”,且無法很好地應用到新數據,而它將無法執行其預期的分類或預測任務。
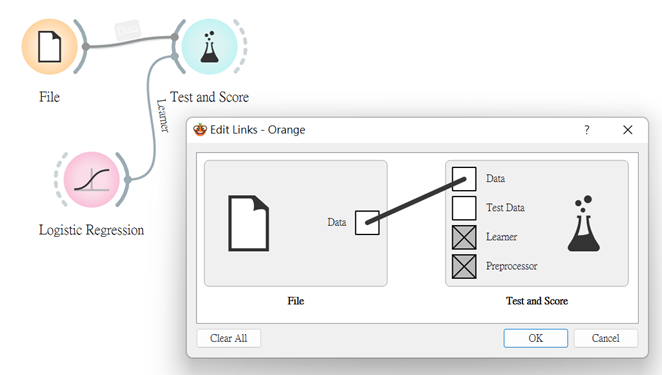
打開Test and Score左上角有個Cross validation(交叉驗證)的選項,我們就是用它來做到多次重複動作的行為,從下方可看到我是用十折交叉驗證,這十折的分配是用九份數據建模一份數據預測,而每次使用不同的子集來進行交叉驗證,如此地重複這個動作九次以上。
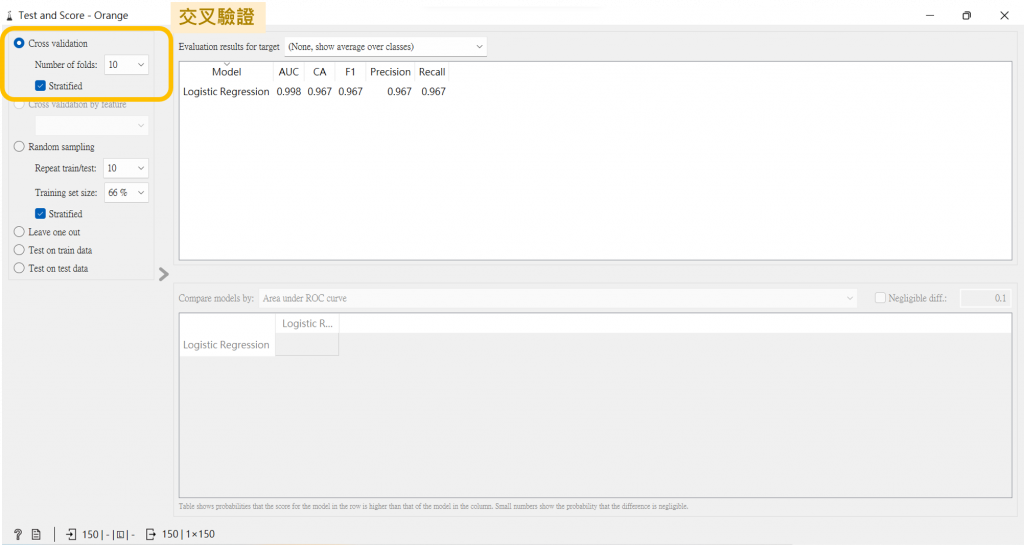
驗證結果,有以下幾項:

我們可以連接混淆矩陣,看到紅色圈起處,就是被誤判的數據數。
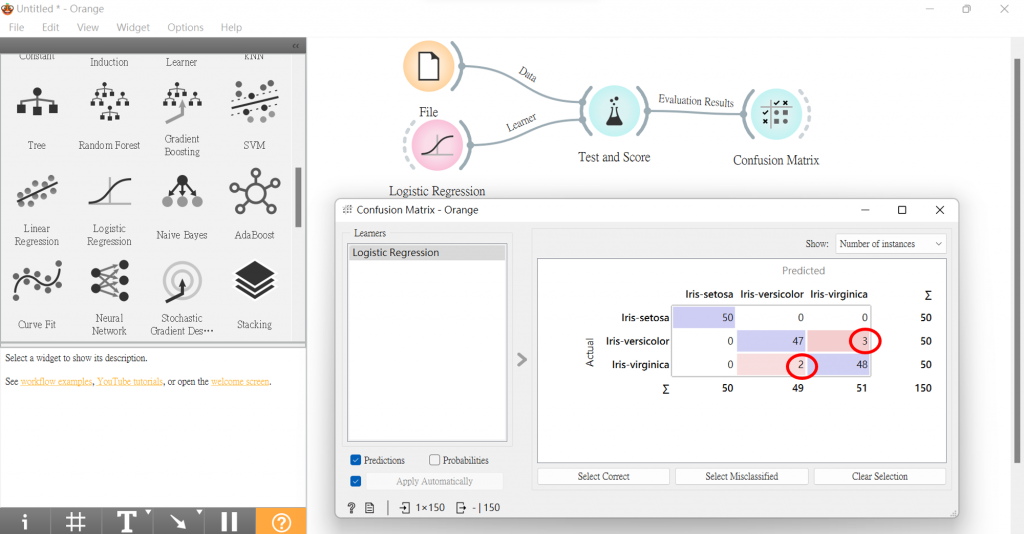
剛剛誤判的數據,我們將連接Data Table查看,還用Scatter Plot視覺化檢視。

當然,我們也可以接看看不同模型的效果,以下範例我用了Random Forest和Tree來試,大家有興趣的話,也可以嘗試自己動手操作看看後續步驟拉~

今天補充的知識,與實作好像都比之前多,看與做到這邊的你們辛苦啦,明天繼續加油!!!
參考資料:
F1分數
Orange
Overfitting
精密度與準確度
如何辨別機器學習模型的好壞?秒懂Confusion Matrix


 iThome鐵人賽
iThome鐵人賽