今天要來介紹CGAN的實作部分,CGAN與之前的GANs其最大差異就是可以控制生成內容,這邊先給各位看看在訓練完成後,指定CGAN生成全部都是3的圖片,可以看得出來圖片生成真的會根據條件生出指定的圖片,非常神奇。接著就來看看其中的門道以及如何實現吧!
CGAN模型只有要注意生成器與判別器都需要加入條件輸入才可以,其他部分則與DCGAN無異。
這部分一樣我們使用DCGAN來加上條件控制以改造成CGAN,任務類型是使用指定數字輸入接著生成對應的mnist手寫數字圖片。
這部分與之前介紹的GAN並沒有差異,一樣是這些老朋友。另外因為要做條件嵌入,所以會使用Embedding與multiply層,前者是嵌入層,能把輸入變成指定長度的向量;後者是可以將條件向量與輸入雜訊相乘,變成一個總輸入,這個總輸入除了雜訊以外也有條件嵌入,模型需要根據條件嵌入的分布來學習如何生成指定的圖片。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, BatchNormalization, LeakyReLU, Activation, Conv2DTranspose, Conv2D, Embedding, multiply
from tensorflow.keras.models import Model, save_model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import os
這部分要注意因為有條件輸入,所以數字的標籤資料也會被使用到!y_train在之前的手寫數字分類任務就是用於標註每張圖片所屬的類別,在CGAN當中也變成了訓練要輸入的資料了。
def load_data(self):
(x_train, y_train), (_, _) = mnist.load_data() # 底線是未被用到的資料,可忽略
x_train = (x_train / 127.5)-1 # 正規化
x_train = x_train.reshape((-1, 28, 28, 1))
return x_train, y_train #注意標籤資料也會被使用到
這部分也與DCGAN幾乎沒有差別,不過這邊設定了一個self.label,這是我想要在一定epoch後生成指定的圖片,每次生成圖片所指定的條件要一模一樣。這麼做的原因是可以比較好看出訓練過程中的變化。
class CGAN():
def __init__(self, generator_lr, discriminator_lr):
self.generator_lr = generator_lr
self.discriminator_lr = discriminator_lr
self.discriminator = self.build_discriminator()
self.generator = self.build_generator()
self.adversarial = self.build_adversarialmodel()
# 指定生成的標籤,這樣比較好觀察訓練變化
self.label = np.random.randint(size=25, low=0, high=10)
self.gloss = []
self.dloss = []
if not os.path.exists('./result/CGAN/imgs'):# 將訓練過程產生的圖片儲存起來
os.makedirs('./result/CGAN/imgs')# 如果忘記新增資料夾可以用這個方式建立
接著這邊就有一些不同了,另外定義嵌入層會使模型變成多輸入模型,此時必須使用Functional API來建立。生成器、判別器、對抗模型都會受到影響,其他例如損失函數的地方都不會有變動。另外訓練時也要記得將標籤資料輸入至模型中。
生成器:生成器多了幾個層,第一個是嵌入層Embedding,參數設定是類別數量與嵌入後的向量長度,分別為10 (數字由0到9共有10個類別)與100 (與雜訊輸入向量一樣)。接著使用Flatten()將嵌入向量展平成1維的,接著再使用multiply()將兩個輸入相乘合併成一個輸入。
def build_generator(self):
noise_input = Input(shape=(100, ))
label_input = Input(shape=(1, ), dtype=np.int32) #條件輸入層
label_embedding = Flatten()(Embedding(10, 100)(label_input)) #10代表有10個類別
input_ = multiply([noise_input,label_embedding]) #將編碼過後的挑見輸入與雜訊合併
x = Dense(7*7*32)(input_)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Reshape((7, 7, 32))(x)
x = Conv2DTranspose(128, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Conv2DTranspose(256, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
out = Conv2DTranspose(1, kernel_size=1, strides=1, padding='same', activation='tanh')(x)
model = Model(inputs=[noise_input, label_input], outputs=out, name='Generator')
model.summary()
return model
判別器:判別器也是要改變輸入內容,變成一個雜訊輸入與條件輸入。條件嵌入的細節與生成器一樣!
