昨天的內容提到Bagging與Boosting改善預測結果的方法,不過在許多問題中Boosting常常表現得比Bagging更好,因此Boosting這類的方法更受歡迎。不過隨機森林(Random Forest)針對Bagging的方法有一些改善,使表現的與Boosting差不多好,且更容易訓練以及挑選其中的參數。
Bagging的基本概念是利用平均的方法來降低模型結果的變異,而決策樹是在Bagging中常用到的模型之一,因為決策樹更可以處理複雜的資料,若決策樹長得夠深夠大就能較低的偏差(bias),且利用Bagging就能得到更好的預測結果。雖然Bagging可以解決決策樹結果變異太大的問題,但並沒有解決偏差的問題(因為樣本平均值的期望值與原始資料的期望值相同,因此Bias的情況也會相同),因此唯一的希望是降低variance的部分。
昨天提到若有一筆來自相同分佈且互相獨立(i.i.d.)的資料,變異數為
。而樣本平均數
的變異數為
。但Bagging的方法由各個生成的資料集建構模型得到的預測結果之間常常不可能完全獨立(例如決策樹之間可能有結構相似的情況,就會有比較相似的預測結果),因此若資料之間有相關性時,樣本平均值的變異數會變成
,不論利用Bootstrap生成多少B個資料集,第一項仍然一直存在,因此會限制了Bagging的效果。 例如假設資料中有一個非常強的預測因子,以及許多其他中等強的預測因子。在Bagging建構的各個決策樹中,大多數或所有模型在最上方常常都是這些較有影響力的因子。因此,Bagging的結果許多看起來會非常相似,表示這些結果有些相關性存在。然而,隨機森林(Random Forest)就是想降低決策樹之間的相關性來改善Bagging的演算法。
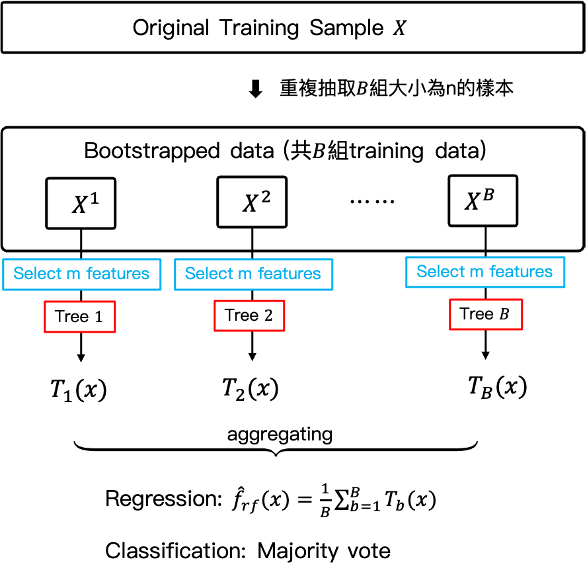
具體來說,隨機森林與Bagging一樣在利用Bootstrap的方法生成的訓練集資料上建立決策樹模型。不同之處在於隨機森林,只會隨機從p個解釋變數X中挑選m個解釋變數作為進行分割的候選名單來生成一個決策樹模型,(分類問題中通常選擇、迴歸問題選擇
),也就是說Bootstrap生成的B組訓練集資料,每個訓練資料集都由p個解釋變數挑選m個來建立決策樹模型。因此隨機森林演算法中會有兩個隨機,分別為Bootstrap隨機抽取原始資料生成多個訓練集資料,與隨機挑選m個變數來建構模型。
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
rand_clf = RandomForestClassifier()
rand_clf.fit(x_train, y_train)
rand_clf.score(x_test, y_test)
grid_param = {
"n_estimators": [90, 100, 115, 130],
"criterion": ["gini", "entropy"],
"max_depth": range(2, 20, 1),
"min_samples_leaf": range(1, 10, 1),
"min_sample_split": range(2, 10, 1),
"max_features": ["auto", "log2"]
}
grid_search = GridSearchCV(estimator = rand_clf,
param_grid = grid_param,
CV = 5,
n_job = -1,
verbose = 3)
grid_search.fit(x_train, y_train)
# 得到挑選參數的結果
grid_search.best_params_
# 以挑選的參數重新fit模型
rand_clf = RandomForestClassifier(
criterion = "entropy",
max_depth = 12,
max_features = log2,
min_samples_leaf = 1,
min_sample_split = 5,
n_estimators = 90)
rand_clf.fit(x_train, y_train)
rand_clf.score(x_test, y_test)


 iThome鐵人賽
iThome鐵人賽