昨天介紹的模型都是用來做圖像分類(Image Classification),那自動駕駛車又用到了其他哪些圖像技術呢?先來感受一下坐在特斯拉的車子裏面會是什麼情況。

ーー影片出處:Tesla autopilot
影片開頭其實有一段開場白:這個人只是為了法律理由而坐在駕駛座,他啥事也沒做。
關於自駕車等級和法律規範會放在 AI×社會 篇章說明。
今天要介紹的就是動畫中使用的圖像技術:物體偵測。
不只做圖像上物體的分類還將物體的位置給標示出來。
有兩種做法:
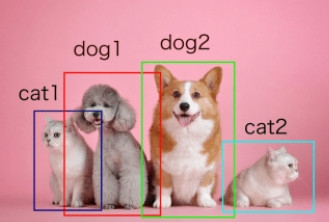
會使用一個矩形的邊界框(Bounding box)把物體的所在位置框起來,然後再用方框內的圖片做圖像分類。
代表性模型有:
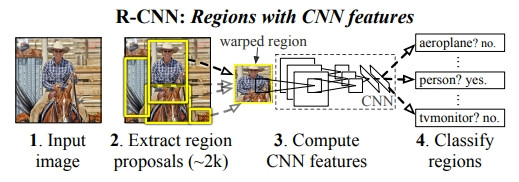
R-CNN 預測時間約 40-50秒,物體檢測評價指標(mAP,Mean average precision)在測試集(Pascal VOC 2012)上只有 53.3%。
Fast R-CNN 預測時間約 2 秒, mAP 有 65.7%。 而VGG 16 是 2015年 ILSVRC 亞軍的模型名稱。
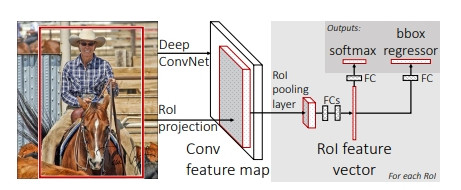
Faster R-CNN 預測時間約 0.2 秒, mAP 有 67%(使用3個資料集訓練則可以到75.9%)。
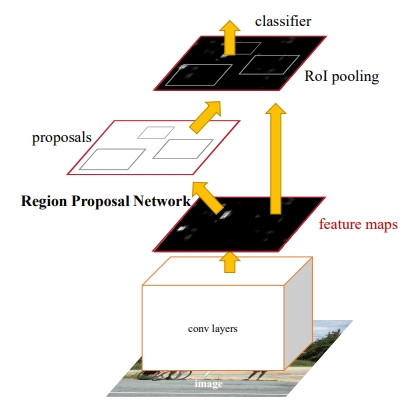
自駕車需要即時辨識出物體位置避免碰撞,所以需要立即的辨識速度,因此產生犧牲了一些準確度但是速度快很多的方法。也就是同時做位置和類別的辨識。
代表性模型有:
YOLO(You Only Look Once)
如果字面上你只看一眼這樣的快速,算是非常熱門的模型,目前已經發展到 YORO v7。
YORO v1 的構造非常的單純,下圖把 448×448 的圖片像素透過重複的 CONV-POOL 壓縮成 7×7 大小的網格。最重要的是最右邊的 7×7×30的部分,這30個數字是怎麼來的?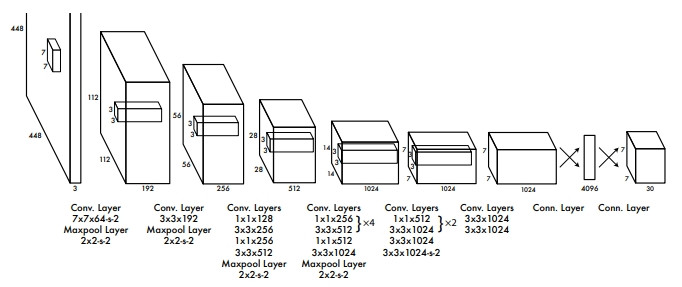
—— YORO v1 架構,出處:YORO v1 論文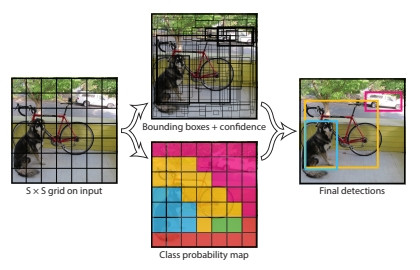
—— 實際分類的視覺化,出處:YORO v1 論文
所以輸出的30個數字就是透過每個網格同時進行多個物體位置和類別概率的預測。
YORO v1 根據條件可以比 Faster R-CNN快6倍,但是 mAP 略差於 Faster R-CNN。
除了 YORO 以外常見的還有 SSD(Single Shot Detectors)模型。
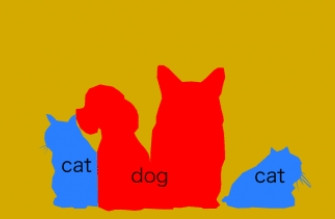
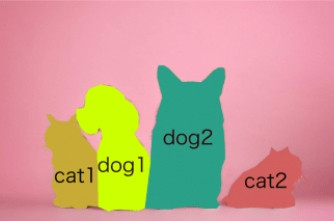
另外有一種不透過邊界框而是使用圖片最小單位的像素(Pixel)做物體標示。
比如說原圖和物體偵測長這樣:
| 原圖 | 物體偵測 |
|---|---|
 |
 |
—— 出處:インスタンスセグメンテーション