def build_discriminator(self):
image_input = Input(shape = (28, 28, 1))
label_input = Input(shape=(1, ), dtype=np.int32)
label_embedding = Flatten()(Embedding(10, 28*28)(label_input)) #10代表有10個類別
input_ = multiply([image_input, label_embedding])
x = Conv2D(256, kernel_size=2, strides=2, padding='same')(input_)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(128, kernel_size=2, strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(64, kernel_size=2, strides=1, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Flatten()(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(inputs=[image_input, label_input], outputs=out, name='Discriminator')
dis_optimizer = Adam(learning_rate=self.discriminator_lr , beta_1=0.5)
model.compile(loss='binary_crossentropy',
optimizer=dis_optimizer,
metrics=['accuracy'])
model.summary()
return model
對抗模型:這個部分也是一樣,要為裡面的生成器與判別器都添加條件輸入。生成器要根據條件生成對應圖片;而判別器除了判斷圖片是真是假以外,還要判斷圖片是否有照著條件生成。
def build_adversarialmodel(self):
# 修改輸入層的部分,添加條件輸入
noise_input = Input(shape=(100, ))
label_input = Input(shape=(1, ), dtype=np.int32)
generator_sample = self.generator([noise_input, label_input])
self.discriminator.trainable = False
out = self.discriminator([generator_sample, label_input])
model = Model(inputs=[noise_input, label_input], outputs=out)
adv_optimizer = Adam(learning_rate=self.generator_lr, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=adv_optimizer)
model.summary()
return model
**訓練步驟:**訓練中要注意要使用到標籤資料,並且在生成器與判別器訓練時使用。real_label = y_train[idx]這裡是使用到對應圖片的條件輸入。接著在訓練時也要輸入標籤,多輸入的模型都要使用List的格式例如[input1, input2, …]來做資料的輸入,例如生成假圖片就是生成器要predict([noise, real_label]),訓練時也是把資料以List格式整理起來並輸入。
def train(self, epochs, batch_size=128, sample_interval=50):
# 準備訓練資料
x_train, y_train = self.load_data()
# 準備訓練的標籤,分為真實標籤與假標籤
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 隨機取一批次的資料用來訓練
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train[idx]
# 記得條件輸入的部分!
real_label = y_train[idx]
# 從常態分佈中採樣一段雜訊
noise = np.random.normal(0, 1, (batch_size, 100))
# 生成一批假圖片
gen_imgs = self.generator.predict([noise, real_label])
# 判別器訓練判斷真假圖片
d_loss_real = self.discriminator.train_on_batch([imgs, real_label], valid)
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, real_label], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#儲存鑑別器損失變化 索引值0為損失 索引值1為準確率
self.dloss.append(d_loss[0])
# 訓練生成器的生成能力
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = self.adversarial.train_on_batch([noise, real_label], valid)
# 儲存生成器損失變化
self.gloss.append(g_loss)
# 將這一步的訓練資訊print出來
print(f"Epoch:{epoch} [D loss: {d_loss[0]}, acc: {100 * d_loss[1]:.2f}] [G loss: {g_loss}]")
# 在指定的訓練次數中,隨機生成圖片,將訓練過程的圖片儲存起來
if epoch % sample_interval == 0:
self.sample(epoch,label=self.label)
self.save_data()
儲存資料的部分是沒有變,但生成圖片為了美觀有稍微增加一些東西。
def save_data(self):
np.save(file='./result/CGAN/generator_loss.npy',arr=np.array(self.gloss))
np.save(file='./result/CGAN/discriminator_loss.npy', arr=np.array(self.dloss))
save_model(model=self.generator,filepath='./result/CGAN/Generator.h5')
save_model(model=self.discriminator,filepath='./result/CGAN/Discriminator.h5')
save_model(model=self.adversarial,filepath='./result/CGAN/Adversarial.h5')
生成圖片的部分如下,在訓練時可能不需要特別指定條件,不過在最後使用模型生成時也可以指定模型要生成甚麼。另外就是每一張生成的圖片上面都會對應到該張圖片的標籤,添加上標籤的部分可以使用axs[i, j].set_title(label[r*i+j], pad=2, fontsize=8)來指定,set_title代表為每一個子圖設定其標題 (label[r*i+j]),pad參數代表與該子圖片的距離,fontsize參數代表設定字體大小,如果生成內容中的文字有跑掉的話可以改變這兩個參數來設定。
def sample(self, epoch=None, num_images=25, save=True, label=None):
r = int(np.sqrt(num_images))
noise = np.random.normal(0, 1, (num_images, 100))
# 條件輸入設定,如果沒有特別指定則隨機生成條件
if label.all() == None:
label = np.random.randint(size=num_images, low=0, high=10)
gen_imgs = self.generator.predict([noise, label])
gen_imgs = (gen_imgs+1)/2
fig, axs = plt.subplots(r, r)
count = 0
for i in range(r):
for j in range(r):
axs[i, j].set_title(label[r*i+j], pad=2, fontsize=8) #顯示該張圖片對應的條件
axs[i, j].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[i, j].axis('off')
count += 1
if save:
fig.savefig(f"./result/CGAN/imgs/{epoch}epochs.png")
else:
plt.show()
plt.close()
這個部分也沒有甚麼變化,只是在輸出時指定生成圖片都要是”3”,比較好看出CGAN到底有沒有乖乖聽話生成一批都是3的圖片。各位也可以試試看其他數字喔!
