昨天帶各位實作了CGAN,這是基於條件式的生成對抗網路。今天要來介紹的是在2016年底提出的Pix2Pix模型,他雖然名字裡面沒有GAN,但模型架構卻也包含生成器與判別器。這個模型被提出時是以Image-to-Image為主的應用,也就是圖像翻譯類型的應用,今天就要來介紹一下這個模型的細節。
Pix2Pix是基於CGAN的圖像翻譯模型,但是它與CGAN不同的是此模型是直接以圖片作為輸入,並生成另外一張圖片,其資料集為一對一,也就是說一張圖片只會對應到另一張特定的圖片,基本上是屬於風格轉換的類型。根據原始論文,Pix2Pix可以做到草圖轉成街景圖以及建築圖、黑白圖轉彩色圖、衛星圖轉地圖、白天變晚上、線條轉成高清圖片,也可以用來做圖像修復等內容。
這個模型的資料集圖片必須要有一對一的對照關係。而另一個有名的風個變換CycleGAN則不強制資料集圖片需要有一對一的對照關係。
那究竟是甚麼魔法讓Pix2Pix可以做到那麼多事情呢?且聽我娓娓道來。
生成器與判別器的工作內容:生成器在做的事情是使用一張輸入圖片,根據要進行的任務輸入,例如圖像修復就輸入被毀損的圖片,最後會生成出一張生成圖片,也就是修復後的圖片;而判別器要輸入生成圖片與資料集中對應到修復好的圖片兩個圖片,這麼做的用意是要得知這張生成圖片是不是透過被毀損的圖片生成的,以及生成圖片與被修復好的圖片的差距。
模型架構—生成器:根據原始論文,這個模型在生成器中使用了U-Net結構,這個結構與自動編碼器很像,但是在對應的下採樣與上採樣層會建立跳接 (Skip Connection),這使得梯度比較好傳遞,也比較不容易發生梯度消失的情況。因為使用U-Net時通常神經網路會比較深,深度的神經網路就容易發生梯度消失,所以才需要使用跳接 (可以參考原始論文3.2.1章節)。下採樣與對應的上採樣層連接也可以更好的對應到卷積過後的特徵,對於細節的生成非常有幫助!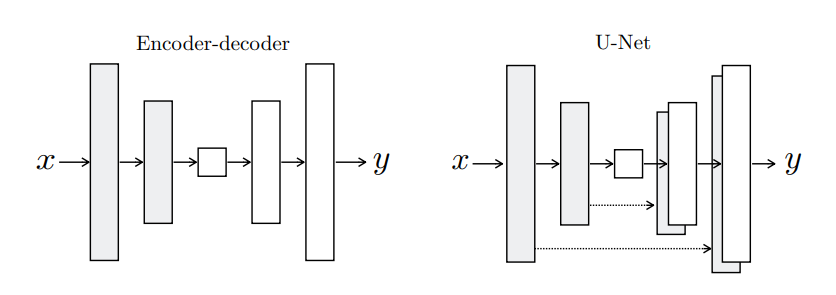
模型架構—判別器:這個部分根據論文3.2.2章節,本模型的判別器使用Markovian Discriminator (PatchGAN)的架構,與傳統判別器不同的部分是:傳統判別器是直接判斷一整張圖是真是假;但這個方法是將圖片切成很多塊,每塊都是N*N的大小,判別器會判斷每個區塊的真假,最後再來統整計算整張圖片的真假。
使用這個方法對於計算資源的消耗也比較少,訓練速度會增加。
損失函數:這篇論文的作者認為將GAN的目標函數與損失函數結合的話,生成圖片的品質會更好,所以生成器在訓練時除了使用鑑別器的意見來學習以外,還會使用自己生成的圖片與真實的圖片逐個像素對比,看看生成的圖片是不是與真實圖片相近,論文中使用L1損失,原因是因為根據他們的實驗,使用L1損失生成的圖片會比使用L2損失還要來的清楚,L2損失會比較模糊。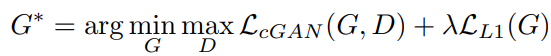
上述公式就是生成器損失,前項落落長的就是傳統GAN的判別器損失,後項就是生成器自己評估自己生成圖片與原圖有多像,使用L1損失評估, 為超參數,可以根據情況人為設定。圖源為原始論文方程式(4)。
L1損失與L2損失:L1損失也就是最小化MAE,也稱為LAE;L2損失也就是最小化MSE,也稱為LSE。基本上與MAE、MSE是幾乎相同的計算方式。L1與L2的比較如下表:
| L1 (MAE) | L2 (MSE) | |
|---|---|---|
| 穩定度 | 較高 | 較低 |
| 解的穩定度 | 沒有穩定的解 | 有穩定的解 |
| 解的數量 | 可能有多組解 | 只有一組解 |
也可以由表得知使用L1損失的穩定度較高,故也有可能是成果比較好的原因之一,具體原因似乎沒在論文中看到詳細的敘述。
Pix2Pix改動了許多不同的東西,與傳統GAN或者其基礎CGAN都有一些差異,這裡就簡單的概括整理一下差異:
今天介紹的Pix2Pix是CGAN的延伸,它可以達成許多影像處理的任務,其中的思路也很新奇,在做生成式AI好玩的點就在這裡,對模型有些小改動或者引入某些架構都能使結果產生變動 (雖然不一定每次都會成功)。明天會帶各位實際使用Pix2Pix去做mnist的圖像修復任務,希望能夠讓各位明白Pix2Pix的運作原理。

