延續昨天的 Object Detection Inference 物件偵測推論,今天將嘗試在 Colab 上訓練自己的客製化 SSD-MobileNet-V1 ,實作一個可以偵測八種類別水果的模型! Let’s GO!

客製化物件偵測模型 (source: NVIDIA)
訓練物件偵測模型在 Colab 上運行跟在 Jetson Nano 的方法一樣簡單,筆者同樣也將作流程寫成 Colab 範例方便開發者直接修改。根據 NVIDIA 給的統計,相同的物件偵測資料集,在 Jetson Nano 訓練一次(epochs) 需花費 17 分鐘 55 秒,而使用 Xavier NX 每次訓練也要 5分50秒,算是相當費時。筆者實測在 colab 每次訓練也需要 5分多鐘(訓練資料為 5145 張時),但也比在 Jetson Nano 快上了幾倍。
從 github 下載 Jetson-Inference 專案。
# colab 範例
!git clone --recursive https://github.com/dusty-nv/jetson-inference
下載 SSD-MobileNet-V1 預訓練模型,與安裝必要的 python 套件。
# colab 範例
%cd jetson-inference/python/training/detection/ssd
!wget https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O models/mobilenet-v1-ssd-mp-0_675.pth
!pip3 install -v -r requirements.txt
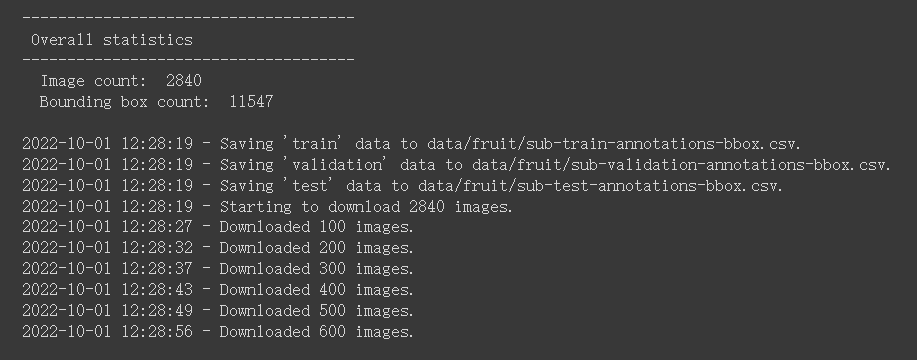
水果的影像資料可以從 Open Images 取得, Open Images 是由 google 維護的巨量影像資料庫,包含超過九百萬張影像,其中已有標註可作為物件偵測模型訓練的物件類別有 600 種,總共一千六百萬個 Bounding Box 散布在一百九十萬張照片中。可以使用 open_images_downloader.py 工具來協助從 Open Image 下載所需要的資料,
由於目標是要作偵測各類水果的模型,因此可以使用 --class-names 參數指定要下載的物件類別。由於資料量較大,筆者想縮短一點訓練時間,故使用 --max-images 參數來限定影像資料的上限。當然時間許可的話,盡量還是下載全部資料來作訓練,可以得到適應性更佳的模型。
# Colab 範例
!python3 open_images_downloader.py --max-images=3000 --class-names "Apple,Orange,Banana,Strawberry,Grape,Pear,Pineapple,Watermelon" --data=data/fruit
下載前顯示搜索到的資料為 2840 張(若全部下載則會有 6360 張),其中訓練資料為 1625 張。
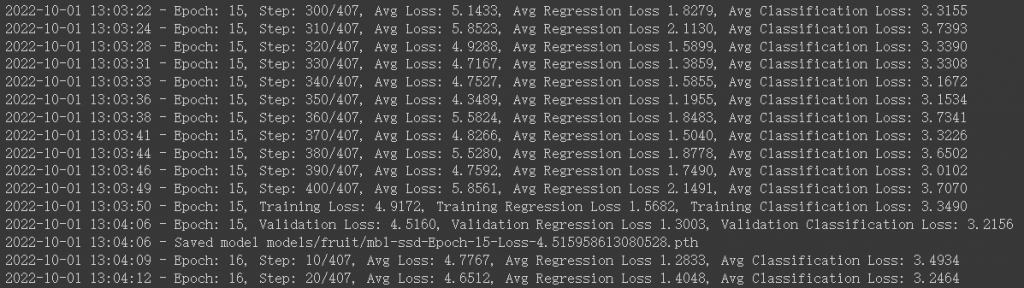
執行 train_ssd.py 程式進行訓練,參數說明:
--resume=models/fruit/mb1-ssd-Epoch-29-Loss-4.37993206844821.pth
# colab範例
!python3 train_ssd.py --data=data/fruit --model-dir=models/fruit --batch-size=4 --epochs=30
執行後便開始訓練,以筆者測試 1625 張訓練資料,每次訓練約兩分鐘。
將剛訓練好的 pytorch 模型轉為 ONNX 格式,程式會自動搜索指定的路徑資料夾中, LOSS 最小的模型進行轉換,而並非是最後一次產出的模型。
# Colab 範例
python3 onnx_export.py --model-dir=models/fruit
執行完成將得到 ssd-mobilenet.onnx 檔案,將其與 labels.txt 一併下載到 Jetson Nano 並放置於 jetson-inference/python/training/detection/ssd/models/ 路徑下,方便下一步做推論使用。
如果不想花時間載 colab 訓練模型,也可以直接拿 NVIDIA 跑過 100 次訓練的預訓練模型來做測試。
進入 docker 容器做推論
cd jetson-inference/
docker/run.sh
執行物件偵測推論程式,批量推論水果照片。
cd python/training/detection/ssd/
detectnet.py --model=models/ssd-mobilenet.onnx --labels=models/labels.txt \
--input-blob=input_0 --output-cvg=scores --output-bbox=boxes \
"/jetson-inference/data/images/fruit_*.jpg" /jetson-inference/data/images/test/fruit_%i.jpg
從推論的影像輸出結果可以看出效果並不算令人滿意,主因也是因為資料量僅有原始二分之一,並且訓練次數也僅三十次。若再將其提高皆可有效提高辨識度。
另外也可以選擇使用 Webcam 來做即時的推論喔!
detectnet.py --model=models/fruit/ssd-mobilenet.onnx --labels=models/fruit/labels.txt \
--input-blob=input_0 --output-cvg=scores --output-bbox=boxes \
/dev/video0
跑完今天的範例程式,應該覺得訓練物件偵測模型並非太困難的事,多的是高手已經寫好了強大的工具,讓開發者們可以輕鬆的上手與使用。建議有興趣的夥伴可以從 Open Images 下載有興趣的資料做模型訓練,只要資料集夠完整,相信要客製化各種模型都絕非難事喔!