用 CNN 怎麼做語意分割呢? FCN 就是一個典型的模型。
FCN 如同字面,沒有全連接層,所有層都是 CONV-POOL 的模型,將圖像濃縮到非常小的特徵地圖做像素分類後,再將非常小的特徵地圖作放大(Upsampling),所以經由放大後圖像會比較粗糙。
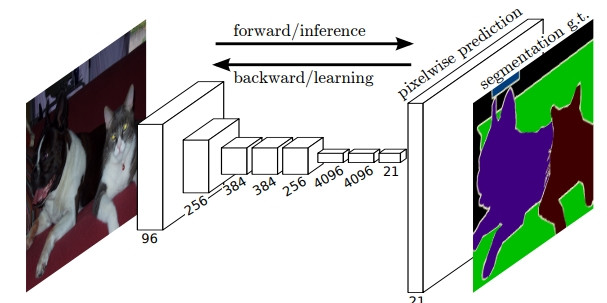
—— 出處:FCN 論文
其他圖像分割的模型還有 SegNet,UNet,PSPNet,DeepLab等。
而實例分割可以透過 Mask R-CNN 實現。基礎架構是透過 Faster R-CNN 進行物體偵測,再另外在邊界框的每個像素上預測是不是物體所在做一個實例分割。
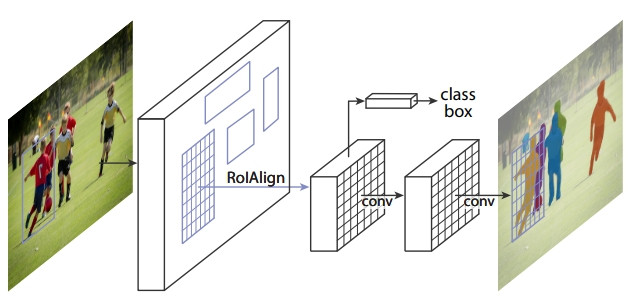
—— 出處:Mask R-CNN 論文
可以顯示人體骨架和關節的模型,活用於運動方面如棒球員的打擊姿勢等。
有一個公開的 Library:Open Pose 可以使用,主要是採用 Parts Affinity Fields 方法來推測關節位置。並透過 GPU 晶片可以即時對影像中複數的人作關節描繪。

—— 出處:Github - openpose
之前有介紹過 LIME 和 SHAP 等等用來解釋 AI 的工具,而針對 CNN 的可解釋性,2017年 Facebook 發表的 梯度權重-CAM (Grad-CAM,Gradient-weighted Class Activation Mapping), 可以將 CNN 的輸出依照權重,在圖片上用顏色強調分類的依據,這種強調手法叫 CAM(Class Activation Map)

ーー圖片出處:Visual explanations for CNNs with Grad-CAM



 iThome鐵人賽
iThome鐵人賽