如果我能看得更遠,那是因為站在巨人的肩膀上。
牛頓
經過了前幾天的旅程,相信大家對於運用在自然語言處理的神經網路,應該已經有了一定程度的認識。神經網路是深度學習的起點,我們一路從機器學習一直到現在的深度學習,其實都依循著一定的脈絡在往前走。不知道大家是否還記得我們在旅程一開始的時候曾經說過,為了要讓機器學習模型理解文字,首要工作是要將文字轉換成數字,因此發展出了許多如詞頻、TF-IDF等以詞為模型理解語言的最小單位的方式,接著以詞頻為基礎,將語言理解成具有統計概念的分布模型,因此這樣的模型被稱為語言模型,接著將這些轉成數值的文字資料放進傳統機器學習模型。後來,人工智慧學家發現,比起讓模型從詞彙的角度出發,讓模型可以理解文字、句子、甚至是文章上下文之間的連續關係,其實應用上可以更為廣泛。
就跟我們人有著不同專長一樣,不同的模型也擅長處理不同的資料。當模型處理具有序列關係的資料時,這種sequence model就是最好的選擇,也就是說,我們前幾天所說到的模型,RNN、LSTM、GRU等,都是sequence model的一種。
今天要介紹的,也是一種sequence model,稱為Transformer。今天這篇文將會有很大一部分是來自於 The Illustrated Transformer這篇文章,若各位想拜讀原文,可以毫不猶豫地點進去這篇文章喔!
如果我們將模型視作一個黑盒子,那首先要先釐清,輸入模型的資料型態會是一個句子,輸出也會是一個句子(畢竟是sequence model,輸入及輸出也會是 "sequence"),而在這個模型內部,是由一長串的編碼器(encoder)跟解碼器(decoder)所組成。我們可以參考以下示意圖:
![]()
在圖中我們可以看到,輸入及輸出之間是由一串的編碼器和解碼器所組成。雖然在原文中的圖也是用各六個編碼及解碼器,但事實上跟6這個數字一點關係都沒有。 畢竟不是每個人都是諫山創一樣對數字有執著
首先我們先來將注意力放在編碼器(Pun intended!),編碼器的構造又是由 自注意力機制(self-attention mechanism)以及一組前饋神經網路(feed-forward neural network) 所組成。另外在解碼器中,除了自注意力機制以及前饋神經網路之外,也多了編解碼注意力機制(encoder-decoder attention),前饋神經網路在我的 神經網路也會神機錯亂?不,只會精神錯亂...深度學習:前饋神經網路 這篇文章中已經提過,想必大家應該都很清楚了(吧?)(嗎?)所以今天會將主力放在解釋何謂自注意力機制。
![]()
自注意力機制的要點在於,深度學習模型可以判斷句子中某個字與句中其他字的關聯性大小,比如說,句中某個字的指涉對象是同一句中的哪個字。這樣說或許有點抽象,什麼指涉,什麼關聯性的吊書袋幹嘛?其實若用原文的舉例來說的話:
"The animal didn't cross the street because it was too tired."
在這句話中,it的指涉對象就是animal,也就是說,整句話之中,it跟animal的關係最接近,所以模型在進行自注意力機制的時候,就會給animal比較高的權重。這個運作方式就像是先前在圓圓圈圈圓圓~深度學習:循環神經網路 RNN之中所說,RNN透過隱藏層之間的資料傳遞(也就是RNN的記憶能力)來了解當前處理的字,與先前處理過的字,兩者之間的關係。
![]()
![]()
![]()
[0, 1]之間的數字。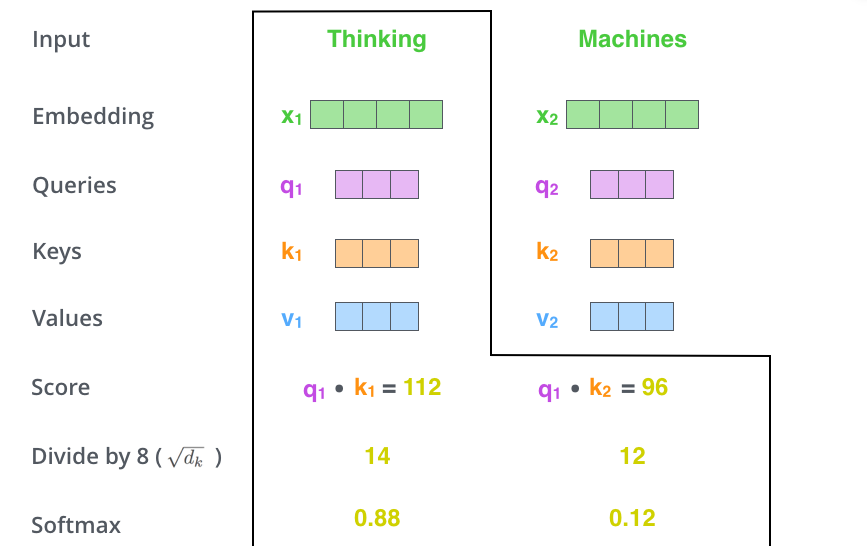

是不是已經腦洞大開了呢!但這還只是single-head attention,在原論文 Attention Is All You Need中其實又再針對這個概念進行了改良 套句高中數學老師說的,是想逼死誰? ,加入了multi-head attention,而這可以更準確地判斷句中不同位置的字的相對重要程度,不過我們明天再來詳細介紹是怎麼回事,還有後續的decoder的運作方式;另外,朋友們也可以想想看,為什麼在文中,我只要寫到「位置」,我都會特別加上引號。不過我們在這邊先休息一下,明天進入Transformer 下篇!

