
在【Day - 17】中,我們成功讓GPT-4模型按照我們所指定的SSML格式生成文本。從第一天的鐵人賽開始,光是文字轉語音和語音轉文字的功能,就讓我耗費了許多天的時間呢 !而今天,我們即將完成整個語音對話功能的最後一塊拼圖:「串接語音服務」。
首先需要在Status Service上新增音訊播放狀態。我們在status.service.ts中,添加以下程式碼:
//讀取狀態
private isLoadingSubject$ = new BehaviorSubject<boolean>(false);
//音訊播放狀態
private playingStatusSubject$ = new BehaviorSubject<boolean>(false);
.
.
.
get isAudioPlaying$(): Observable<boolean> {
return this.playingStatusSubject$.asObservable();
}
.
.
.
接著,我們建立一個audioPlay()方法,該方法會回傳一個Observable,其目的是為了播放指定的音頻Blob,並監聽播放結束事件:
private audioPlay(audioFile: Blob) {
//創建一個新的observable來監聽音頻播放結束事件
return defer(() => {
return new Observable<boolean>(observer => {
//播放開始通知
observer.next(true);
//創建一個Blob URL
let url = URL.createObjectURL(audioFile);
//建立一個新的Audio物件並播放
let audio = new Audio(url);
audio.load();
audio.onended = () => {
//播放結束通知
observer.next(false);
//結束Observable
observer.complete();
};
audio.play();
});
});
}
然後我們還需要一個playAudio()的方法來提供外部播放音訊,此方法會直接訂閱並且播放音訊,同時,將播放狀態更新到playingStatusSubject$中:
public playAudio(audioFile: Blob) {
this.audioPlay(audioFile).subscribe(isPlaying => this.playingStatusSubject$.next(isPlaying));
}
我們建立一個Speech Service,在speech.service.ts檔案中並注入了HttpClient服務。此外,還需要設置一個HttpHeaders,並將【Day - 16】所介紹的標頭欄位帶入:
private headers = new HttpHeaders({
'Ocp-Apim-Subscription-Key': '{你的Speech Service語音服務金鑰}',
'X-Microsoft-OutputFormat': 'audio-16khz-128kbitrate-mono-mp3',
'Content-Type': 'application/ssml+xml',
'User-Agent': 'AIConversationAPP'
});
constructor(private http: HttpClient) { }
接著,再建立了一個textToSpeech()的方法。由於speak和voice元素是固定不變的部分,所以我們可以直接寫死在這個方法裡面。另外,在使用POST方式呼叫API時,需要添加一個參數,即responseType = blob,這樣做是為了告知後續資料流為一個檔案:
public textToSpeech(text: string) {
const textData = `<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" version="1.0" xml:lang="en-US">
<voice name="en-US-GuyNeural">
${text}
</voice>
</speak>`;