| 參數 | 參數值 |
|---|---|
| 生成器學習率 | 0.0002 |
| 判別器學習率 | 0.0002 |
| Batch Size | 128 |
| 訓練次數 | 20000 |
if __name__ == '__main__':
gan = CGAN(generator_lr=0.0002,discriminator_lr=0.0002)
gan.train(epochs=20000, batch_size=128, sample_interval=200)
label = np.array([3 for _ in range(25)])
gan.sample(save=False, label=label)
還是先來看看損失,還蠻漂亮的XD,但是也是無法根據損失看出圖片的質量,各位也可以嘗試把WGAN與CGAN結合看看喔,這樣可以更明確的看出生成器模型訓練的狀態。雖然生成器損失不斷提高,但圖片品質卻好像沒有甚麼退步的跡象。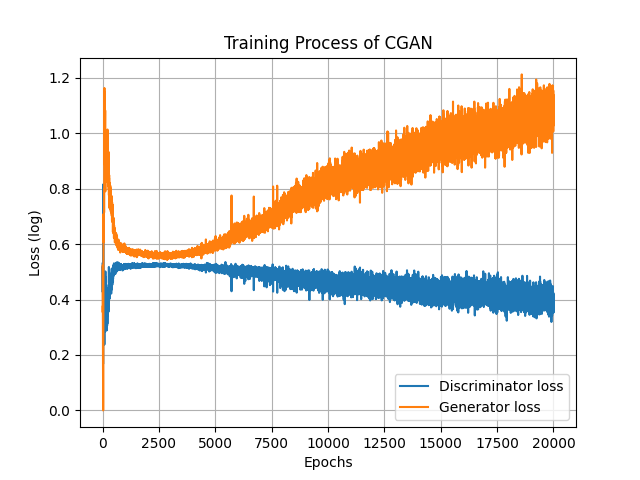
也可以看到訓練過程中,圖片是否有好好的依照條件生成。
Epoch=200
Epoch=2000
Epoch=5000
Epoch=10000
Epoch=20000
總得來說偶爾還是會生成低質量圖片,甚至偶爾會生錯條件XD。原因有可能是因為生成器與判別器對抗式的訓練,在當下epoch訓練時判別器佔上風,導致生成器能力可能變弱。不過整體來說都還算可以。最後也是要放上訓練過程中生成圖片的變化。
今天實作了CGAN,不知道各位有沒有對條件生成此類的模型產生興趣,如果有興趣的話可以在研究看看更多條件生成的模型。明天會介紹的模型是基於CGAN的Pix2Pix,這個模型能做到的事情也很多,詳細細節明天再來介紹吧!
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, BatchNormalization, LeakyReLU, Activation, Conv2DTranspose, Conv2D, Embedding, multiply
from tensorflow.keras.models import Model, save_model
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import os
class CGAN():
def __init__(self, generator_lr, discriminator_lr):
self.generator_lr = generator_lr
self.discriminator_lr = discriminator_lr
self.discriminator = self.build_discriminator()
self.generator = self.build_generator()
self.adversarial = self.build_adversarialmodel()
self.gloss = []
self.dloss = []
if not os.path.exists('./result/CGAN/imgs'):# 將訓練過程產生的圖片儲存起來
os.makedirs('./result/CGAN/imgs')# 如果忘記新增資料夾可以用這個方式建立
def load_data(self):
(x_train, y_train), (_, _) = mnist.load_data() # 底線是未被用到的資料,可忽略
x_train = (x_train / 127.5)-1 # 正規化
x_train = x_train.reshape((-1, 28, 28, 1))
return x_train, y_train
def build_generator(self):
noise_input = Input(shape=(100, ))
label_input = Input(shape=(1, ), dtype=np.int32) #條件輸入層
label_embedding = Flatten()(Embedding(10, 100)(label_input)) #10代表有10個類別
input_ = multiply([noise_input,label_embedding]) #將編碼過後的挑見輸入與雜訊合併
x = Dense(7*7*32)(input_)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Reshape((7, 7, 32))(x)
x = Conv2DTranspose(128, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
x = Conv2DTranspose(256, kernel_size=2, strides=2, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization(momentum=0.8)(x)
out = Conv2DTranspose(1, kernel_size=1, strides=1, padding='same', activation='tanh')(x)
model = Model(inputs=[noise_input, label_input], outputs=out, name='Generator')
model.summary()
return model
def build_discriminator(self):
image_input = Input(shape = (28, 28, 1))
label_input = Input(shape=(1, ), dtype=np.int32)
label_embedding = Flatten()(Embedding(10, 28*28)(label_input)) #10代表有10個類別
input_ = multiply([image_input, label_embedding])
x = Conv2D(256, kernel_size=2, strides=2, padding='same')(input_)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(128, kernel_size=2, strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(64, kernel_size=2, strides=1, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Flatten()(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(inputs=[image_input, label_input], outputs=out, name='Discriminator')
