
在【Day - 14】我們完成了基本的聊天對話功能,然而,所有的回應都是以文字的形式呈現,於是我想透過Azure AI Service的語音服務,將文字轉成語音,進一步提升對話的真實感。今天,我們來探索Speech Service語音服務吧!
Speech Service語音服務是Azure平台的一部分,它提供了一系列與語音相關的服務。這些服務包含了語音識別、語音合成等實時及靈活的服務,這些服務可以應用於各類的服務和設備上。而我們將使用其中的文字轉語音服務,這項服務是由「深度神經網路」所驅動,並能提供相當逼真的語音輸出。加上語音合成標記語言(SSML)的幫助,我們甚至可以調整語音的各項細節,使輸出的語音更為真實。
另外可以到Speech Studio上測試微軟所提供的「語音資源庫」,上面有各種語音和說話風格試聽,還有各種使用案例可以參考。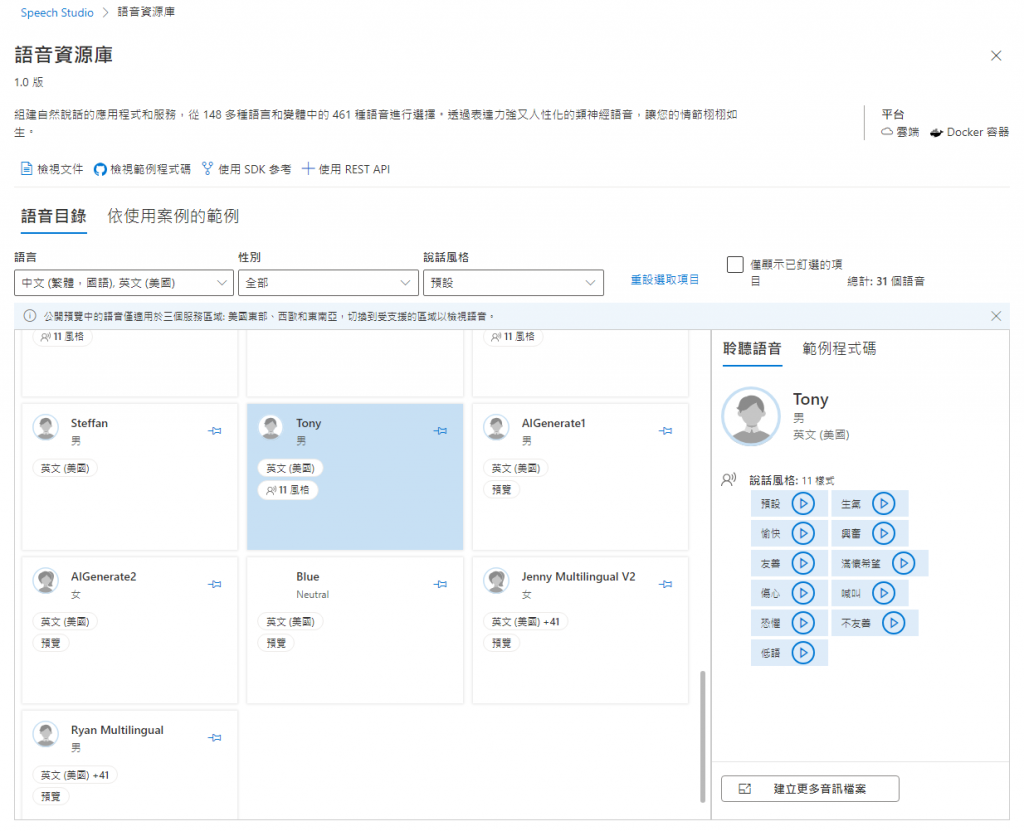
目前Azure的Speech Service語音服務定價有兩個:
關於標準的定價可以參考官網。
要使用文字轉語音前需要建立語音服務。我們可以使用Azure CLI指令來迅速建立一個Speech Service語音服務。由於「免費的定價層(F0)」提供神經文字轉換語音每個月50萬字元的額度,已經很足夠我使用,因此直接選擇免費即可。其餘的參數則可以參考微軟提供的官方文檔。
我們使用以下命令建置服務:
az cognitiveservices account create --kind SpeechServices --location "East Asia" --name <服務名稱> --resource-group <資源群組名稱> --sku F0
參數設定:
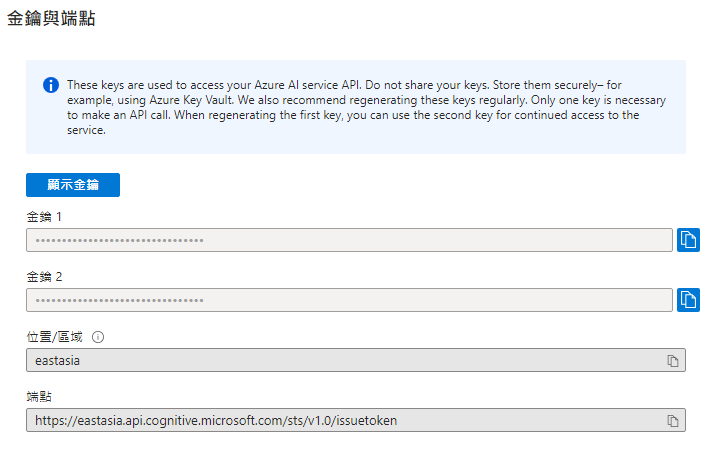
建立完成後,可以到Azure上確認該語音服務是否已經建立完成。接著,點擊服務進入後,在「概觀」的頁面中找到「金鑰」並記下來,我們等等會使用到。到這邊Speech Service語音服務就建立完成了。
設置完成Speech Service語音服務之後,我們使用Postman來測試這項服務。需要注意的是,API的請求網址會根據「服務的地區」而定,各個地區的URL可以在官方文檔中找到:
