經過上一篇文字預處理後,我們會得到一行行的文本內容,但這樣對於機器學習來說是無法好好讀取訊息的,所以要將這些單字轉換成數值,以便後續操作。
來!我們快點開始動手實作吧~
先前作法跟上一篇一樣,我們會先將文字做多餘的刪減,接著就是將單字轉數值!
而最簡單的做法就是去計算一個個單字出現的次數,這個行為在Orange中的組件為「Bag of Words(文字庫)」。

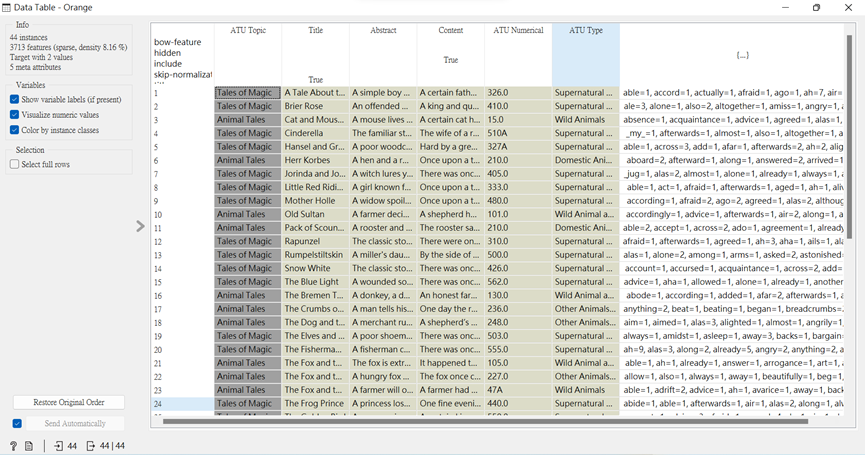
我們可以接上「Data Table」查看它轉換出來的成效,從以下圖來看,它將顯示於最後一個類別中。
得到數值後,我們將它連接「Distance」,利用餘弦定理計算距離,再用「Hierarchical Clustering」看分類這些文本後的樹狀圖。(想知道更詳盡的說明Hierarchical Clustering與Distance,可看第八篇和第九篇~)
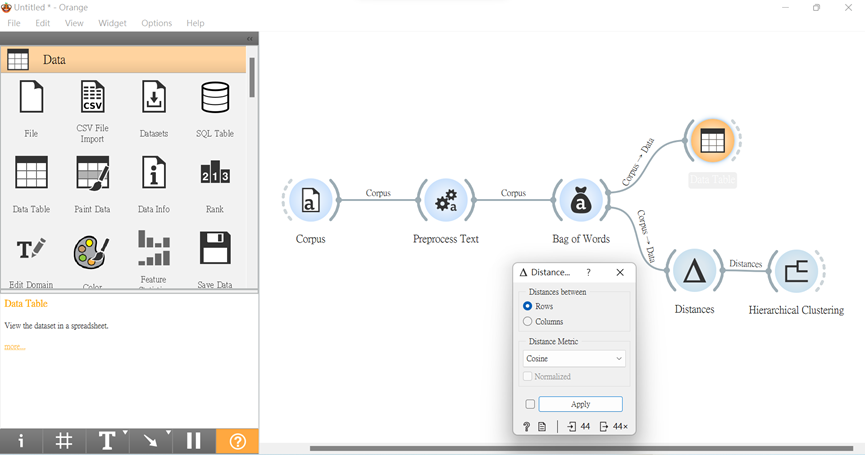
再來,因為是為了分析文本,我們將用Ward(沃德法)來算兩群聚間的距離。
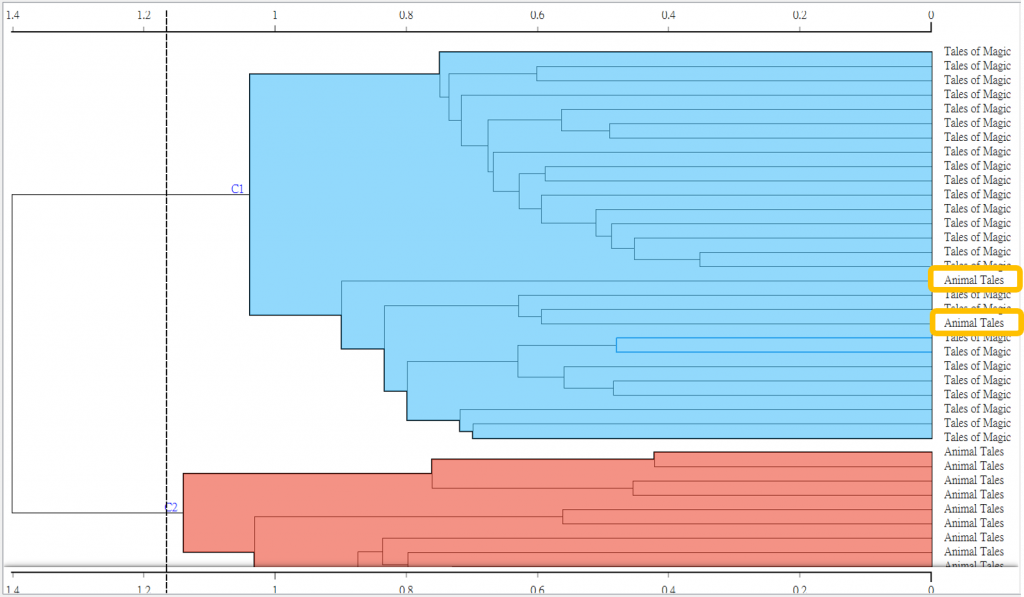
當我們在觀察時,可以拉右邊上方的線條,看看組數不同的效果,顏色一樣代表為同一群,反之亦然。由以下GIF來看,分成兩群最為合適。

那數狀圖呈現時,旁邊有標籤顯示可以看看有幾個混入到不對的群中,以下圖為例,有兩個文本被分類錯誤!
這時我們就可以連上「Corpus Viewer」,觀察文本內容。
首先,在「Hierarchical Clustering」選取誤判的區域。
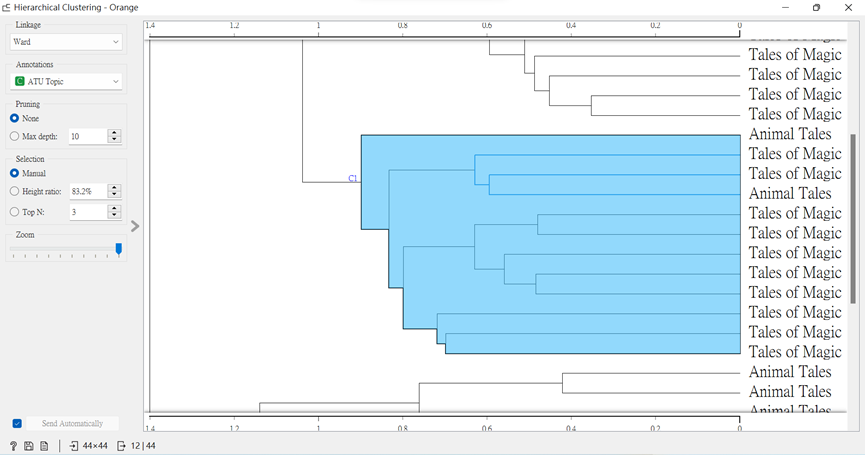
再打開「Corpus Viewer」,看看故事內容。由內文來看,看來機器是真的誤判了~

好勒~今日份至此,離完賽也剩四天了!加加油哇~
參考資料:
Orange


 iThome鐵人賽
iThome鐵人賽