集成學習(Ensemble Learning)是一種將多個模型整合起來,最後獲得比單一個模型表現更好的方法,例如在某筆資料集中可以使用KNN、線性迴歸模型(Linear Regression)、決策樹(Decision Tree)等方法來完成預測,而集成學習就是想將這些可以運用方法的結果整合以獲得比單一模型更好的結果。常見的方法例如Bagging、Boosting、AdaBoost與隨機森林(Random Forest)等,會在這幾天分別介紹基本的概念。
Bagging為bootstrap aggregating的縮寫,由字面上的意義可以得知他結合了bootstrap與模型平均的概念。在決策樹(decision tree)的內容中提到,決策樹進行預測的準確率通常不高,換句話說預測結果的標準差(variance)通常較大,當資料有些微改變時常常會獲得全然不同的結果。除了決策樹外,其他機器學習的模型也可能會遇到變異很大的情況,例如線性迴歸模型在高維度(p>n)的情況。然而,Bagging就是想處理機器學習模型有時變異很大的情況。
回顧統計學中的概念,若有一筆來自相同分佈且互相獨立(i.i.d.)的資料,變異數為
。而樣本平均數
的變異數為
,也就是說資料的樣本平均數(在同筆資料中重複抽取大小一樣的子集計算樣本平均數形成的資料)的變異數比原來的資料來得小。因此如果可以獲得很多組來自母體(populatoin)的B個訓練集,針對每個資料集建構一個模型進行預測,最後將這些模型的結果
取平均,如下式,就可以得到變異較小較準確的結果。
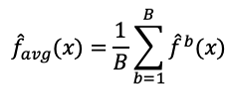
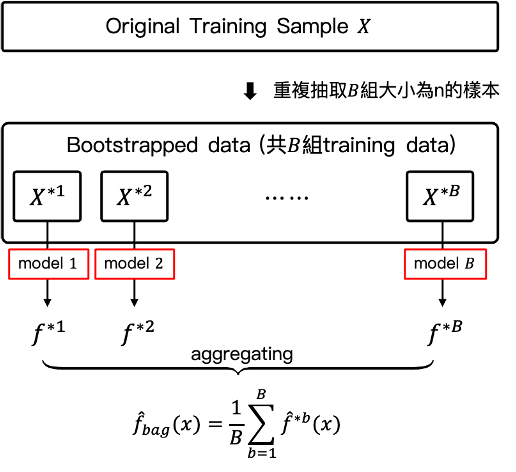
但現實是資料已經收集完畢,很難由母體中再取得更多的訓練集資料。因此藉由bootstrap的方法可以由原來的訓練集資料中重複抽樣生成B組訓練集資料,再由這B組訓練集資料分別建立模型,最後將各個模型的結果取平均來得到較準確的結果,迴歸的問題以平均的方式處理,而分類問題就以多數決投票的方式。例如運用在決策樹時就可以由這B組訓練集資料建構出B棵決策樹,最後再將B棵決策樹的結果整合。
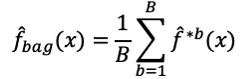
from sklearn.ensemble import BaggingClassifier
#選擇決策樹為基本分類器
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None)
bag = BaggingClassifier(base_estimator=tree, n_estimators=500, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False,n_jobs=1,random_state=1)
from sklearn.metrics import accuracy_score
bag = bag.fit(X_train,y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train,y_train_pred)
bag_test = accuracy_score(y_test,y_test_pred)
Boosting也是另一類用來改善預測結果的方法,可以運用於許多不論是分類或是迴歸問題的機器學習模型。Bagging是利用Bootstrap的方法額外生成B組訓練集資料後,各自針對這B組資料建立模型,最後再整合為一個結果。而Boosting雖然與Bagging相似,但不同的是Boosting不使用boostrap的抽樣,而是每一次都利用原始訓練集資料改變權重的修改版本依次建構模型,每一次建構的模型(通常利用較簡單的模型(weak classifier))都是吸取了上一次模型犯錯的資訊,也就是每一次都會專注於上一次錯誤的資料。根據損失函數(cost function)不同,常見Boosting的方法有AdaBoost(Adaptive Boosting)、L2Boosting、Gradient Boosting與LogitBoost。以AdaBoost處理分類問題為例(權重表示資料對模型的效果):
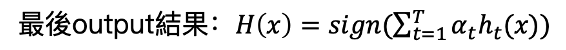
# AdaBoost
# 迴歸問題可以使用AdaBoostRegressor()
adb= AdaBoostClassifier()
adb.fit(X_train,y_train)
adb.predict(X_test)
adb.score(X_test,y_test)
# GradientBoost
gb=GradientBoostingClassifier()
gb.fit(X_train,y_train)
gb.predict(X_test)
gb.score(X_test,y_test)


 iThome鐵人賽
iThome鐵人賽