https://<你的服務所在地區>.tts.speech.microsoft.com/cognitiveservices/v1
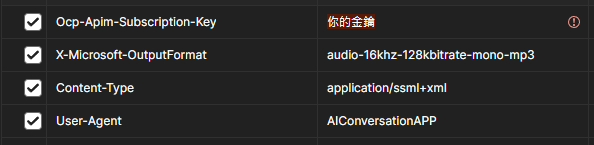
接著是請求Header的部分,我們需要添加以下四個欄位:
在請求的Body部分,我們需要提供相應的SSML範例。在這個例子中,我們選擇使用的語音是「en-US Tony」。這個可以根據需求或個人喜好自由更換:
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-TonyNeural">
Welcome to use Audio Content Creation to customize audio output for your products.
</voice>
</speak>
最後,在Postman的「Send」選項中下拉並選擇「Send and Download」,即可下載生成的語音檔案。就這樣,成功完成了一個快速而簡易的文字轉語音API測試!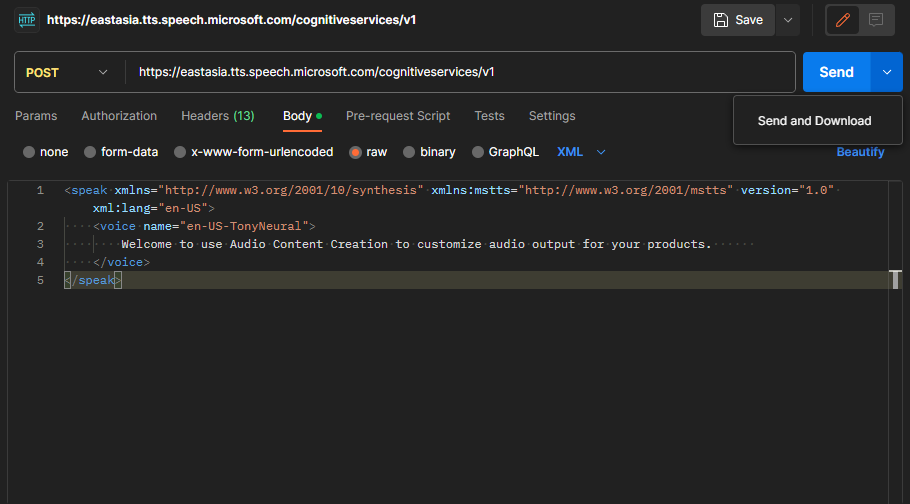
SSML(Speech Synthesis Markup Language)是由W3C(World Wide Web Consortium)標準化基於XML的標記語言,專門用於提升文字轉語音合成的質量。它提供豐富且可定制的調整方案,包括「語調」、「語速」、「音量」等細節,從而使文字轉語音在更多的場景下有更自然的表現。
接下來,我將介紹幾個基本的而且會使用到的基本SSML元素:
speak:speak元素是SSML中的根元素,也是必要的項目。它需要包括的資訊有「版本號」、「所使用的語言」,以及對「特定詞彙的標記定義」:
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US"></speak>
voice:voice元素在SSML中用來設定文字的語言,以及不同角色的聲音調性,例如:「男性或女性的聲音」、「聲音的粗細」和「高低」等。這也是一個必要元素,每個speak元素內至少要有一個voice元素:
<voice name="en-US-TonyNeural">
Hello! How are you?
