於上一篇,我們懂得如何歸類故事類別,那麼今天將帶大家用機器學習模型對新故事進行分類!
我們開始執行吧~
這邊跟上一篇一樣,我們將「Corpus」、「Preprocess」、「Bag of Words」連接上來,而檔案我們一樣使用「grimm-tales-selected」(格林童話)做模型訓練。
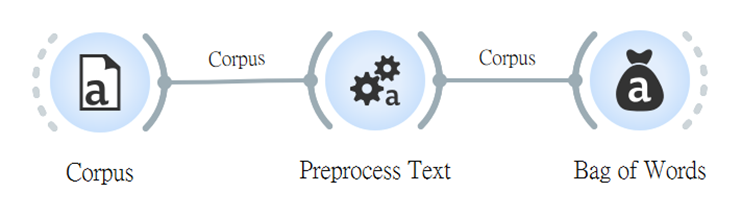
接著,連上「Logistic Regression(邏輯迴歸)」(詳細說明此模型,於第十一篇章,將數據集訓練後,暫時先放置一邊,等等預測新數據將會用到。

將「Bag of Words」接上「Test and Score」與另一個「Logistic Regression」看看分類的各項評估值(各項評估值的中文名稱以及初步解釋,於第十四篇章)。
評估值通常需要一點時間計算,跑完後,下方%數將會消失,即可檢視。
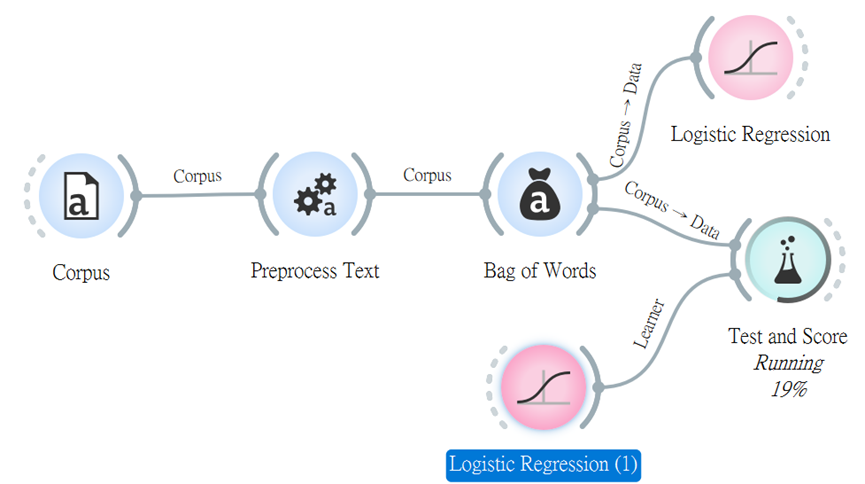
由AUC來看評估值,有一定的可性度。
補充說明 AUC數值意義
| AUC值 | 準確度 |
|---|---|
| 0.9以上 | 準確度較高 |
| 0.7~0.9 | 準確度中等 |
| 0.5~0.7 | 準確度較低 |
| 0.5以下 | 準確度不良 |
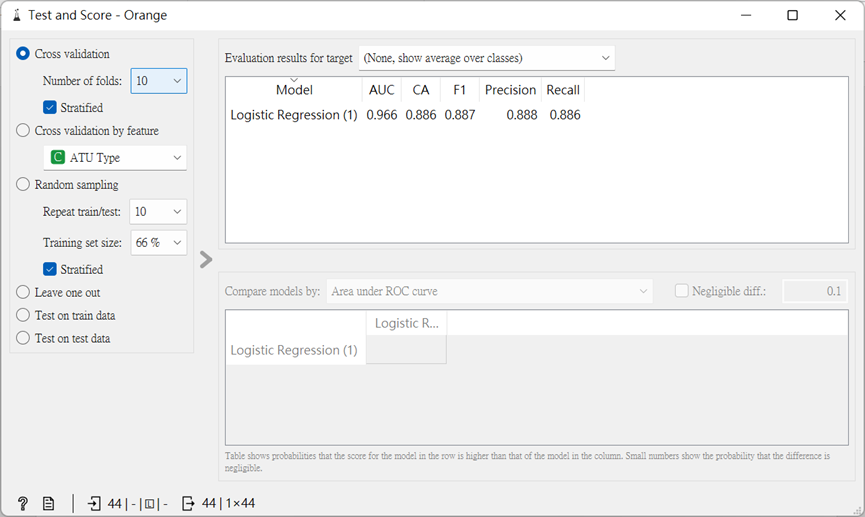
選取另一個檔案「andersen.tab」,進行預測,看看當中的三個故事會被歸類於哪一類。
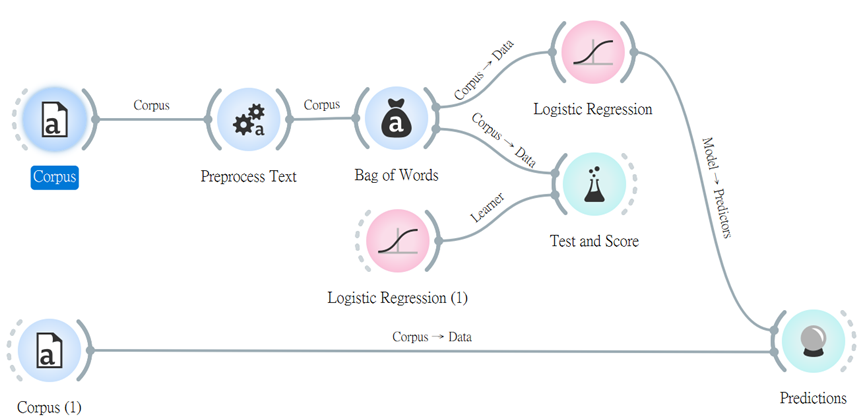
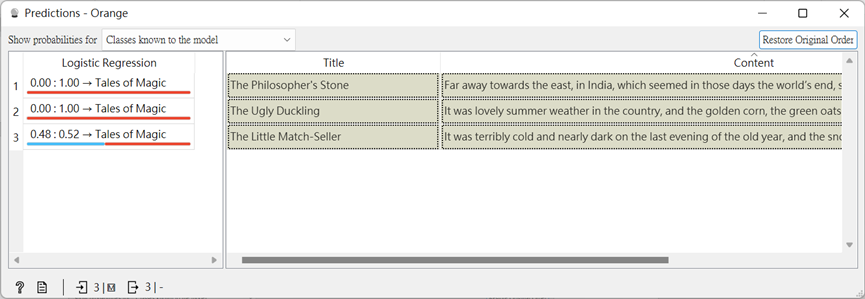
從下圖看來,預測出來成果有一項不如預期,但這跟我們調整Logistic Regression其中的C值,還有前面文字預處理的部分也很有關聯,若有興趣者,可自行調整玩玩看,將會有不同效果喔~
今天就先到這裡囉,倒數三天~
參考資料:
Orange


 iThome鐵人賽
iThome鐵人賽