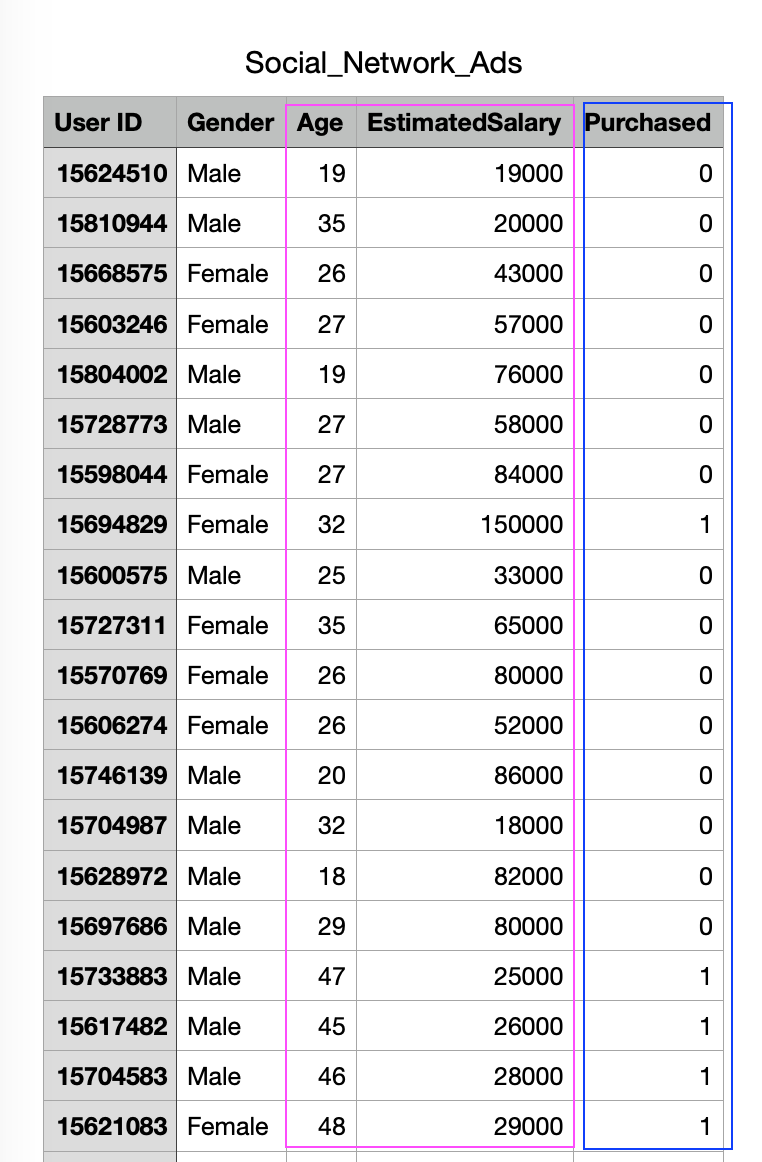
今天範例的資料是社交網路上使用者的基本數據
包含userID, 性別, 年齡, 預估薪資, 以及是否購買產品
假設有一家汽車公司出了一款新的SUV
且在社群媒體上投放了廣告, 並拿到了客戶資料表
他們現在想從這張資料中分析
哪些顧客對這台新推出的SUV 感興趣, 哪些不會
針對這張資料
自變量是column 2-3 (年齡, 預估薪資)
應變量是column4 (是否購買)
首先一樣需要對資料做前處理
依序步驟是
import numpy as py
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
x = dataset.iloc[:,[2,3]].values
y = dataset.iloc[:, 4].values
#Splitting the dataset into the Training set and Test set
# total 400, we choose 100 data for testing, 300 data for training
from sklearn.model_selection import train_test_split
x_train, x_test, y_test = train_test_split(x,y,test_size=0.25, random_state=0)
#Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test)
這一次不同於前面的範例
我們需要做特徵縮放
但是因為應變量Puchased 只有1 與 0 也就是“要”or “不要”
因此不需要做
只要對自變量做特徵縮放即可
做完特徵縮放的x_train, x_test 資料如下
可以看到資料的規模度已經差不多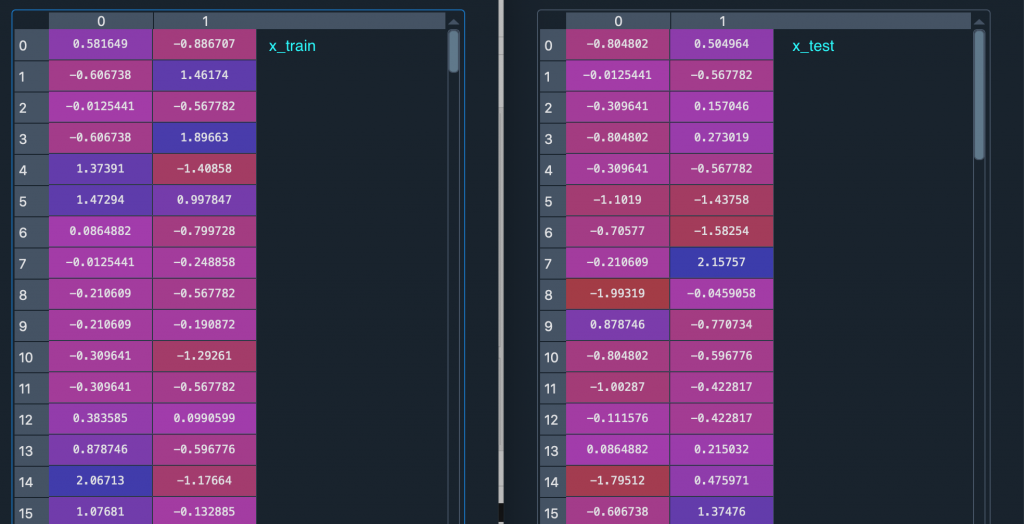
接著我們可以使用LogisticRegression Class
首先呼叫LogisticRegression(random_state)創建出分類器物件
# Fitting Logistic Regression to the Training set
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(x_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(x_test)


 iThome鐵人賽
iThome鐵人賽