</voice>
此外,speak元素內可以包含多個voice元素,這些voice元素可以一起使用,創造出類似兩個人在對話或是有聲書的效果。例如:
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-TonyNeural">
Hello there.
</voice>
<voice name="en-US-GuyNeural">
Hi, Nice to meet you.
</voice>
<voice name="en-US-TonyNeural">
Nice to meet you too.
</voice>
</speak>
mstts:express-as:是一個用於設定語音風格樣式的元素,它包含三個可以進行調整的屬性:
style:是一個調整語音說話風格的屬性,例如:「愉快」、「生氣」、「傷心」、「興奮」等等。每個voice可以搭配的style都可能不同,因此如果需要查詢具體的搭配,可以通過語音清單API或到Speech Studio上查看。
styledegree:這個屬性允許你調整說話風格的強度,可以針對不同的風格設定更強或更軟的語調,其範圍在0.01到2之間。
role:讓語音扮演特定角色,例如:「年輕男性」、「年輕女性」、「男孩」、「女孩」等。要注意的是,並不是每個語音都有這個角色扮演功能哦!
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-TonyNeural">
<mstts:express-as style="excited" styledegree="1.5">
Hello there! Nice to meet you!
</mstts:express-as>
<mstts:express-as style="friendly">
It's a beautiful day, isn't it?
</mstts:express-as>
</voice>
</speak>
emphasis:這個元素用於強調特定的語氣。通過提升某個詞語或片段的語調,可以使聽者感覺到該內容的重要性或強調。此元素可以放置在mstts:express-as元素下方。另外,需要注意的是,只有「en-US-GuyNeural」、「en-US-DavisNeural」和「en-US-JaneNeural」的語音支援強調功能。它只有一個屬性,用於設定強調的程度。
level:這是強調元素的屬性,用以設定強調的強度。可選的值包括「reduced」、「none」、「moderate」和「strong」,我們可以根據需求選擇不同的強調程度:
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-GuyNeural">
<mstts:express-as style="excited" styledegree="1">
Oh, that's fantastic! <emphasis level="moderate">Bon Jovi</emphasis> is a very popular band.
</mstts:express-as>
</voice>
</speak>
lang:當你需要在語音中混合多種語言時,可以使用特定的元素。這個元素必須置於voice元素的下方。需要注意,多語言功能通常只能在特定的語言角色中使用:
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-RyanMultilingualNeural">
<lang xml:lang="zh-TW">
突然好想你
</lang>
<lang xml:lang="en-US">
is a very touching song.
</lang>
</voice>
</speak>

網路上的文字轉語音服務琳瑯滿目,但我最終選擇了使用Azure AI Service來實現這個功能。Azure的優勢在於其快速的部署服務、豐富的語音庫,以及完整的SSML支援。這些特性不僅讓我們可以更方便快速的實現我們的需求,同時也為我們提供了更多的可能性來優化和定制服務哦!
Github專案程式碼:Ionic結合ChatGPT - Day16