dis_optimizer = Adam(learning_rate=self.discriminator_lr , beta_1=0.5)
model.compile(loss='binary_crossentropy',
optimizer=dis_optimizer,
metrics=['accuracy'])
model.summary()
return model
def build_adversarialmodel(self):
# 修改輸入層的部分,添加條件輸入
noise_input = Input(shape=(100, ))
label_input = Input(shape=(1, ), dtype=np.int32)
generator_sample = self.generator([noise_input, label_input])
self.discriminator.trainable = False
out = self.discriminator([generator_sample, label_input])
model = Model(inputs=[noise_input, label_input], outputs=out)
adv_optimizer = Adam(learning_rate=self.generator_lr, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=adv_optimizer)
model.summary()
return model
def train(self, epochs, batch_size=128, sample_interval=50):
# 準備訓練資料
x_train, y_train = self.load_data()
# 準備訓練的標籤,分為真實標籤與假標籤
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 隨機取一批次的資料用來訓練
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train[idx]
# 記得條件輸入的部分!
real_label = y_train[idx]
# 從常態分佈中採樣一段雜訊
noise = np.random.normal(0, 1, (batch_size, 100))
# 生成一批假圖片
gen_imgs = self.generator.predict([noise, real_label])
# 判別器訓練判斷真假圖片
d_loss_real = self.discriminator.train_on_batch([imgs, real_label], valid)
d_loss_fake = self.discriminator.train_on_batch([gen_imgs, real_label], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#儲存鑑別器損失變化 索引值0為損失 索引值1為準確率
self.dloss.append(d_loss[0])
# 訓練生成器的生成能力
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = self.adversarial.train_on_batch([noise, real_label], valid)
# 儲存生成器損失變化
self.gloss.append(g_loss)
# 將這一步的訓練資訊print出來
print(f"Epoch:{epoch} [D loss: {d_loss[0]}, acc: {100 * d_loss[1]:.2f}] [G loss: {g_loss}]")
# 在指定的訓練次數中,隨機生成圖片,將訓練過程的圖片儲存起來
if epoch % sample_interval == 0:
self.sample(epoch)
self.save_data()
def save_data(self):
np.save(file='./result/CGAN/generator_loss.npy',arr=np.array(self.gloss))
np.save(file='./result/CGAN/discriminator_loss.npy', arr=np.array(self.dloss))
save_model(model=self.generator,filepath='./result/CGAN/Generator.h5')
save_model(model=self.discriminator,filepath='./result/CGAN/Discriminator.h5')
save_model(model=self.adversarial,filepath='./result/CGAN/Adversarial.h5')
def sample(self, epoch=None, num_images=25, save=True, label=None):
r = int(np.sqrt(num_images))
noise = np.random.normal(0, 1, (num_images, 100))
# 條件輸入設定,如果沒有特別指定則隨機生成條件
if label == None:
label = np.random.randint(size=num_images, low=0, high=10)
else:
label = np.array([label for _ in range(num_images)],dtype=np.int32)
gen_imgs = self.generator.predict([noise, label])
gen_imgs = (gen_imgs+1)/2
fig, axs = plt.subplots(r, r)
count = 0
for i in range(r):
for j in range(r):
axs[i, j].set_title(label[r*i+j], pad=2, fontsize=8) #顯示該張圖片對應的條件
axs[i, j].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[i, j].axis('off')
count += 1
if save:
fig.savefig(f"./result/CGAN/imgs/{epoch}epochs.png")
else:
plt.show()
plt.close()
if __name__ == '__main__':
gan = CGAN(generator_lr=0.0002,discriminator_lr=0.0002)
gan.train(epochs=20000, batch_size=128, sample_interval=200)
gan.sample(save=False, label=3)

