倒數兩天啦~今天要讓大家自己找檔案試試前幾集以故事為主題的教學,那就直接來囉!
這次大家可以選幾個類別的故事或文章,接著將它們用txt或tab檔存於檔案中,可以先將它們分好類別放置於一個個資料夾中,最後再將這些資料夾整合成一個資料夾!
除了選檔外,其他動作相信有看前幾集的你,一定很熟練了,若不太清楚的話,可至第25篇章及第26篇章,有詳細說明!
你也可以外接一個「Corpus Viewer」,檢視看看是否讀取成功。
這步之前有提過,但真的很重要所以再次跟大家說說此流程。
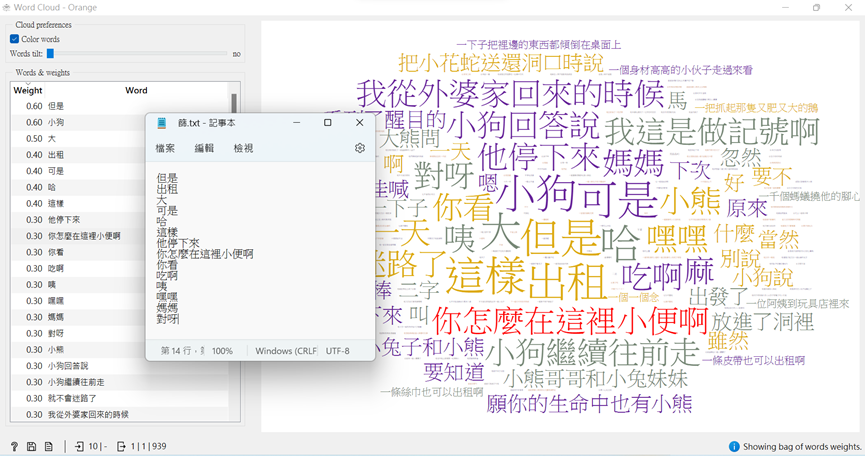
連接「Word Cloud」,將會看看許多段文字顯現,左側是依照出現的頻率去排序,右側大小也一樣是按照比重。
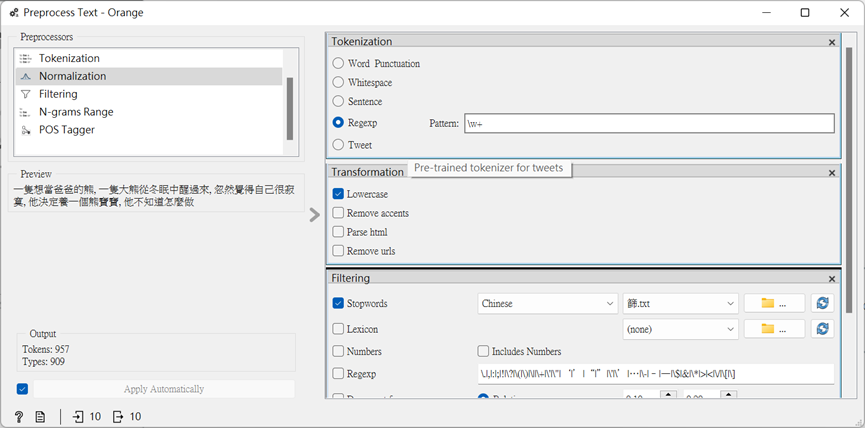
這邊大家可以看看裡面,有沒有不重要的文字訊息佔得比例很重,若有那可以將他們分段打在記事本上,接著輸入至「Preprocess Text」中。(第25篇章有更詳盡的解說~)
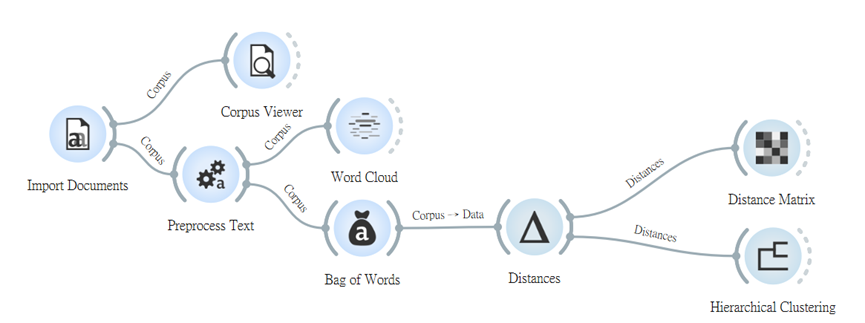
從影片中可看出我的故事被分成了三至四類,當被分成四群時,C3和C4群相當的接近,但裡面內容狗和熊的故事各佔一半,而C1與C2的分類相當正確。
以這次分類來看,可以得出一個小結論,故事或文章內容若是有許多無關主題的文字重疊,沒有預處理好,用這個方法,將會影響後續分類上的誤判。
這個步驟是供大家使用模型看看自己的數據在那上面的效果如何,若你的模型評估很高分者,可以試著連接新的文章,看看其判斷是否正確。(第27篇章有更詳盡的解說~)
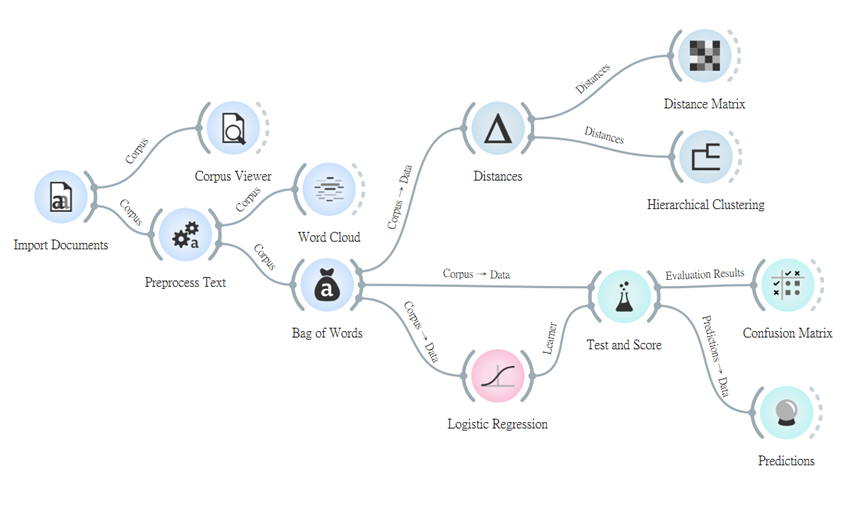

今天就到此結束囉,這次留給大家動手操作的部分比較多,希望大家可以因此而加深印象,後續自己摸索就會越玩越上手!


 iThome鐵人賽
iThome鐵人賽