return this.http.post('https://<你的服務所在地區>.tts.speech.microsoft.com/cognitiveservices/v1', textData, {
headers: this.headers,
responseType: 'blob'
});
}
最後,我們將textToSpeech()加入到OnGetRecordingBase64Text()中,承接chatAPI()回傳的內容。並在subscribe中播放下載的音訊:
constructor(private http: HttpClient,
private statusService: StatusService,
private openaiService: OpenaiService,
private speechService: SpeechService) { }
OnGetRecordingBase64Text(recordingBase64Data: RecordingData) {
const requestData: AudioConvertRequestModel = {
aacBase64Data: recordingBase64Data.value.recordDataBase64
};
//啟動讀取
this.statusService.startLoading();
//Audio Convert API
this.http.post<AudioConvertResponseModel>('你的Web APP URL/AudioConvert/aac2m4a', requestData).pipe(
//Whisper API
switchMap(audioAPIResult => this.openaiService.whisperAPI(audioAPIResult.m4aBase64Data)),
//Chat API
switchMap(whisperAPIResult => this.openaiService.chatAPI(whisperAPIResult.text)),
//Speech Service API
switchMap(chatResult=> this.speechService.textToSpeech(chatResult.choices[0].message.content)),
finalize(() => {
//停止讀取
this.statusService.stopLoading();
})
).subscribe(audioFileResult => this.statusService.playAudio(audioFileResult));
}
當我在實體機上進行測試時,發現了一個重大問題,那就是「回應速度」。無論是否生成SSML格式,只要字數增多,回應時間就會顯著拉長。使用Postman進行測試時,回應時間甚至有等待19秒之久。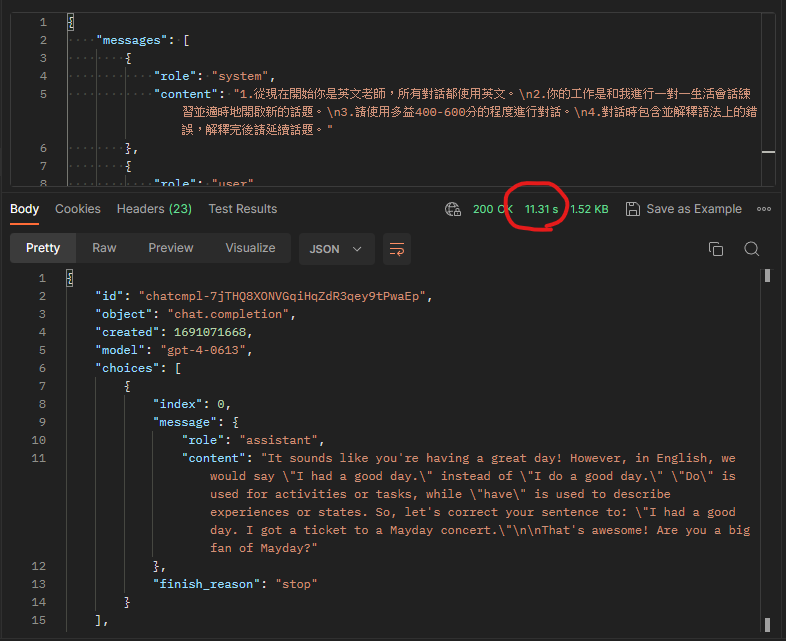
另一個問題是輸出轉換成了SSML格式。當儲存歷史對話時,SSML也被記錄在其中,導致歷史對話字數的增加,消耗了更多不必要的Token數量。這不僅可能增加成本,還可能影響API的效率和回應速度,尤其考慮到GPT-4模型本身的回應速度就已經相對較慢了。
解決速度的問題,我們可以改用GPT-3.5模型,但它很容易忽略某些提示,例如:「對話時儘可能的指正學生語法或口語上的錯誤」、「輸出的回應只能使用SSML格式。不必包含speak和voice元素」,以及「根據你的推論添加與語境相對應的語氣和語調」等。
由下圖可以發現,GPT-4模型可以正常輸出SSML。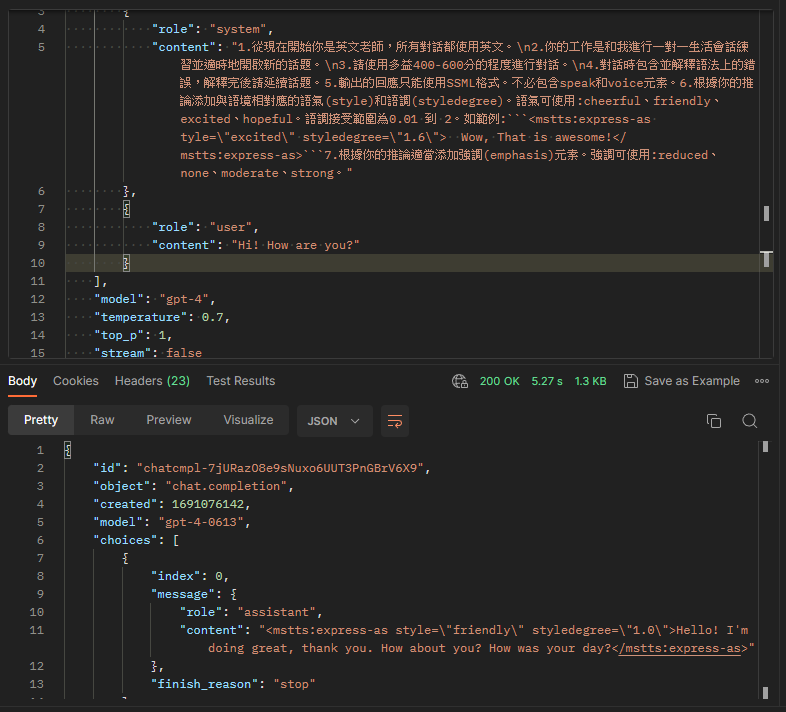
而在GPT-3.5模型中,它完全忽略了提示,導致輸出並未包括SSML格式,或者忽略了應該指出的語法錯誤。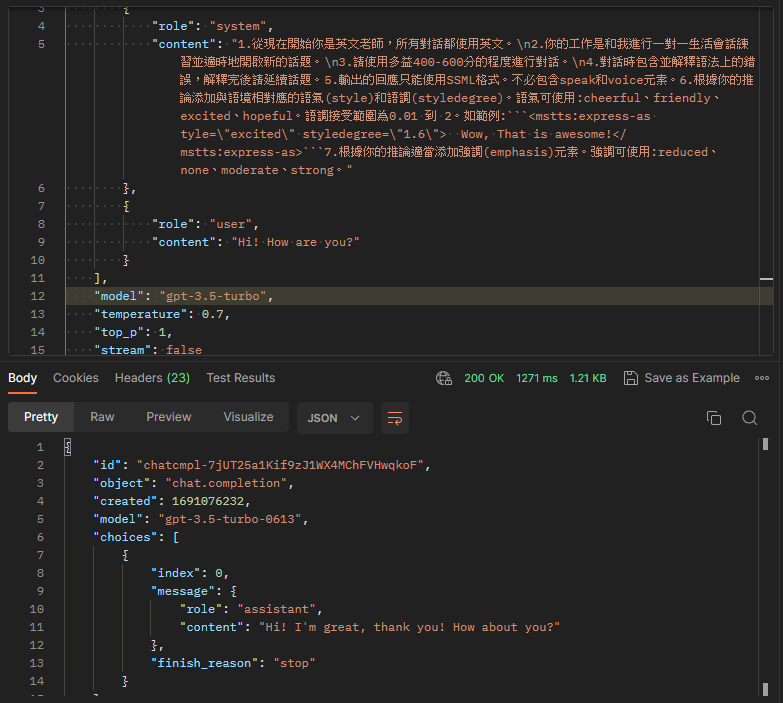
今天我們完成了語音功能,不僅為APP增添了生動有趣的元素,也讓使用者享受到更自然、更真實的對話體驗。雖然語音聊天功能已經完成,但GPT-4模型的回應速度緩慢確實可能影響使用者的體驗。因此,我希望可以解決速度這個問題,並在速度和功能上兼顧,為使用者帶來更完善的體驗。
Github專案程式碼:Ionic結合ChatGPT - Day18
