昨天我們完成了和AI對話的功能。然而,由於GPT模型有Token數量的限制,我們無法將無窮無盡的歷史對話上下文訊息全部交給GPT模型處理。這時候,我們就需要借助Tokenizer來計算歷史對話的Token總數,並進行訊息的切割。今天就讓我們來嘗試計算Token吧!
在自然語言處理(NLP)領域中,Tokenizer的主要功能是將句子分解成稱為Tokens的更小片段。這一步驟對NLP任務至關重要,因為它讓電腦能夠將語言分解成可以理解和分析的小單位。有關Tokenizer的計算方式,可以參考HuggingFace的網站教學。此外,OpenAI官方還提供了一個線上計算工具,讓我們可以方便的測試Tokenizer。需要注意的是,Token的計算上GPT-3跟GPT-3.5和4的編碼方式都不太一樣哦!
GPT-3.5和GPT-4模型都有自己的最大Tokens數量限制。請參考以下圖片。
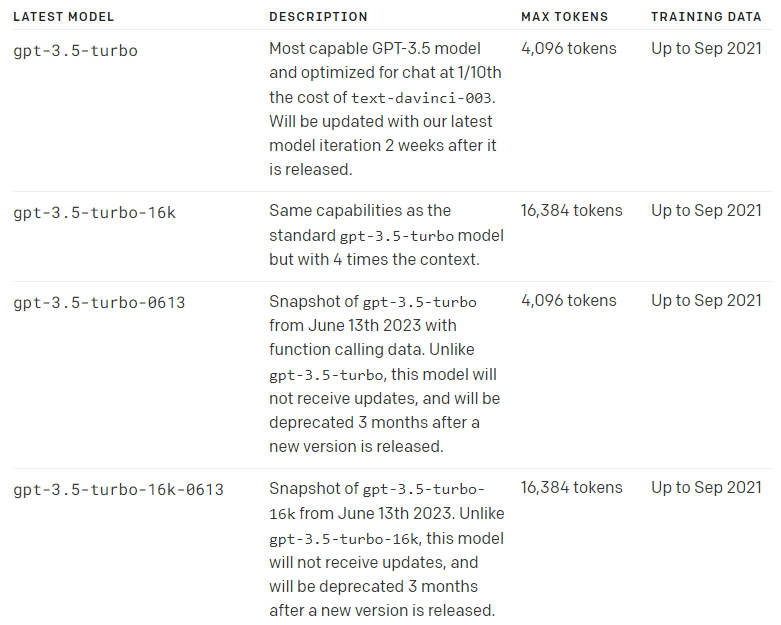
OpenAI官方提供了Python和JavaScript的tiktoken工具包,但似乎無法在Ionic上編譯。因此,我選擇使用另外一個基於tiktoken開發的第三方工具包進行安裝。透過以下指令來進行安裝:
npm install gpt-tokenizer
我們在OpenAI Service的openai.service.ts中匯入這個套件,並建立了一個tokenizerCalcuation()的方法。這個方法主要負責計算歷史對話上下文的Token數量。如果Token數量超過模型最大可處理的數量,我們將會移除較早的對話內容,同時保留系統的訊息:
import { encode } from 'gpt-tokenizer';
const SYSTEMPROMPT = '1.從現在開始你是英文口說導師,所有對話都使用英文。\
2.你的能力是和學生進行生活一對一會話練習,若學生有不會的單子或句子可以使用中文解釋。\
3.學生的程度大約落在多益(400-600)分,請你依照這個等級進行問話。\
4.進行會話練習時,儘可能的導正學生語法上的錯誤。\
5.你要適時地開啟新的日常話題。';
.
.
.
private chatMessages: ChatMessageModel[] = [
{
role: 'system',
content: SYSTEMPROMPT
},
];
.
.
.
private tokenizerCalcuation(): ChatMessageModel[] {
//最大大小取決於你選用的模型
const MAX_TOKENS = 8192;
let totalTokenizer = 0;
let newChatMessage: ChatMessageModel[] = [];
const systemPromptToken = encode(SYSTEMPROMPT).length;
totalTokenizer += systemPromptToken;
for (let i = this.chatMessages.length - 1; i >= 1; i--) {
const conversationPromptToken = encode(this.chatMessages[i].content).length;
if (totalTokenizer + conversationPromptToken > MAX_TOKENS) {
//如果下一個message超過Token限制,就結束添加
break;
} else {
totalTokenizer += conversationPromptToken;
newChatMessage.unshift(this.chatMessages[i]);
}
}
//保存第0筆資料
newChatMessage.unshift(this.chatMessages[0]);
console.log(newChatMessage);
console.log(`Token: ${totalTokenizer}`);
return newChatMessage;
}
我們在getConversationRequestData()方法內加入tokenizerCalcuation(),以便在每次發送API請求之前計算Token的數量,確保不會超過模型能處理的Token限制:
public chatAPI(contentData: string) {
//添加使用者訊息
this.addChatMessage('user', contentData);
return this.http.post<ChatResponseModel>('https://api.openai.com/v1/chat/completions', this.getConversationRequestData(), { headers: this.headers }).pipe(
//加入GPT回覆訊息
tap(chatAPIResult => this.addChatMessage('assistant', chatAPIResult.choices[0].message.content))
);
}
private getConversationRequestData(): ChatRequestModel {
return {
model: 'gpt-4',
messages: this.tokenizerCalcuation(), //Token計算
temperature: 0.7,
top_p: 1
}
}
完成後,我們在tokenizerCalcuation()方法中,使用console.log來觀察套件計算出的Token數量,並輸出GPT-4模型的完整回應。最終,套件計算的總Token數量為「199」,而GPT-4的回應則為「210」。這之間的差異可能是因為該套件已經有4個月沒有更新,導致其計算有些許誤差。
今天,我們為了處理Token數量超出限制的問題,而採取了這樣的策略:當歷史對話的Token數量超過限制時,我選擇保留最近的對話和系統訊息,並將較早期的訊息刪除。然而,這種方法缺點就是,如果與ChatGPT進行了很長時間的對話,並嘗試回顧之前的對話內容時,會因為舊的歷史對話被刪除,而導致ChatGPT無法回答,甚至是產生幻覺的情況發生哦!
Github專案程式碼:Ionic結合ChatGPT - Day15

