這篇教學會使用 MediaPipe 的全身偵測模型 ( Holistic ) 偵測人體,抓取頭、四肢等軀幹部位,再透過 OpenCV 讀取攝影鏡頭影像進行辨識,將五官、頭手四肢軀幹標記出節點以及骨架。
因為程式使用 Jupyter 搭配 Tensorflow 進行開發,所以請先閱讀「使用 Anaconda」和「使用 MediaPipe」,安裝對應的套件,如果不要使用 Juputer,也可參考「使用 Python 虛擬環境」,建立虛擬環境進行實作。

Mediapipe Holistic 集合了人體姿勢、面部標誌和手部追蹤三種模型與相關的演算法,可以偵測身體姿勢、臉部網格、手掌動作,完整偵測則會產生 543 個偵測節點 ( 33 個姿勢節點、468 個臉部節點和每隻手 21 個手部節點 )。
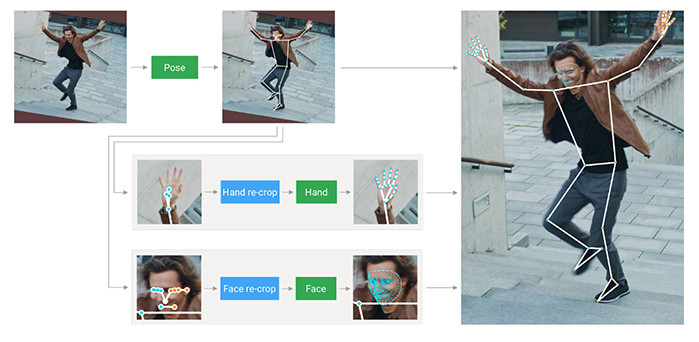
下方的程式碼延伸「讀取並播放影片」文章的範例,搭配 mediapipe 全身偵測的方法,透過攝影鏡頭獲取影像後,即時標記出身體骨架和動作。
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils # mediapipe 繪圖方法
mp_drawing_styles = mp.solutions.drawing_styles # mediapipe 繪圖樣式
mp_holistic = mp.solutions.holistic # mediapipe 全身偵測方法
cap = cv2.VideoCapture(0)
# mediapipe 啟用偵測全身
with mp_holistic.Holistic(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as holistic:
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
ret, img = cap.read()
if not ret:
print("Cannot receive frame")
break
img = cv2.resize(img,(520,300))
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將 BGR 轉換成 RGB
results = holistic.process(img2) # 開始偵測全身
# 面部偵測,繪製臉部網格
mp_drawing.draw_landmarks(
img,
results.face_landmarks,
mp_holistic.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
# 身體偵測,繪製身體骨架
mp_drawing.draw_landmarks(
img,
results.pose_landmarks,
mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles
.get_default_pose_landmarks_style())
cv2.imshow('oxxostudio', img)
if cv2.waitKey(5) == ord('q'):
break # 按下 q 鍵停止
cap.release()
cv2.destroyAllWindows()

大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我已經寫了超過 400 篇 Python 的教學,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