雲端的虛擬主機,我們使用AWS上的GPU node與現成的Unity with mlagent的docker image來提供這次試驗。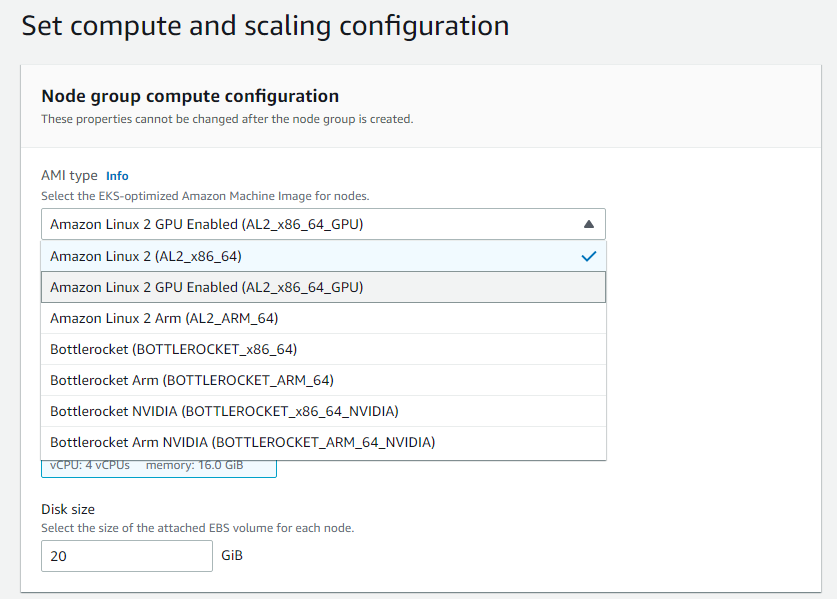
不使用GPU node若改用CPU來運算也可以,只是時間會拉比較長。
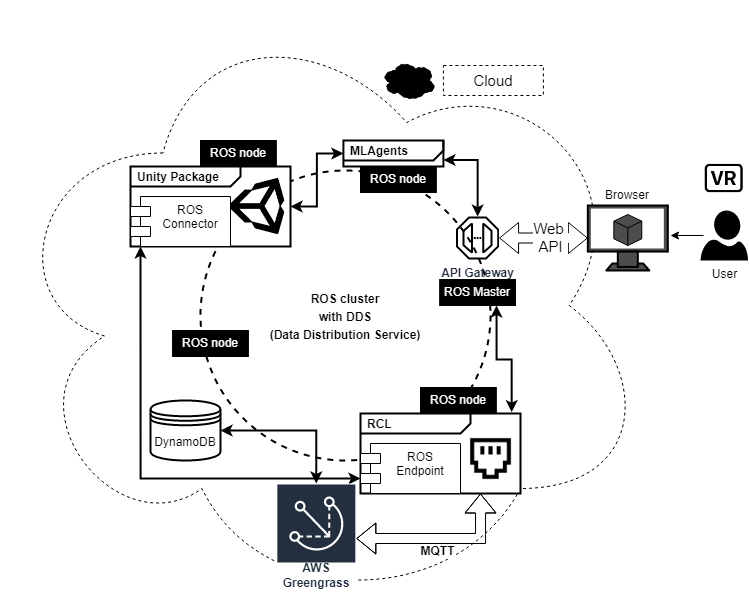
並使用之前提到的funai 3D的遊戲環境在雲端上佈建,來試驗Unity在雲端環境training model的可行性。該Unity的image本身就提供Unity ML-Agents Toolkit,來方便呼叫mlagents(based on PyTorch)所提供的ML training API,來訓練我們在Unity 3D車子環境下的model。
docker run -it \
-e DISPLAY=:0 \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
--runtime=nvidia \
--entrypoint /bin/bash \
ml-agents-visobs-gpu
因為是在Unity中做3D環境的模擬,是需要有畫面來做運算的。但ubuntu的系統上有提供所謂headless server的方式來呈現畫面,也就是提供一個虛擬的Display做渲染,這樣就不需要開啟unity的display去呈現畫面。
(以上資訊提供來自成大學生頌宇)
或是查詢有關virtual display using Xvfb,可得到更多相關資料。
以上的試驗有助於之後FRC車子在虛擬環境的模擬運算工作。後續並且將Unity執行AI後產出的raw data記錄一幀一幀記錄下來(json format stored in dynamodb),而非只有record畫面成影片檔。